
JBoss Data Grid是Red Hat中间件产品(http://www.redhat.com/products/jbossenterprisemiddleware/data-grid/),JBoss Data Grid是基于开源社区产品Infinispan(http://infinispan.org/)。 企业版的JBoss Data Grid与社区版的Infinispan代码完全一样,所以本部分内容基于Infinispan进行。
概述
Infinispan提供了两种模式:
- 本地模式 - Infinispan提供的非集群的模式,在本地模式下,Infinispan可看作是一个单节点的,在内存中的数据缓存。与集群模式相比,因为我们不会考虑集群的可扩展性,容错能力,等,这使得Infinispan性能更高,使用更高效。
- 集群模式 - 集群模式是多个Infinispan服务器(Infinispan实例)组成一个集群,集群中所有点构成一个数据网格。网格中某一节点的状态需要复制到其他所有节点,或节点的一个子集上。这个子集中节点数的多少确定了Infinispan数据网格的容错能力和可扩展性,子集节点数太大会阻碍Infinispan网格的可扩展性。集群模式中节点之间是通过JGroups来复制状态,我们在后面会做详细讨论。根据复制策略的不同,集群模式又可分为分布式模式,复制模式和无效模式
本地模式
尽管Infinispan主要特性体现在集群模式,Infinispan本地模式提供了需要实用高效的特性,Infinispan的Cache接口继承JDK的ConcurrentMap,和普通Map相比,Infinispan提供了如下特性:
- 缓存条目可通过缓存存储器保存到第三方存储服务器(关系数据库,No-SQL,云),并且可通过同步,异步的模式通过缓存存储器操作第三方存储服务器
- 缓存条目的逐出阻止Java虚拟机内存溢出
- 缓存条目的过期确保长时间未被使用的条目被移除
- JTA和XA支持使缓存操作有事务性的保证
- 基于MVCC的并发读处理确保缓存实体可被告诉的非阻塞的读取
Infinispan服务器的缓存容器
Infinispan服务器相当与一个缓存容器,容器中可以有多个缓存实体,这些缓存可以是本地的,也可以是集群的。Infinispan服务器提供协议(HotRod,Rest,Memcached)供客户端应用连接到服务器,对容器中的缓存进行操作。Infinispan服务器配置文件中cache-container属性表示缓存容器,这个属性中包括多个缓存的配置,包括本地缓存和集群缓存。如下为缓存容器简单配置,我们从JDG/standalone/configuration/standalone.xml中摘出。
<subsystem xmlns="urn:infinispan:server:core:5.3" default-cache-container="local">
<cache-container name="local" default-cache="default" start="EAGER">
</cache-container>
</subsystem>cache-container包括如下属性:
- name 确定了缓存容器的名字
- default-cache 确定了缓存容器默认使用的缓存实例
- start 确定是否在Infinispan服务器启动时加载缓存容器,该属性有效值可为EAGER或LAZY,如果为EAGER则Infinispan服务器启动时加载缓存容器,LAZY则在请求时加载
本地模式的配置
在Infinispan服务器中如下配置添加了本地缓存到缓存容器,如下:
<cache-container name="local" default-cache="default" >
<local-cache name="default" start="EAGER">
<locking isolation="NONE" acquire-timeout="30000" concurrency-level="1000" striping="false" />
<transaction mode="NONE" />
</local-cache>
</cache-container>如上通过配置文件创建的本地缓存类似通过Infinispan 接口 DefaultCacheManager创建默认缓存。 另外,本地缓存和集群缓存可以同时位于cache-container中,但如果缓存容器中有集群缓存,则cache-container必须要有<transport/> 属性。local-cache元素包括如下属性和子元素:
- name 确定了本地缓存的名字
- start 确定缓存容器是否默认启动缓存实例,该属性有效值可为EAGER或LAZY,如果为EAGER则缓存容器启动时启动缓存实例,LAZY则表示只有在请求时加载
- batching 确定是否批处理操作本地缓存
- indexing 确定本地缓存的索引属性,该属性有效值可为NONE,LOCAL和ALL
<clustering mode="local" />注意,如上为集群缓存配置模式指定local,在这种情况下,即使定义<transport/> 属性。
集群模式
根据状态复制策略的不同,集群模式又细分为:分布式模式,复制模式和无效模式,随后我们依次介绍。集群模式下我们可以进一步配置状态传输模式为同步或异步。
如果同步模式被使用,发送者阻塞等待接收者响应,直到发送者接收到响应线程才继续运行。而异步模式传输数据但不阻塞,不需要等待响应,这确保了集群的连续性。比如在Web应用集群中,负载均衡采用粘性会话的方式(sticky-session),请求都是到同一节点,这种情况我们使用异步模式复制HTTP会话状态。我们可以通过mode属性配置异步还是同步,如下示例配置为同步复制模式:<replicated-cache name="default" start="EAGER" mode="SYNC" batching="false" >
...
