-
分析页面
请求页面的url为:https://s.taobao.com/search?q=keyword,本次爬虫keyword为“施华洛世奇”,页面使用Ajax获取商品,但是Ajax请求中有加密参数,解密比较麻烦,所以用selenium控制浏览器来爬取
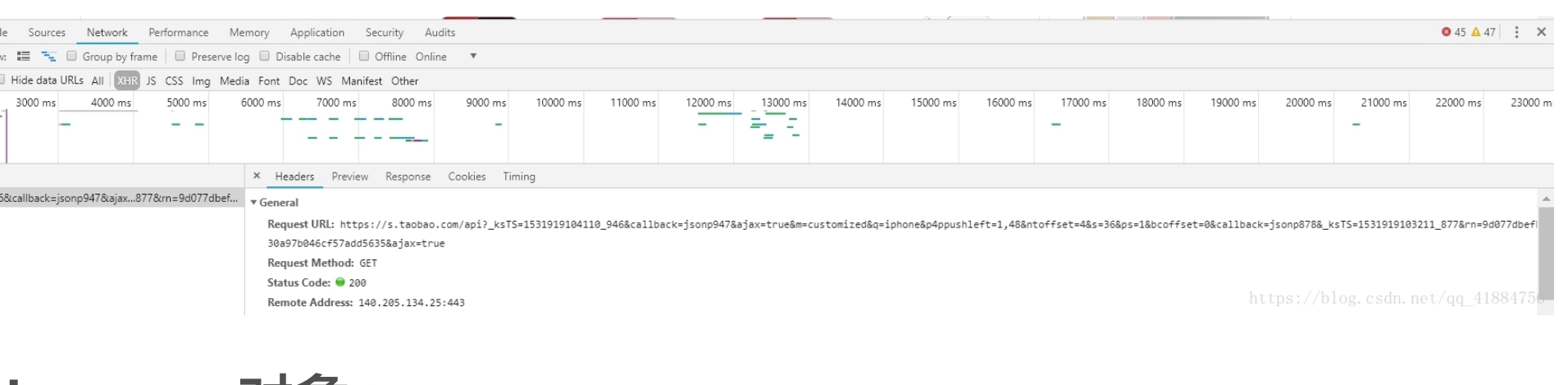
-
创建browser对象
这里首先构造了一个chrome浏览器对象,注意此处使用chrome-headless(无界面模式)来提高爬虫效率,又构造了一个WebDriverWait对象来等待加载,这里指定等待最大时长为5秒,如果在这个时间内成功匹配了等待条件,也就是页面元素加载出来了,就立即返回相应结果并继续向下执行,否则到了最大等待时间还没有加在出来,就抛出超时异常。


1 chrome_options = webdriver.ChromeOptions() 2 chrome_options.add_argument('--headless') 3 browser = webdriver.Chrome(chrome_options=chrome_options) 4 wait = WebDriverWait(browser,5) 5 keyword = '施华洛世奇'
-
抓取索引页:
使用chrome浏览器的开发者工具定位节点,此处定位的节点有:input(页码输入框),submit(提交页码按钮),item(商品节点,以及一个当前页码高亮显示的节点。如下图所示。
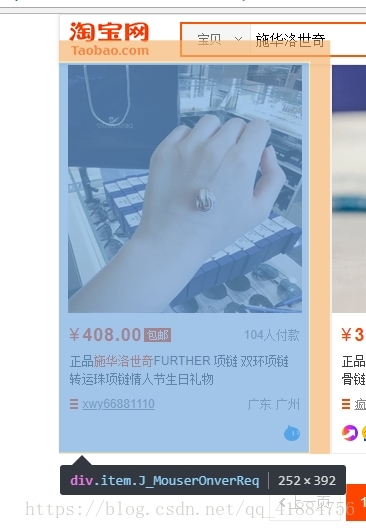
当page(页码)参数大于1(需要跳转页面)时,选定input节点,使用clear()方法清除文本框内原本的页码,使用send_keys()方法输入页码,使用click()方法点击submit按钮提交页码。当 当前页码显示高亮,以及所有item节点加载完毕时,使用browser的page_source属性将此时的页面html代码返回。实现代码如下:
1 def index_page(page): 2 '''抓取索引页,参数为页码''' 3 print('正在抓取第{0}页'.format(page)) 4 url = 'https://s.taobao.com/search?q='+quote(keyword) 5 browser.get(url) 6 try: 7 if page > 1 : 8 input = wait.until(EC.presence_of_element_located((By.XPATH,'//div[@id="mainsrp-pager"]//input[@aria-label="页码输入框"]'))) 9 submit = wait.until(EC.element_to_be_clickable((By.XPATH,'//div[@id="mainsrp-pager"]//span[@class="btn J_Submit"]'))) 10 input.clear() 11 input.send_keys(page) 12 submit.click() 13 except TimeoutException: 14 index_page(page) 15 wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'div#mainsrp-pager li.item.active > span'),str(page))) 16 wait.until(EC.presence_of_element_located((By.XPATH,'//div[@id="mainsrp-itemlist"]//div[@class="items"]/div[contains(@class,"item")]'))) 17 html = browser.page_source 18 return html
-
解析商品列表
首先接收刚才index_page(page)返回的html代码,作为参数传入。构造PyQuery解析对象,接着提取商品列表。使用CSS选择器选择所有商品节点,用items()方法得到一个生成器,然后就可以使用for循环遍历每一个item节点(商品节点),每一个item变量都是一个PyQuery对象,然后就可以使用find()方法,传入CSS选择器,就可以获取单个商品的特定属性内容了。最后将商品的属性和值储存为一个字典,print出来,再调用save_to_mongo()函数(稍后定义)将数据储存到mogodb数据库。
