下载安装:https://www.elastic.co/cn/downloads/
概念
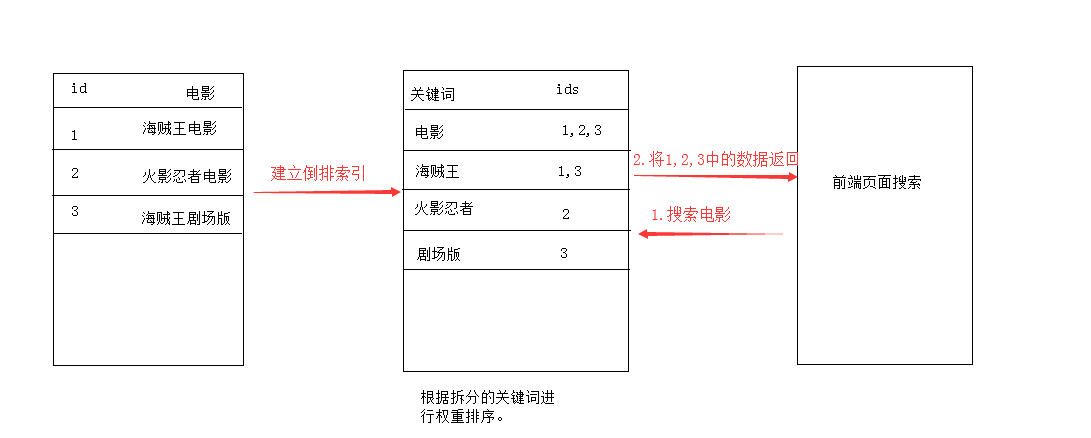
ElasticSearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用ElasticSearch的水平伸缩性,能使数据在生产环境变得更有价值。ElasticSearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elastic Search 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。底层基于Lucene。
Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。
全文检索、倒排索引(示意图)
lucene
lucene.就是一个jar包,里面包含(封装好的各种建立倒排索引,以及进行搜索的代码,包含各种算法、我们用java开发的时候,引人lucene jar,然后基于lucene的api开发即可,用lucene,我们就可以去将已有的数据建立索引,lucene会在本地磁盘上面,给我们组织索引的数据结构。另外的话,我们也可以用lucene提供的一些功能和api来针对磁盘上的索引数据,进行搜索。
Elasticsearch
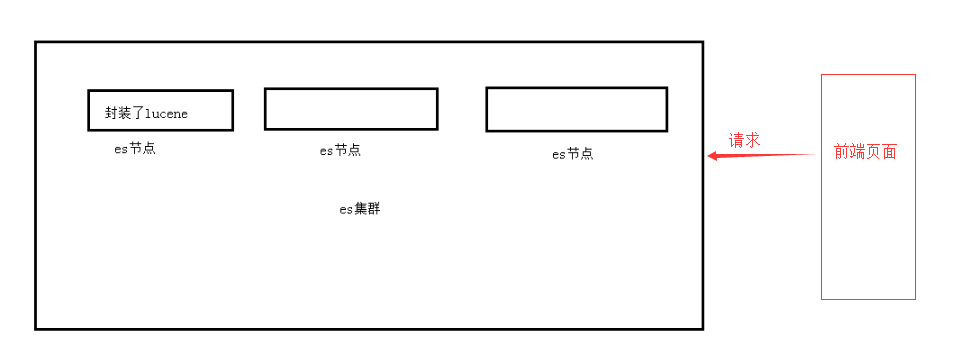
1.自动维护数据的分布到多个节点索引的建立,还有搜索请术分布到多个节点的执行
2.自动维护数据的冗余副本,包证说,一些机器宕机了,不会丢失任何的数据
3.封装了更多的高级功能,以给我们提供更多高级的支持,让我们快速的开发应用,开发更加复杂的应用,复杂的搜索功能,聚合分析的功能,基于地理位置的搜素(距离我当前位置1公里以内的烤内店)
shard和replica
shard:单机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分不到多态服务器上去执行,提高吞吐量和性能。,每一个share都是一个Lucene index
replica:任何服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提供检索操作的吞吐量和性能。primary share(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数重,默认1个,默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
index和type和document
ES中document相当数据库中的一行。
ES中的type相当数据库中的表
ES中的index相当数据库中的数据库
使用
windows启动
启动命令(进入bin目录)
elasticsearch.bat
如果出现
ElasticsearchException[X-Pack is not supported and Machine Learning is not available for [windows-x86]; you can use the other X-Pack features (unsupported) by setting xpack.ml.enabled: false in elasticsearch.yml错误
解决:在elasticsearch.yml配置文件最后添加,重新启动
xpack.ml.enabled: false
访问浏览器
http://127.0.0.1:9200/
出现,表示启动陈宫
{
"name" : "xxxx-PC", //表示node(节点名称):在哪一台服务器上启动
"cluster_name" : "elasticsearch", //集群名称,如果需要修改,在conf/elasticsearch.yml中修改
"cluster_uuid" : "SSOU_2kJSW6xsHZFwfLrhg",
"version" : {
"number" : "7.2.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "508c38a",
"build_date" : "2019-06-20T15:54:18.811730Z",
"build_snapshot" : false,
"lucene_version" : "8.0.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
使用kibana
Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作。
启动(bin目录下)
kabana.bat
打开浏览器
http://localhost:5601
使用开发工具(dev tools)操作下面的命令
集群操作
GET /_cluster/health GET _cat/health?v 查看集群健康状况,status="green":表示每个索引的primary shard和replica shard都是active状态的 ="yellow": 表示每个索引的primary shard是active,但是部分replica shard都是不是active状态的 ="red":表示不是所有索引的primary shard是active,部分索引有数据丢失。 GET _cat/indices?v 快速查看集群中索引的情况 PUT /index_test?pretty 新建索引 index_test:测试的索引名 DELETE /index_test 删除index_test索引
数据的crud
put /index/type/id
{
"json数据"
}
示例:
PUT /test/test1/1 es会自动创建index和type
{
"name":"zy"
}