</replicated-cache>另为我们可以通过Infinispan提供的接口获取集群网格的物理地址:
AdvancedCache.getRpcManager().getT ransport().getPhysicalAddresses()Infinispan的三种集群模式
本处讨论Infinispan的三种集群模式:分布式模式,复制模式和无效模式,这三种模式也是Infinispan设计的关键所在。分布式模式在处理数据的能力上是线性增长的,为大数据处理提供了可能;复制模式是常用企业应用集群所采用的模式;无效模式为企业应用中高并发事务处理提供了基于缓存技术的解决方案,接下来我们依次讨论这些模式。
分布式模式
Infinispan分布式模式是指缓存条目保存在网格节点的一个子集上,而不是网格中每个节点都保存一份缓存条目。通常为了数据的备份和网格的容错能力,缓存条目保存在两个或两个以上的节点上。和其他集群的模式相比,由于缓存条目保存在网格节点子集上,使得在可扩展性上优于其他模式。
如图1所示,4台Infinispan服务器构建成一个4个节点的数据网格,保存缓存条目的子集为2。我们往服务器1上添加数据K/V,则哈希算法决定该数据保存在哪一个节点上,图中所示数据保存在了服务器2上。读取数据时,同样通过哈希算法到相应的节点上获取数据,图中所示我们在服务器3上获取缓存条目K/V。

图 1 Infinispan分布式模式
Infinispan分布式模式中数据备份或数据保存在网格中一个子集上体现了Infinispan的可扩展性和大数据的特点。如下公式可以计算出Infinispan数据网格的容量:Capacity = (memory * number) / numOwners- Capacity - 数据网格的容量
- memory - 数据网格中单个节点的内存大小
- number - 数据网格中节点的个数
- numOwners - 数据网格中节点子集(数据备份或数据保存的节点数)
比如我们有50个节点的,每个节点上可供Infinispan使用的内存大小为4GB,数据网格中节点子集为2,则数据网格的容量为(4 * 50) / 2,即为100GB。分布式模式使用连续性哈希算法,使得数据的读取具有透明性,接下来我们来探讨连续性哈希算法。
分布式模式的连续性哈希算法
Infinispan分布式模式通过连续性哈希算法从网格中选择出那些节点来保存缓存条目,节点总数就是数据网格中节点子集,哈希算法通过配置文件知道节点子集总数,同时它维护缓存条目一直存在于这个数的节点上。节点子集数的大小与Infinispan数据网格的性能和容错能力相关,节点子集数太大,即缓存条目保存在很多节点上会影响性能,但节点子集数太小又影响容错能力。
哈希算法还用来从网格中存取数据缓存数据,存取数据的过程中不是向所有节点发送多播请求,存取过程也不需要维护很繁多的元数据,一个PUT操作,只会产生网格中节点子集数(numOwners)个远程调运。一个GET操作只针对网格中某一个节点产生一次远程调运,在后台实质也是产生网格中节点子集数(numOwners)个调运,且这些调运是并发进行的,查询到的结果会返回给调运者。另为,在分布式模式下,不管配置的是同步调运还是异步调运,如果缓存条目不存在于本地时,同步调运请求用来从其他节点获取数据。
配置分布式模式
分布式模式属于Infinispan集群缓存,在Infinispan服务器中配置分布式模式我们需要在缓存容器中添加如下配置,具体编辑JDG/standalone/configuration/clustered.xml,添加distributed-cache元素到缓存容器(cache-container)。
<cache-container name="local" default-cache="default" >
<distributed-cache name="default" mode="{SYNC/ASYNC}" segments="${NUMBER}" start="EAGER">
<locking isolation="NONE" acquire-timeout="30000" concurrency-level="1000" striping="false" />