1 from pyquery import PyQuery 2 3 def get_products(html): 4 '''提取商品数据''' 5 doc = PyQuery(html) 6 items = doc('#mainsrp-itemlist .items .item').items() 7 for item in items: 8 product = { 9 '商品图片':'https:'+str(item.find('.img').attr('data-src')), 10 '价格':item.find('.price.g_price.g_price-highlight').text().replace('\n',' '), 11 '成交数':item.find('.deal-cnt').text(), 12 '商品标题':item.find('.row.row-2.title').text().replace('\n',' '), 13 '店铺名称':item.find('.shopname').text(), 14 '位置':item.find('.location').text() 15 } 16 print('\t',product) 17 save_to_mongo(product)
-
将数据储存到MongoDB数据库
首先创建一个MongoDB的连接对象:client,然后指定数据库:爬虫练习,指定集合Colletion的名称为“淘宝商品”。接着调用insert方法讲数据插入到MongoDB。此处的数据就是在get_products()方法传来的商品字典。
1 import pymongo 2 3 client = pymongo.MongoClient(host='localhost',port=27017) 4 db = client.爬虫练习 5 6 def save_to_mongo(product): 7 try: 8 if collection.insert(product): 9 print('\t\t --成功保存') 10 except Exception as e: 11 print('\t\t --保存失败\n',e)
-
定义主函数
1 def main(page): 2 html = index_page(page) 3 get_products(html)
-
运行代码
使用一个for循环向主函数传入page参数。用range()函数得到页码遍历,定义最小页码为1,最大页码为页面最大页码,最大页码为上面定位的input节点中的max属性值,这里贪方便,直接定义为100(最多100页)。实现代码如下
1 if __name__ == '__main__': 2 for page in range(1,101): 3 main(page)
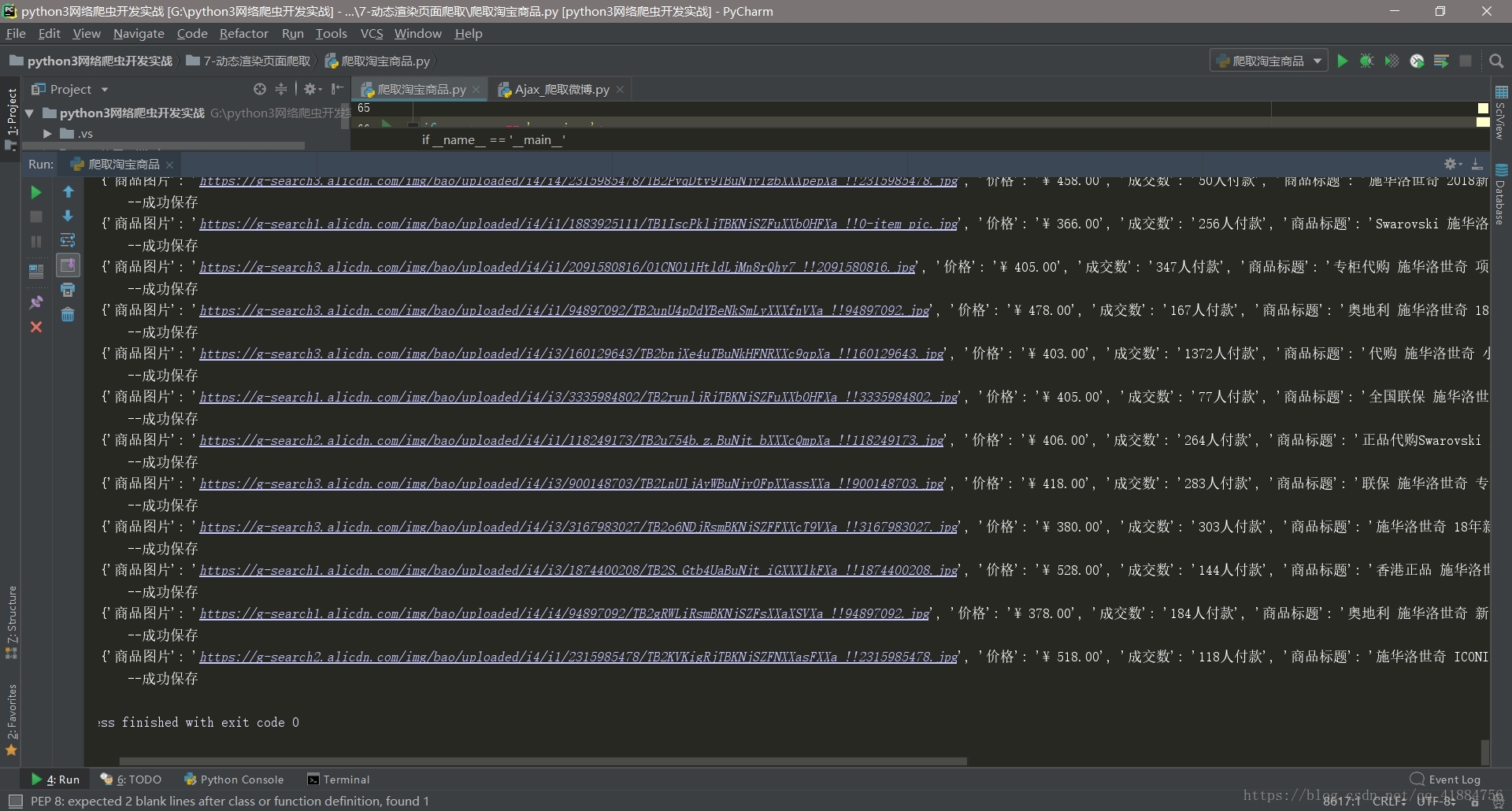
运行结果如下:
1 from selenium import webdriver 2 from selenium.common.exceptions import TimeoutException 3 from selenium.webdriver.common.by import By 4 from selenium.webdriver.support import expected_conditions as EC 5 from selenium.webdriver.support.wait import WebDriverWait 6 from urllib.parse import quote 7 from pyquery import PyQuery 8 import pymongo 9 10 chrome_options = webdriver.ChromeOptions() 11 chrome_options.add_argument('--headless') 12 browser = webdriver.Chrome(chrome_options=chrome_options) 13 wait = WebDriverWait(browser,5) 14 keyword = '施华洛世奇' 15 16 client = pymongo.MongoClient(host='localhost',port=27017) 17 db = client.