1.压缩概述
数据压缩这是mapreduce的一种优化策略:通过压缩编码对mapper或者reducer的输出进行压缩,以减少磁盘IO,提高MR程序运行速度(但相应增加了cpu运算负担)
-
Mapreduce支持将map输出的结果或者reduce输出的结果进行压缩,以减少网络IO或最终输出数据的体积
-
压缩特性运用得当能提高性能,但运用不当也可能降低性能
-
压缩使用基本原则:
运算密集型的job,少用压缩
IO密集型的job,多用压缩
2 MR支持的压缩编码
2.1下面是MR支持的压缩格式
注意:LZO和Snappy需要安装以后才能使用。
2.3同一个文件实际测试压缩结果
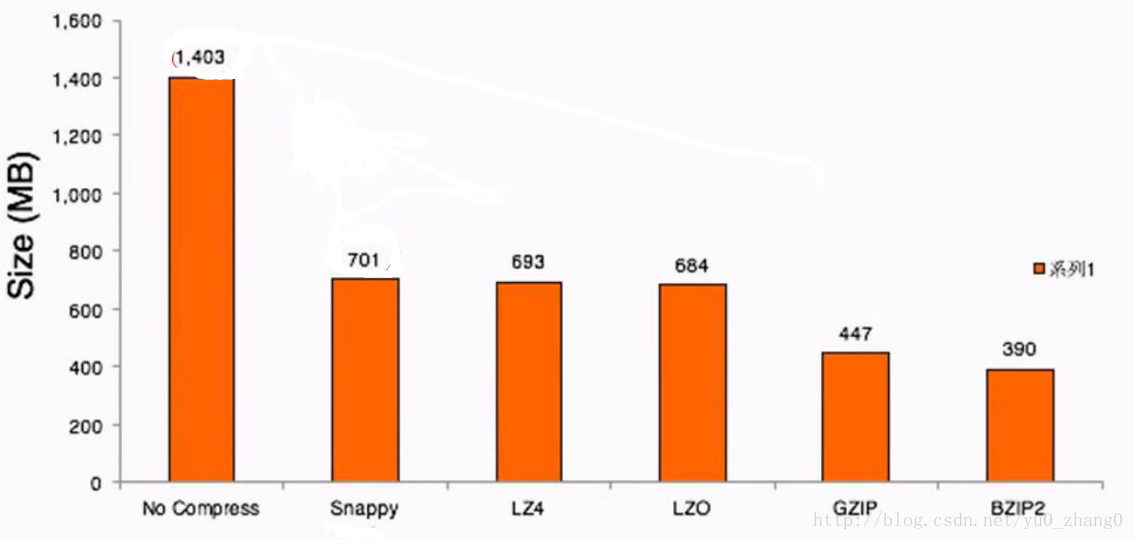
2.4压缩时间

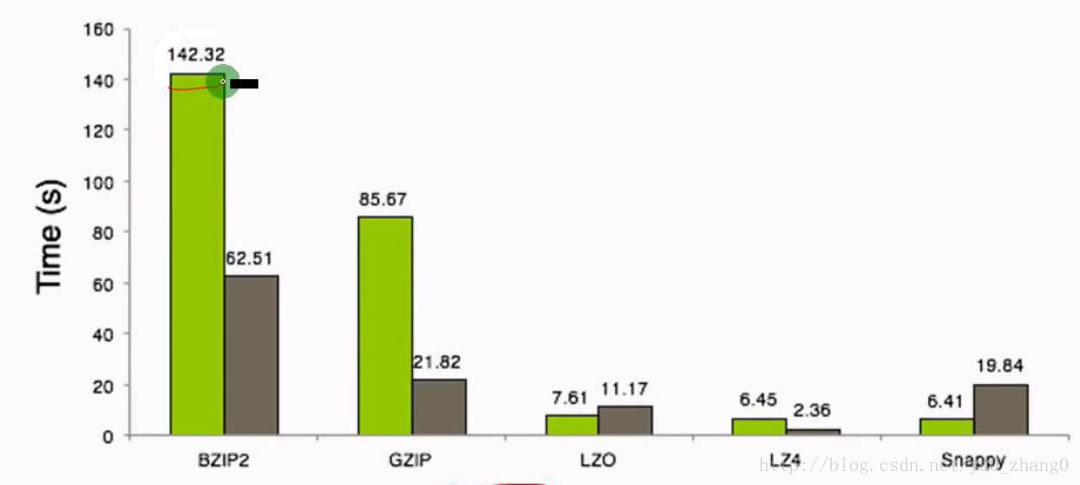
可以看出压缩性能越高,需要的压缩时间越长,Snappy < LZ4 < LZO < GZIP < BZIP2
1.gzip:
优点:压缩比在四种压缩方式中较高;hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;有hadoop native库;大部分linux系统都自带gzip命令,使用方便。
缺点:不支持split。
2.lzo压缩
优点:压缩/解压速度也比较快,合理的压缩率;支持split,是hadoop中最流行的压缩格式;支持hadoop native库;需要在linux系统下自行安装lzop命令,使用方便。
缺点:压缩率比gzip要低;hadoop本身不支持,需要安装;lzo虽然支持split,但需要对lzo文件建索引,否则hadoop也是会把lzo文件看成一个普通文件(为了支持split需要建索引,需要指定inputformat为lzo格式)。
3.snappy压缩
优点:压缩速度快;支持hadoop native库。
缺点:不支持split;压缩比低;hadoop本身不支持,需要安装;linux系统下没有对应的命令。
4.bzip2压缩
优点:支持split;具有很高的压缩率,比gzip压缩率都高;hadoop本身支持,但不支持native;在linux系统下自带bzip2命令,使用方便。
缺点:压缩/解压速度慢;不支持native。
2.5 中间压缩的配置和最终结果压缩的配置
可以使用Hadoop checknative检测本机有哪些可用的压缩方式
[finance@master2-dev ~]$ hadoop checknative
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=100m; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=150m; support was removed in 8.0
19/06/17 15:30:24 WARN bzip2.Bzip2Factory: Failed to load/initialize native-bzip2 library system-native, will use pure-Java version
19/06/17 15:30:24 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
19/06/17 15:30:25 ERROR snappy.SnappyCompressor: failed to load SnappyCompressor
java.lang.UnsatisfiedLinkError: Cannot load libsnappy.so.1 (libsnappy.so.1: cannot open shared object file: No such file or directory)!