<transaction mode="NONE" />
</distributed-cache>
</cache-container>distributed-cache元素通过如下信息配置分布式缓存:
- name 定义了缓存名字,同来唯一标识缓存
- mode 定义了缓存的复制模式,有效的值为SYNC和ASYNC
- segments 该属性是选择性的,它直到了网格的哈希端,它的推荐值为网格中节点总数乘以10,该属性的默认值为80
- start 确定缓存容器是否默认启动缓存实例,该属性有效值可为EAGER或LAZY,如果为EAGER则缓存容器启动时启动缓存实例,LAZY则表示只有在请求时加载
<clustering mode="dist">
<sync replTimeout="${TIME}" />
<stateTransfer chunkSize="${SIZE}" fetchInMemoryState="{true/false}" awaitInitialTransfer="{true/false}" timeout="${TIME}" />
<transport clusterName="${NAME}" distributedSyncTimeout="${TIME}" strictPeerToPeer="{true/false}" transportClass="${CLASS}" />
</clustering>clustering元素的mode属性定义了集群缓存为分布式模式。
sync元素的replTimeout属性指定了等待运程调运的最大超时时间。如果到超时时间还没有接收到远程调运的确认,则抛出异常。
stateTransfer元素定义了集群中状态转换是怎么样完成的,状态转换发生在集群中节点离开或新节点加入。该元素有如下属性:- chunkSize 定义了批量处理对缓存条目的大小数,如果该属性值大于0,则批处理缓存条目数为该属性设定的数,如果该属性值小于会等于0,则禁用批处理
- fetchInMemoryState 如果该属性值为true,则缓存启动时请求获取周围缓存实例中的数据,这个影响缓存加载的时间
- awaitInitialTransfer 如果fetchInMemoryState属性值为true,awaitInitialTransfer属性可以使第一次CacheManager.getCache()方法调运阻塞,直到缓存获取到相邻缓存实例中的数据。该属性应用于分布式模式和复制模式,默认值为true
- timeout 定义了最大等待获取相邻缓存实例中数据的超时时间,单位为毫秒,如果在超时时间内没有接收到相邻节点的返回,则缓存加载取消,抛出相应异常
- clusterName 定义了集群的名字,节点只有定义相同的集群名字,才能够加入集群,构建Infinispan数据网格
- distributedSyncTimeout 定义了等待获取分布式锁的时间,这个分布式锁确保了缓存实例的状态交换,以及实时哈希分配缓存条目
- strictPeerToPeer 如果设定为true,如果缓存示例不存在,则复制操作失败,抛出异常;如果设定为false,如果缓存示例不存在,则复制操作忽略失败,只是做简单日志记录
- transportClass 定义了代表缓存传输的实现类
分布式模式中GET和PUT
在分布式模式中,在执行写命令之前执行一个GET操作。这个发生是因为确定的方法(例如,Cache.put())返回之前缓存中与key的对应K值,如下:
cache.put("key", "value-previous-cache");
String previous = cache.put("key", "value");字符串previous的值为value-previous-cache。实际上,Infinispan 的Cache对象是实现java.util.Map,Map接口中定义put()方法需要返回之前缓存中与Key对应的值。如果对应的的值没有发现则返回空,但是GET操作还是被执行。Infinispan中写操作为PUT操作,GET操作优先于PUT操作发生,且总是同步的,不管Infinispan配置的是同步还是异步,总是同步等待返回值。
