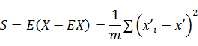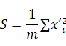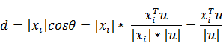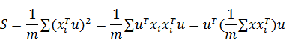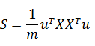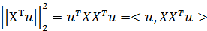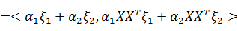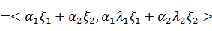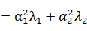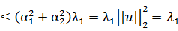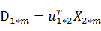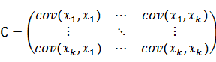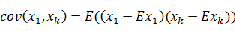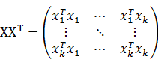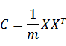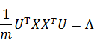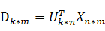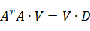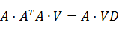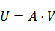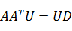摘 要:人脸识别几乎是所有刚入门机器视觉方面的同学最感兴趣的一个方面,当然我也不例外。利用OpenCV,我们可以很方便的就实现人脸识别算法,当然精度有待提高,所以就要求我们必须掌握其原理才能更进一步的提升自己的能力。这里给出利用OpenCV实现人脸识别程序的整个流程,一来巩固自己所学的知识,二来也能帮助刚入门的同学们。本文首先介绍了OpenCV中FaceRecognizer类的理论基础,然后结合具体案例实现识别本人的脸。
-
OpenCV人脸识别原理
FaceRecognizer这个类目前包含三种人脸识别方法:基于PCA变换的人脸识别(EigenFaceRecognizer),基于局部二值模式的人脸识别(LBPHFaceRecognizer)。这里只简要介绍基于PCA变换的人脸识别算法案例。
1.1 PCA(主成分分析)算法理论基础
我们所处理的图像一般可以看作是一个高维向量,如本案例中所使用的训练样本图像的像素为92*112,那么计算机就会把它抽象成一个92*112=10304维的高维向量,如此庞大的维数对于后续人脸检测识别的相关计算来说是相当困难的。因此需要找到一个合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面分析的目的。正是由于各变量间存在一定的相关关系,因此有可能用较少的综合指标分别综合存在于各变量中的各类信息。主成分分析与因子分析就属于这类降维的方法[1]。
-
二维数据降维
解决问题要从易到难,对于PCA主成份分析的理解,我们先从二维数据讲起。有这么一组数据,表示一个班5个同学的语文和数学成绩。
表1 成绩数据
学生编号
语文
数学
1
85
97
2
84
80
3
86
83
4
83
74
5
85
65
可以看到每个同学的语文成绩都差不多,但是数学成绩却差别很大,如果我们想要找出这个班中优秀的学生,理应是算出两科成绩的平均分然后进行评价。但是,实际上对于这个情况而言,我们只需要看数学成绩就可以了,因为数学是影响这个班成绩的最大因素,这样就将一组二维数据降维成了一组一维数据。
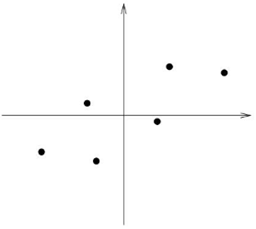
再抽象一点,下面有一组二维数据点,将其画在笛卡尔坐标系中如下图所示:
图1 数据样本点
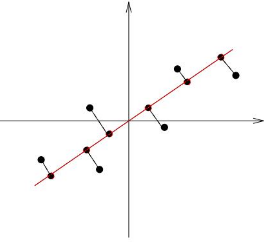
如果我们能找到一条直线,将上面的数据点投影到这条直线上也能很好的区分这几个数据点,那么这个过程就相当于将一组二维数据集降维成一维数据集了。这个问题的关键就是找到一个向量,使得数据点在该向量上的投影的样本点尽可能地分开,那么什么数学量能够衡量一组数据时离散程度呢?答案就是方差!
图2 二维数据降维
那么如何计算投影后样本点的方差呢?这里给出方差的数学定义:
如果该数据集的中心点位置为原点,即
,则有:
其中m表示样本点的数量,
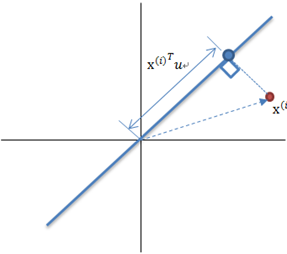
表示投影后的数据点距中心点距离,这个距离的数学表达式推导如下:
图3 变换基向量投影距离
如上图所示,u表示变换基向量,那么原数据
到其原点的距离为:
若u为单位向量,那么方差也可表示为:
设
,有:
由于样本的个数是固定的,那么二维数据的PCA主成份分析问题就是要最大化
,显然
是一个2*2的实对称正定矩阵,而
实际上就等于
的最大特征值,证明如下:
设
,且
,
为
的单位特征向量有
好的,对于简单的二维数据,我就可以通过计算
矩阵的最大特征值得到其对应的基向量u,这个u就是使得降维后样本间方差最大的方向。总结一下,PCA算法的步骤可以归纳为:
①求出二维数据样本点x和y的平均值,然后对于所有的样例都减去对应的均值。这样做的目的是要将样本的平均值位于原点,便于后续的计算;
②求解
矩阵的特征值和特征向量;
③将特征值按照从大到小的顺序排序,选择其中最大的一个,然后将其对应的特征向量作为投影基向量;
④将样本点投影到选取的特征向量上。那么投影后的数据为:
这样就将原始样例的2维特征变成了1维,且在该方向上的投影后的样本点之间的方差最大。
-
高维数据降维
