版权声明:转载请标明出处。 https://blog.csdn.net/u010720408/article/details/90766857
调用awk类似sed
(目前的linux 都是用的gawk,两者现在互相等同了。)
awk中的执行语句,类似C/C++
awk调用三种方式
①在shell命令输入
awk [-F 域分隔符] 'awk 程序段' 输入文件
②awk程序段插入脚本文件,然后通过awk命令调用它
awk -f awk脚本文件 输入文件
#通过-f 调用awk脚本文件
③将awk命令插入脚本文件后,设为可执行,然后执行脚本文件
./awk脚本文件 输入文件
1. awk模式匹配
awk 由 pattern 和 action组成;
pattern模式选择输入行是否执行后续action动作;
action动作可以是包含语句、函数、表达式的执行过程;
awk的pattern支持的正则表示大元字符要比grep、sed广;
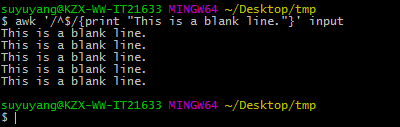
#打印空行
awk '/^$/{print "This is a blank line."}' input
2. awk 记录和域
awk人为输入文件是结构化的,awk将每个输入文件行 定义为记录;
行中每个字符串定义为域,域之间用空格、Tab键或其他符号进行分割;
多个连续空格、多个连续Tab间等当做一个分割域符号处理;
awk 使用 $指定执行的域, $ 后面数字代表取第几个域,下标从1开始,$1取得第一个域的值;
$0代表所有的域;
3. awk 系统变量
| 变量名 | 意义 |
|---|---|
| $n | 取第n个域的值 |
| $0 | 取所有域,即整行 |
| ARGC | 命令行参数的数量 |
| ARGIND | 命令行中当前文件的位置(从0开始标号) |
| ARGV | 命令行参数的数组 |
| CONVFMT | 数字转换格式 |
| ENVIRON | 环境变量关联数组 |
| ERRNO | 最后一个系统错误的描述 |
| FIELDWIDTHS | 字段宽度列表,以空格键分割 |
| FILENAME | 当前文件名 |
| FNR | 浏览文件的记录数 |
| FS | 字段分隔符,默认是空格键 |
| IGNORECASE | 布尔变量,如果为真,则进行忽略大小写匹配 |
| NF | 当前记录中的域数量 |
| NR | 当前记录数 |
| OFMT | 数字的输出格式 |
| OFS | 输出域分隔符,默认是空格键 |
| ORS | 输出记录分隔符,默认是换行符 |
| RLENGTH | 由match函数所匹配的字符串长度 |
| RS | 记录分割符,默认是行换符 |
| RSTART | 由match函数所匹配的字符串的低于公车位置 |
| SUBSEP | 数组下标分隔符,默认值是\034 |
4. awk 格式化输出
printf (格式控制符,参数)
修饰符:
| 修饰符 | 意义 |
|---|---|
| - | 左对齐 |
| width | 域的步长 |
| .prec | 小数点右边的位数 |
格式符:
| 格式符 | |
|---|---|
| %c | ASCII字符 |
| %d | 整数 |
| %e | 浮点数,科学计数法 |
| %f | 浮点数 |
| %o | 八进制数 |
| %s | 字符串 |
| %x | 十六进制数 |
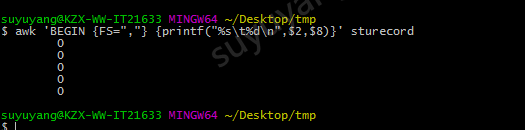
awk 'BEGIN {FS=","} {printf("%s\t%d\n",$2,$8)}' sturecord
#配合修饰符
awk 'BEGIN {FS==" ";print "Name\t\tPhonenumber"} {printf("%-15s\t%s\n",$1,$2)}' sturecord

5. awk 内置字符串函数
| function | |
|---|---|
| gsub(r,s) | 在输入文件中用s替换r |
| gsub(r,s,t) | 在t中用s替换r |
| index(s,t) | 返回s中字符串第一个t的位置 |
| length(s) | |
| match(s,t) | 测试s是否包换匹配t的字符串 |
| split(r,s,t) | 在t上将r分成序列s |
| sub(r,s,t) | 在t上将第一次出现的r替换为s |
| substr(r,s) | 返回字符串r中从s开始的后缀部分 |
| substr(r,s,t) | 返回字符串r中从s开始长度为t的后缀部分 |
6. 向awk脚本文件 传递传输
awk脚本 parameter=value 输入文件
./pass.awk MAX=3 FS="," inpufilename
注意命令行参数无法被BEGIN字段语句访问
7. awk 中条件语句与循环语句
if (x ~ /[Hh]el?o/) print x
do
动作
while (天剑表达式)
for (设置计数器初值;测试计数器;计数器变化)
动作
8. awk 数组 array[index]=value
关联数组
8. awk 实操记录
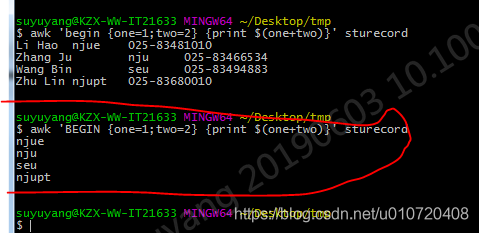
输入文件为sturecord:(姓名中是空格,后面的都是Tab键)
Li Hao njue 025-83481010
Zhang Ju nju 025-83466534
Wang Bin seu 025-83494883
Zhu Lin njupt 025-83680010

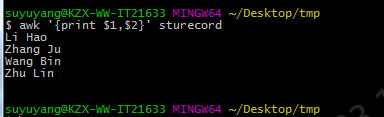
#awk 打印第一、二列域
awk '{print $1,$2}' sturecord
#awk 变量指定域号
awk 'begin {one=1;two=2} {print $(one+two)}' sturecord
#-F 改变分隔符
awk -F "\t" 'print $3' sturecord

#awk 同样也提供另一个环境变量FS的改变分割符
awk 'BEGIN {FS=","} {print $0}' sturecord
awk 'BEGIN {FS=","} {print $1,$3}' sturecord
#awk 中 ~匹配正则表达式 !~ 不匹配正则表达式
awk 'BEGIN {FS=":"} $1~/root/' /etc/passwd
#if/else else 以及与或运算,用逗号分割,第三列等于10或第四列等于10则打印整行
awk 'BEGIN {FS=","} {if ($3==10 || $4==10) print $0}' /etc/paswd
#awk 统计 空行,类似C/C++ 有x++ ++x的区别
awk '/^$/{print x+=1}' input