Infinispan中GET操作优先于PUT操作发生,这个操作是非常昂贵的,特别是当网格节点较多,相关key对应的值比较大时,我们可以阻止GET操作不等待每个节点返回,当接收到任意一个节点返回时,结束同步等待,在GET操作中添加Flag.SKIP_REMOTE_LOOKUP标记可以忽略同步等待,这样是不会影响对缓存的操作,但破坏了java.util.Map的定义,如果您需要使用先前存在的数据,则不能设定此标记。
复制模式
Infinispan的复制模式是简单的集群缓存,缓存实例在网络环境中自动发现相邻的缓存实例,然后构建成一个集群,这样多个节点构建成一个集群网格。缓存条目添加到一个节点将会复制到其他所有节点上,同样在网格中的任何一个节点可以获取集群中所有的数据。
如图2所示,4台Infinispan服务器构建成一个4个节点的数据网格,我们往服务器1上添加数据K/V,则该数据会复制到其他三个节点上。
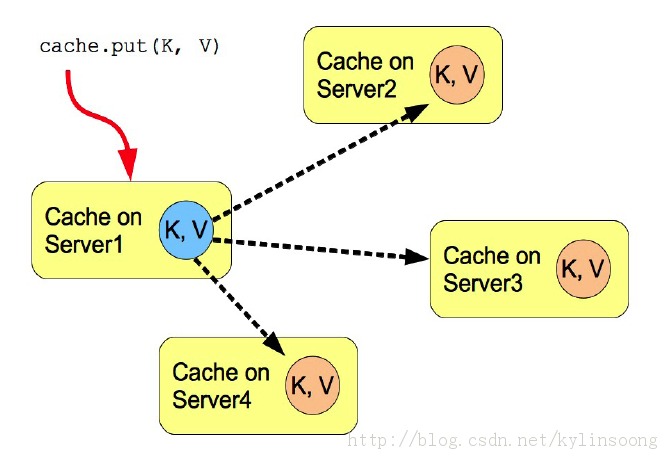
图2 Infinispan复制模式
复制模式的使用场景
复制模式用来在集群中共享状态,但复制模式的性能考虑集群网格的个数应该小于10,这是因为集群中任何一个点上状态的变化都需要复制到其他的节点上,如果集群网格中节点太多,大量的消息需要在节点之间进行传输,网络传输的压力会影响集群的性能。复制模式中消息通常采用多播的方式传播,这可以在一定程度上提高性能。复制模式中,GET操作的返回都是从本地返回而不需要远程调运,这使得查询速度更快,这也是复制模式的优势所在。
配置复制模式
复制模式属于Infinispan集群缓存,在Infinispan服务器中配置复制模式我们需要在缓存容器中添加如下配置,具体编辑JDG/standalone/configuration/clustered.xml,添加replicated-cache到缓存容器。另外在配置集群缓存时,JGroups必须合理配置,Infinispan集群缓存使用JGroups复制数据。
<cache-container name="local" default-cache="default" >
<replicated-cache name="default" mode="{SYNC/ASYNC}" start="EAGER">
<locking isolation="NONE" acquire-timeout="30000" concurrency-level="1000" striping="false" />
<transaction mode="NONE" />
</replicated-cache>
</cache-container>replicated-cache元素通过如下信息配置复制缓存:
- name 定义了缓存名字,同来唯一标识缓存
- mode 定义了缓存的复制方式,有效的值为SYNC(同步)和ASYNC(异步)
- start 确定缓存容器是否默认启动缓存实例,该属性有效值可为EAGER或LAZY,如果为EAGER则缓存容器启动时启动缓存实例,LAZY则表示只有在请求时加载
<clustering mode="repl">
<sync replTimeout="${TIME}" />
<stateTransfer chunkSize="${SIZE}" fetchInMemoryState="{true/false}" awaitInitialTransfer="{true/false}" timeout="${TIME}" />
<transport clusterName="${NAME}" distributedSyncTimeout="${TIME}" strictPeerToPeer="{true/false}" transportClass="${CLASS}" />
</clustering>clustering元素的mode属性定义了集群缓存为复制模式(repl)。
