kubernetes(k8s)是docker容器用来编排和管理的工具
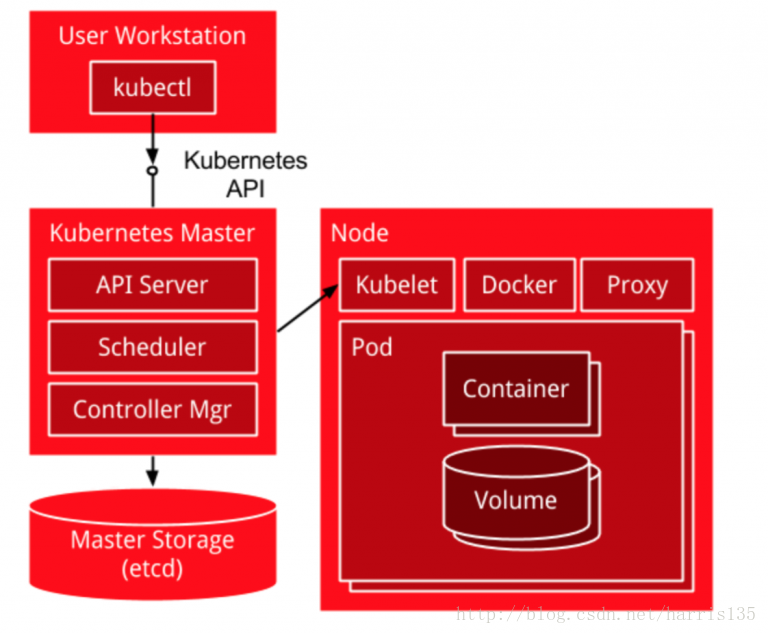
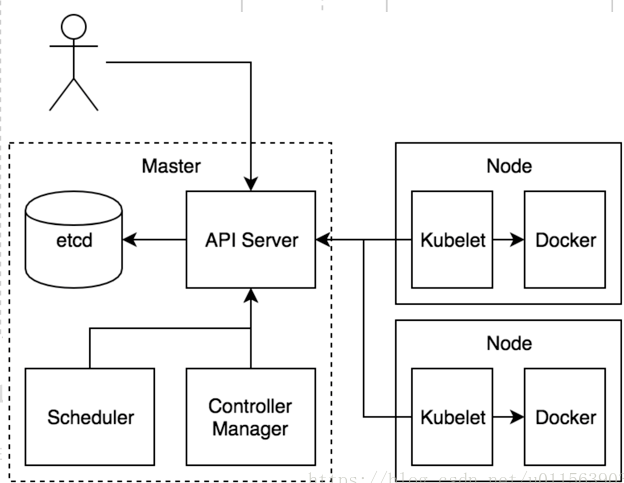
我们通过kubectl向k8s Master发出指令。kubernetes Master主要是提供API Server、Scheduler、Controller组件,接收kubectl的命令,从Node节点获取Node的资源信息,并发出调度任务。Node节点提供kubelet、kube-proxy,每个node节点都安装docker,是实际的执行者。kubernetes不负责网络,所以一般是用flannel或者weave。etcd负责服务发现和node信息存储
具体信息
开始介绍每个核心组件的功能。然后将看一个典型的调度和启动一个Pod的流程。
1. Datastore: Etcd
Etcd是Kubernetes的存储状态的数据库。虽然Kubernetes系统中有重要的内存缓存,但Etcd被认为是记录系统状态。
Etcd的快速总结:它是一个集群分布式数据库,它可以提供分布式数据的一致性。这类的系统(如Zookeeper, Consul)是在 Google开发的chubby系统之后形成的,这些系统也称为"锁服务器",因为他们可以实现分布式锁。Etcd和chubby的数据模型是一个简单的层次化的Key,并存储了简单的非结构化value,这看起来像是一个文件系统。有意思的是,在Google, chubby 被频繁用于为实现访问本地文件和对象存储的功能的抽象文件接口。然而,分布式数据库的高度一致性,提供了数据的严格写入顺序并允许client原子性的对数据做更新操作。
可靠的系统的状态管理是任何系统中非常困难的一件事情。在分布式系统中,它是更加困难的,因为它引入了一致性算法,如raft或paxos。通过使用etcd,Kubernetes可以专注系统的其他部分。
Etcd的watch机制是Kubernetes工作的关键。系统允许client去执行轻量级的对于Key值变化事件的订阅。当要watch的数据发生变化时, client会立即得到通知。这可以用作分布式系统组件之间的协调机制。 一个组件一旦写入etcd,其他组件可以立即对该变化作出反应。
Etcd的消息机制正好和PubSub消息队列机制相反。在许多消息队列系统系统中,topic不存储真正的用户数据,但发布到这些topic的消息含有丰富的数据。对于像Etcd这样的系统,Key(类似于主题)存储了真实的数据而消息(数据变化通知)不含独特的丰富消息。换句话说,对于消息队列来说,topic很简单,而像Etcd则正好相反。(译者认为此处概括的非常准确)
2. Policy Layer: API Server
Kubernetes的核心组件是API Server,它是Kubernetes系统和Etcd直接对话的唯一组件。实际上,etcd是API server的实现细节,理论上也可以用其他分布式存储系统来支持Kubernetes.