at org.apache.hadoop.io.compress.snappy.SnappyCompressor.initIDs(Native Method)
at org.apache.hadoop.io.compress.snappy.SnappyCompressor.<clinit>(SnappyCompressor.java:57)
at org.apache.hadoop.io.compress.SnappyCodec.isNativeCodeLoaded(SnappyCodec.java:82)
at org.apache.hadoop.util.NativeLibraryChecker.main(NativeLibraryChecker.java:91)
Native library checking:
hadoop: true /log/software/hadoop-2.9.1.8/lib/native/Linux-amd64-64/libhadoop.so
zlib: true /lib64/libz.so.1
snappy: false
zstd : false
lz4: true revision:10301
bzip2: false
openssl: true /usr/lib64/libcrypto.so3.压缩的使用与配置文件的修改

core-site.xml codecs
从HDFS中读取文件进行Mapreuce作业,如果数据很大,可以使用压缩并且选择支持分片的压缩方式(Bzip2,LZO),可以实现并行处理,提高效率,减少磁盘读取时间,同时选择合适的存储格式例如Sequence Files,RC,ORC等;
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec, #zlib->Default
org.apache.hadoop.io.compress.BZip2Codec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec,
org.apache.hadoop.io.compress.Lz4Codec,
org.apache.hadoop.io.compress.SnappyCodec,
</value>
</property>mapred-site.xml (switch+codec)
<property>
#支持压缩
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
</property>
#压缩方式
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.BZip2Codec</value>
</property> 中间压缩:中间压缩就是处理作业map任务和reduce任务之间的数据,对于中间压缩,最好选择一个节省CPU耗时的压缩方式(快)。hadoop压缩有一个默认的压缩格式,当然可以通过修改mapred.map.output.compression.codec属性,使用新的压缩格式,这个变量可以在mapred-site.xml 中设置。Map输出作为Reducer的输入,需要经过shuffle这一过程,需要把数据读取到一个环形缓冲区,然后读取到本地磁盘,所以选择压缩可以减少了存储文件所占空间,提升了数据传输速率,建议使用压缩速度快的压缩方式,例如Snappy和LZO.
<property>
<name>mapred.map.output.compression.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description> This controls whether intermediate files produced by Hive
between multiple map-reduce jobs are compressed. The compression codec
and other options are determined from hadoop config variables
mapred.output.compress* </description>
</property> 最终压缩:可以选择高压缩比,减少了存储文件所占空间,提升了数据传输速率 。进行归档处理或者链接Mapreduce的工作(该作业的输出作为下个作业的输入),压缩可以减少了存储文件所占空间,提升了数据传输速率,如果作为归档处理,可以采用高的压缩比(Gzip,Bzip2),如果作为下个作业的输入,考虑是否要分片进行选择。
mapred-site.xml 中设置
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.BZip2Codec</value>
</property>5 hadoop源码压缩文件的读取
Hadoop自带的InputFormat类内置支持压缩文件的读取,比如TextInputformat类,在其initialize方法中:
public void initialize(InputSplit genericSplit,
TaskAttemptContext context) throws IOException {
FileSplit split = (FileSplit) genericSplit;
Configuration job = context.getConfiguration();
this.maxLineLength = job.getInt(MAX_LINE_LENGTH, Integer.MAX_VALUE);
start = split.getStart();
end = start + split.getLength();
final Path file = split.getPath();
// open the file and seek to the start of the split
final FileSystem fs = file.getFileSystem(job);
fileIn = fs.open(file);
//根据文件后缀名创建相应压缩编码的codec
CompressionCodec codec = new CompressionCodecFactory(job).getCodec(file);
if (null!=codec) {
isCompressedInput = true;
decompressor = CodecPool.getDecompressor(codec);
//判断是否属于可切片压缩编码类型
if (codec instanceof SplittableCompressionCodec) {
final SplitCompressionInputStream cIn =
((SplittableCompressionCodec)codec).createInputStream(
fileIn, decompressor, start, end,
SplittableCompressionCodec.READ_MODE.BYBLOCK);
//如果是可切片压缩编码,则创建一个CompressedSplitLineReader读取压缩数据
in = new CompressedSplitLineReader(cIn, job,
this.recordDelimiterBytes);
start = cIn.getAdjustedStart();
end = cIn.getAdjustedEnd();
filePosition = cIn;
} else {
//如果是不可切片压缩编码,则创建一个SplitLineReader读取压缩数据,并将文件输入流转换成解压数据流传递给普通SplitLineReader读取
in = new SplitLineReader(codec.createInputStream(fileIn,
decompressor), job, this.recordDelimiterBytes);
filePosition = fileIn;
}
} else {
fileIn.seek(start);
//如果不是压缩文件,则创建普通SplitLineReader读取数据
in = new SplitLineReader(fileIn, job, this.recordDelimiterBytes);
filePosition = fileIn;
}具体关于压缩的使用可以参考hive中的使用演示:Hive中压缩使用详解与性能分析