sync元素的replTimeout属性指定了等待运程调运的最大超时时间。如果到超时时间还没有接收到远程调运的确认,则抛出异常。
stateTransfer元素定义了集群中状态转换是怎么样完成的,状态转换发生在集群中节点离开或新节点加入。该元素有如下属性:- chunkSize 定义了批量处理对缓存条目的大小数,如果该属性值大于0,则批处理缓存条目数为该属性设定的数,如果该属性值小于会等于0,则禁用批处理
- fetchInMemoryState 如果该属性值为true,则缓存启动时请求获取周围缓存实例中的数据,这个影响缓存加载的时间
- awaitInitialTransfer 如果fetchInMemoryState属性值为true,awaitInitialTransfer属性可以使第一次CacheManager.getCache()方法调运阻塞,直到缓存获取到相邻缓存实例中的数据。该属性应用于分布式模式和复制模式,默认值为true
- timeout 定义了最大等待获取相邻缓存实例中数据的超时时间,单位为毫秒,如果在超时时间内没有接收到相邻节点的返回,则缓存加载取消,抛出相应异常
- clusterName 定义了集群的名字,节点只有定义相同的集群名字,才能够加入集群,构建Infinispan数据网格
- distributedSyncTimeout 定义了等待获取分布式锁的时间,这个分布式锁确保了缓存实例的状态交换,以及实时哈希分配缓存条目
- strictPeerToPeer 如果设定为true,如果缓存示例不存在,则复制操作失败,抛出异常;如果设定为false,如果缓存示例不存在,则复制操作忽略失败,只是做简单日志记录
- transportClass 定义了代表缓存传输的实现类
复制模式中异步和同步复制
复制模式中网格节点之间数据复制可以是异步的也可以是同步的,我们可以根据自己应用的需求进行选择。
同步复制阻塞调运线程(PUT操作)直到修改或添加的数据更新到节点上所有的节点,在没有接收到所有节点操作完成确认时,调运请求线程一直处于等待状态,这样确保复制的完整性。
异步复制与同步复制相反,相对于客户端请求线程,调运速度快,因为不需要等到网格中其它节点发送回确认消息。异步复制中执行复制的操作是在后台完成,复制过程中出现的错误会记录在日志中,异步复制的一个可能情况是客户调运端的事务是成功的,但某一个节点上事务是失败的,也就是所有的数据没有完全复制到其他节点。
在某些示例中可能会发生这样的现象,一个缓存配置使用异步复制,但是实际中也是阻塞等待同步返回,这是因为Infinispan中有些操作是同步操作,比如状态交换,这些操作总是同步的,不管配置的是异步还是同步。我们可以使用如下方法使状态交换不使用同步:- 禁止状态交换,在需要获取状态时使用ClusteredCacheLoader加载远程节点状态
- 在状态交换时使用REPL_SYNC,使用异步API(例如cache.putAsync(k, v))),这样可以异步交换状态
- 在状态交换时使用REPL_SYNC,所有远程调运是同步,但客户端可以不阻塞,这需要使用复制队列。我们推荐的方式是这样
复制队列
Infinispan复制模式中使用复制队列,将缓存条目的变化复制到其他节点。复制队列使用如下属性:
- 先前设定的时间间隔
- 队列的大小超过复制的元素
- 先前设定的时间间隔与队列的大小超过复制的元素的结合
复制队列确保了复制的进行,队列中缓存条目的复制采用批量复制的方式,不是一条一条的单独复制,这样减少了复制次数,增加了性能。复制队列通常和异步复制一起使用。使用复制队列,客户端请求不再阻塞等待其他节点的返回。当使用复制队列时,主要的缺点是复制是周期性的进行,这具体根据先前设定的时间间隔大小和队列的大小。这样可能会导致某一些消息积压在队列中较常时间,当然不使用复制队列会使消息及时传输。
如下为使用复制队列的一个配置示例:<replicated-cache name="asyncCache" start="EAGER" mode="ASYNC" batching="false" indexing="NONE" queue-size="1000" queue-flush-interval="500">
...