API server是一个策略组件,提供对Etcd的过滤访问。它的作用本质上是相对通用的,目前正在被分解处理。因此,API Server也可以用于其他系统的控制平面。
API server的主要货物是资源,通过暴露简单的REST API 向外提供服务。这些资源有一个标准结构可以实现一些扩展功能。无论如何,API Server,允许各类组件创建,读取,写入,更新,和监视资源。
API Server的具体的功能:
认证和授权。Kubernetes有一个可插拔的认证系统。有一些内置的用户认证机制和授权这些用户访问资源。此外,还有一些方法可用于向外部服务提供这些服务。这种可扩展性是Kubernetes构建的核心功能。
API Server运行一组可以拒绝或修改请求的准入控制器。 这些允许策略被应用并设置默认值。 这是确保在API Server客户端仍在等待请求确认时进入系统的数据有效性的关键。 虽然这些准入控制器目前正在编译到API Server中,但目前正在进行的工作是使其成为另一种可扩展性机制。
API Server 有助于API 版本控制。API 版本的一个关键问题是允许资源的字段的改变,字段添加,弃用,重新组织和以其他方式转换。 API Server在Etcd中存储资源的"true"表示,并根据满足的API版本转换/呈现该资源。 自项目早期开始,规划版本控制和API的发展一直是Kubernetes的一项重要工作。
API Server 一个重要特性是支持watch机制。这意味着API Server的客户端可以使用与Etcd相同的协调模式。Kubernetes中的大多数协调包括写入另一个组件正在监视的API服务器资源的组件。 第二个组件将对几乎立即发生的变化做出反应。
3. 业务逻辑:Controller Manager and Scheduler
这些是通过API Server 进行协调的组件。这些称为Controller Manager和Scheduler的组件绑定到单独的服务器Master上
Scheduler组件将做许多事情让系统工作:
查找未分配给节点的Pod(未绑定的Pod);
检查集群的状态(缓存在内存中);
选择具有空闲空间并满足其他约束条件的节点;
将pod绑定到该节点。
Controller Manager 组件,实现ReplicaSet的行为。(ReplicaSet可以确保任何时候都可以运行一个Pod模板的副本数量)。控制器将根据资源中的选择器 监控ReplicaSet 资源和一组Pod。为了保持在ReplicaSet中稳定的一组Pod,控制器将创建、销毁Pod。
4.Node Agent: Kubelet
每一个Node上都有一个Agent。这也像其他组件一样对API Server进行身份验证。Agent负责监视绑定到其节点的一组Pod,并确保这些Pod正常运行,并且能实时返回这些Pod的运行状态。
5.典型的流程
为帮助理解,创建Pod的整个流程,时序图如下:
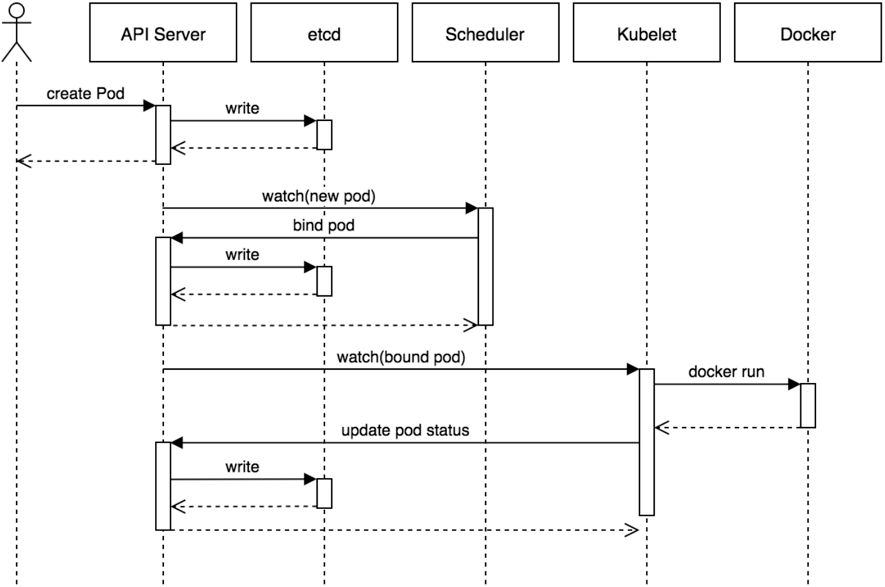
这个时序图展示了创建pod的流程,基本的流程如下:
1. 用户提交创建Pod的请求,可以通过API Server的REST API ,也可用Kubectl命令行工具,支持Json和Yaml两种格式;
2. API Server 处理用户请求,存储Pod数据到Etcd;
3. Schedule通过和 API Server的watch机制,查看到新的pod,尝试为Pod绑定Node;
4. 过滤主机:调度器用一组规则过滤掉不符合要求的主机,比如Pod指定了所需要的资源,那么就要过滤掉资源不够的主机;
5. 主机打分:对第一步筛选出的符合要求的主机进行打分,在主机打分阶段,调度器会考虑一些整体优化策略,比如把一个Replication Controller的副本分布到不同的主机上,使用最低负载的主机等;
6. 选择主机:选择打分最高的主机,进行binding操作,结果存储到Etcd中;
7. kubelet根据调度结果执行Pod创建操作: 绑定成功后,会启动container, docker run, scheduler会调用API Server的API在etcd中创建一个bound pod对象,描述在一个工作节点上绑定运行的所有pod信息。运行在每个工作节点上的kubelet也会定期与etcd同步bound pod信息,一旦发现应该在该工作节点上运行的bound pod对象没有更新,则调用Docker API创建并启动pod内的容器。