既然已经弄清楚了2维数据的降维,高维数据的相关处理也就不难了。这里先简要介绍一下最大方差理论:在信号处理中认为信号具有较大的方差,噪声具有较小的方差,信噪比就是信号与噪声的方差比,越大越好。因此我们认为,降维后的k维特征是将n维样本转换为k维后,每一维上的样本方差都很大,而且不同基向量之间是线性无关的。对于二维数据,可以用方差来评价其投影后的质量,那么对于高维数据呢?有没有一个数学指标可以评价投影后的数据对原始数据的信息损失量呢?有的,答案就是协方差矩阵。
协方差矩阵的数学表达形式如下
对角线上分别是投影数据在基向量上的方差,非对角线上是其协方差。协方差是衡量多个变量同时变化的变化程度。协方差绝对值越大,两者对彼此的影响越大,反之越小。其中:
设
,
,
有:
不难发现
,所以协方差矩阵也可以写成:
对于二维数据,PCA算法就是找到一个基向量使样本点在该方向上的方差最大,对于高维数据则是找到一组基向量使样本点在这组基向量上的协方差尽可能的大,也就是说等价于将协方差矩阵对角化:即除对角线外的其它元素化为0,并且在对角线上将元素按大小从上到下排列,这样我们就达到了优化目的,即:
其中,U为n*k的变换单位基向量(也即投影方向),X为n*m的原始数据(n<k),
为对角阵。
这也是一个实对称矩阵的对角化问题,即求解
的特征值和特征向量,然后将特征向量从大到小排列,其对应的特征向量就是要降维的坐标轴。这样就能通过变换消除原有向量X的各分量间的相关性,从而有可能去掉那些带有较少信息的分量以达到降低特征维数的目的。
好了,总结一下高维数据的PCA算法求解步骤:
-
求出高维数据样本点
的平均值,然后对于所有的样例都减去对应的均值。实现中心化便于后续的计算;
-
求解
矩阵的特征值和特征向量;
③将特征值按照从大到小的顺序排序,选择其中最大的k个,然后将其对应的特征向量作为投影基向量;
④将样本点投影到选取的特征向量上。那么投影后的数据为:
这样就将原始样例的n维特征变成了k维,且在这组基向量方向上的投影后的样本点之间的方差最大。
1.2 matlab实现PCA算法
进行PCA算法的过程如下[2]:
-
假设有c个类别,每类包含s个样本,则n=c*s
-
对X计算
,将Y(也称特征脸)按类别计算均值,得到c个长度为h的列向量
;
-
对于未知类别的新样本,计算
,y的长度为h
-
计算距离
,取距离最小的i作为x的类标号。
不妨假设现有一组图像,像素为64*64,共有10张图片。将其按列排列有:
,其中
表示一张图片,维数为4094*1,X的维数为4096*10,如果我们直接对这个数据进行处理,那计算量是非常大的,所以我们就利用PCA算法来进行降维处理以减小计算量。这是别人写好的代码http://www.cnblogs.com/dupuleng/articles/4031652.html,同时给出自己的一些思考:
% training clear; clc; train_path='.\TrainDatabase\'; % phi存储样本,每一列对应一个样本 phi=zeros(64*64,20); for i=1:20 path=strcat(train_path,num2str(i),'.jpg'); Image=imread(path); Image = rgb2gray(Image);%彩色图像转为灰度图像 Image=imresize(Image,[64,64]); %样本归一到同一个尺寸 phi(:,i)=double(reshape(Image,1,[])'); end; mean_phi=mean(phi,2); %计算机平均脸 mean_face=reshape(mean_phi,64,64); Image_mean=mat2gray(mean_face); imwrite(Image_mean,'meanface.jpg','jpg'); Train_Number = size( phi , 2 ); %样本归一化,使每一维特征的期望为0,因为不同维度的取值范围差异很大,为方便处理,我们使其取值在同一个范围 A = []; for i = 1 : Train_Number temp = double( phi(:,i)) - mean_phi; A = [ A temp ]; end % C = A*A' 是A的协方差矩阵,然而C的维度太高,直接使用C计算特征值与特征向量太耗时 % L= C' ,L的特征值与C的特征值相同 , 而C的特征向量可以通过L的特征向量得到,因此这里使用L L = A'*A; [V D] = eig ( L ); L_eig_vec = []; grad = sum( D ,2 ); %D为对角矩阵,每个元素为相应的特征值,为方便后续处理,这里将特征值放到一个列向量 [ sortGrad , index ] = sort( grad ,'descend' );%排序 i = 1; temp = 0.0; sumValue = sum( grad ); %取能量值占所有特征值99%的前K的特征向量 while( temp/sumValue <= 0.99 && i <= 20 ) L_eig_vec = [ L_eig_vec V(:,index(i)) ]; temp = temp+sortGrad(i); i = i+1; end UL = A * L_eig_vec;%协方差矩阵C的特征向量,也称特征脸,每一维为一个特征脸。 UL也是转换矩阵,即通过UL将样本转化到低维空间,对样本进行降维 for i=1: size( UL , 2 ) Eigenface=reshape(UL(:,i),[64,64]); figure(i); imshow(mat2gray(Eigenface)); end不是说应该计算
得到一个4096*4096的矩阵然后计算其特征值从大到小排列吗?为什么代码中计算的
而不是
呢?其实
所对应的特征向量左乘A就是
的特征向量,这样就能将原来一个4096*4096的矩阵特征值求解问题简化为一个20*20的矩阵特征值求解问题。
不妨设
的特征向量为V,其特征值为D,有:
令故当我们算出
的特征向量和特征值后就可以通过左乘A矩阵得到
的前20个特征向量和特征值。当然了,也可以利用SVD(矩阵的奇异值分解)来求解
的特征向量和特征值。
-