</replicated-cache>如上为异步复制使用复制队列,队列的大小为1000,设定的时间间隔为500毫秒。
失效模式
失效模式也是一种集群缓存,但实际上集群中各个节点之间并没有共享任何数据,而仅仅是从运行节点上在移除可能是过时的数据。此缓存模式只有在其他的永久存储,如数据库存在时才有意义,该模式通常用来优化那些读操作频繁的系统,使用Infinispan作为基于数据库之上的缓存,这样防止每次读取状态都需要进入数据库。如果缓存配置为失效而不是复制,每次当一个节点上的数据发生改变,集群中的其他节点会收到一条消息,通知他们该数据已经陈旧了,应该从缓存中驱逐。

图3 Infinispan 失效模式
如图3所示,4台Infinispan服务器构建成一个4个节点的数据网格,我们往服务器1上添加数据K/V_new,其他节点(服务器2,服务器3,服务器4)都会收到消息,键值对K对应的数据已经陈旧,其中服务器2中的K/V_old被从缓存中驱逐。失效模式中,当所有节点使用一个共享的缓存加载时将导致远程缓存取回已经修改的数据。这样做的好处是双重的:与复制缓存数据相比,只复制失效消息对网络的压力是非常小的,网络流量达到最小化;集群中的其他节点加载数据以一种懒加载的方式加载修改过的数据,仅在需要时获取。失效消息只有在缓存数据修改后发送,修改缓存数据可以在事务中或批量处理,但发送失效消息没有事务性和批量处理的限制。通常修改缓存数据提交成功后失效消息发送。这通常是更有效的,因为失效信息作为事务的一个整体,而不是基于每一个修改。
配置失效模式
失效模式属于Infinispan集群缓存,在Infinispan服务器中配置失效模式我们需要在缓存容器中添加如下配置,具体编辑JDG/standalone/configuration/clustered.xml,添加invalidated-cache到缓存容器。另外在配置集群缓存时,JGroups必须合理配置,失效模式使用JGroups复制失效消息。
<cache-container name="local" default-cache="default" >
<invalidated-cache name="default" mode="{SYNC/ASYNC}" start="EAGER">
<locking isolation="NONE" acquire-timeout="30000" concurrency-level="1000" striping="false" />
<transaction mode="NONE" />
</invalidated-cache>
</cache-container>invalidated-cache元素通过如下信息配置失效模式:
- name 定义了缓存名字,同来唯一标识缓存
- mode 定义了失效消息的复制方式,有效的值为SYNC(同步)和ASYNC(异步)
- start 确定缓存容器是否默认启动缓存实例,该属性有效值可为EAGER或LAZY,如果为EAGER则缓存容器启动时启动缓存实例,LAZY则表示只有在请求时加载
<clustering mode="inv">
<sync replTimeout="${TIME}" />
<stateTransfer chunkSize="${SIZE}" fetchInMemoryState="{true/false}" awaitInitialTransfer="{true/false}" timeout="${TIME}" />