爬虫练习 18 collection = db.淘宝商品 19 20 def index_page(page): 21 '''抓取索引页,参数为页码''' 22 print('正在抓取第{0}页'.format(page)) 23 url = 'https://s.taobao.com/search?q='+quote(keyword) 24 browser.get(url) 25 try: 26 if page > 1 : 27 input = wait.until(EC.presence_of_element_located((By.XPATH,'//div[@id="mainsrp-pager"]//input[@aria-label="页码输入框"]'))) 28 submit = wait.until(EC.element_to_be_clickable((By.XPATH,'//div[@id="mainsrp-pager"]//span[@class="btn J_Submit"]'))) 29 input.clear() 30 input.send_keys(page) 31 submit.click() 32 except TimeoutException: 33 index_page(page) 34 wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'div#mainsrp-pager li.item.active > span'),str(page))) 35 wait.until(EC.presence_of_element_located((By.XPATH,'//div[@id="mainsrp-itemlist"]//div[@class="items"]/div[contains(@class,"item")]'))) 36 html = browser.page_source 37 return html 38 39 def get_products(html): 40 '''提取商品数据''' 41 doc = PyQuery(html) 42 items = doc('#mainsrp-itemlist .items .item').items() 43 for item in items: 44 product = { 45 '商品图片':'https:'+str(item.find('.img').attr('data-src')), 46 '价格':item.find('.price.g_price.g_price-highlight').text().replace('\n',' '), 47 '成交数':item.find('.deal-cnt').text(), 48 '商品标题':item.find('.row.row-2.title').text().replace('\n',' '), 49 '店铺名称':item.find('.shopname').text(), 50 '位置':item.find('.location').text() 51 } 52 print('\t',product) 53 save_to_mongo(product) 54 55 def save_to_mongo(product): 56 try: 57 if collection.insert(product): 58 print('\t\t --成功保存') 59 except Exception as e: 60 print('\t\t --保存失败\n',e) 61 62 def main(page): 63 html = index_page(page) 64 get_products(html) 65 66 if __name__ == '__main__': 67 for page in range(1,101): 68 main(page)