<transport clusterName="${NAME}" distributedSyncTimeout="${TIME}" strictPeerToPeer="{true/false}" transportClass="${CLASS}" />
</clustering>clustering元素的mode属性定义了集群缓存为失效模式(inv)。sync元素的replTimeout属性指定了等待运程调运的最大超时时间。如果到超时时间还没有接收到远程调运的确认,则抛出异常。stateTransfer元素定义了集群中状态转换是怎么样完成的,状态转换发生在集群中节点离开或新节点加入。该元素有如下属性:
- chunkSize 定义了批量处理对缓存条目的大小数,如果该属性值大于0,则批处理缓存条目数为该属性设定的数,如果该属性值小于会等于0,则禁用批处理
- fetchInMemoryState 如果该属性值为true,则缓存启动时请求获取周围缓存实例中的数据,这个影响缓存加载的时间
- awaitInitialTransfer 如果fetchInMemoryState属性值为true,awaitInitialTransfer属性可以使第一次CacheManager.getCache()方法调运阻塞,直到缓存获取到相邻缓存实例中的数据。该属性应用于分布式模式和复制模式,默认值为true
- timeout 定义了最大等待获取相邻缓存实例中数据的超时时间,单位为毫秒,如果在超时时间内没有接收到相邻节点的返回,则缓存加载取消,抛出相应异常
- clusterName 定义了集群的名字,节点只有定义相同的集群名字,才能够加入集群,构建Infinispan数据网格
- distributedSyncTimeout 定义了等待获取分布式锁的时间,这个分布式锁确保了缓存实例的状态交换,以及实时哈希分配缓存条目
- strictPeerToPeer 如果设定为true,如果缓存示例不存在,则复制操作失败,抛出异常;如果设定为false,如果缓存示例不存在,则复制操作忽略失败,只是做简单日志记录
- transportClass 定义了代表缓存传输的实现类
异步和同步
失效模式中失效操作可以是同步,也可以是异步。类似于在复制模式中,同步失效阻塞失效消息发送线程,直到所有的集群里所有节点接收到失效信息的返回,所有节点失效数据被驱逐;而异步失效则不同,其广播失效消息,但不阻塞并等待响应。
L1缓存
连续多次GET操作会导致重复的远程调用重复的发生,为了防止重复远程调用,我们需要启用L1缓存。L1缓存将远程调运返回的值,在本地保存很短的一段时间(可配置),如此反复GET操作不会导致远程调用重复发生。如图4中,如果启用L1缓存,随后Server3上相同KEY的GET操作将不会导致任何远程调用。
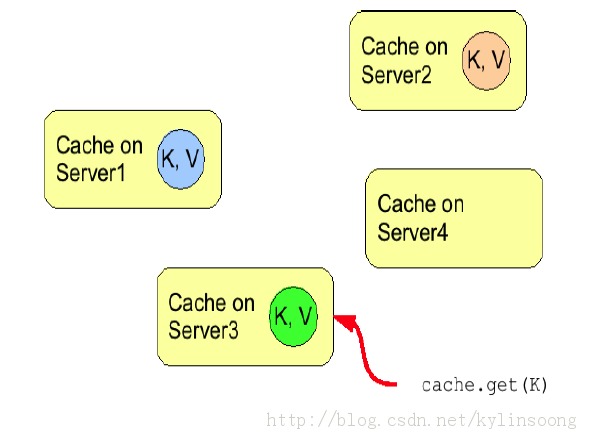
图4 L1缓存
l1元素包括如下属性:- enabled 是否启用L1缓存
- lifespan 远程调运在本地保存的时间
L1缓存不是永远有助于性能提升,开启L1缓存是有性能方面的消耗,任意节点上的缓存条目发生更新,相应的一个无效消息都需要以组播的方式发送到其他节点上,其他节点接收到无效消息将L1缓存中缓存条目无效,这样增加了网络负载。如果大量缓存条目存在于L1缓存会消耗大量内存,L1缓存适合于分布式模式中重复的读取某一些缓存条目的情形,具体开启L1缓存需要经过性能测试,确保有助于性能的提升,适合您的应用场景。
至此我们探讨了集群缓存(分布式模式,复制模式,失效模式)和本地缓存,JBoss 系列三十二将基于以上探讨的内容,通过实验测试验证以上理论。
转载于:https://my.oschina.net/iwuyang/blog/197214