一、前言
虽然在去年的离散学习中就已经为了学习和了解Dijkstra算法开始了python的学习,但是时隔半年,对python对语法知识渐渐有了模糊和遗忘.
二、今日学习内容
1)虽然是决定从零开始,但是对于python的基础语法还是有所认识和了解,但是学习是一个温故知新的过程,今天上午的学习中,也对我自以为比较熟练的python中的语法有了新的认识,比如用于切分的split的用法,之前的学习中,我只是用来作为,数据处理输入的分割,把字符串类型的分割输出.但是在今天上午的学习中,了解到了split函数是根据空格作为标准符来处理分割字符的,而且分割出来的数据类型不再是str而是list(列表类型)
2)
今天学习的主要是python的一些基础语法和数据类型中的字符串类型(str)
python学习的重点就是了解库,了解函数的使用,在python中有许多应用都是通过自带的函数实现的,对于学习和认识字符串就是学习字符串相关的函数.
需要掌握的
1.type函数
用法: type函数来确定数据的类型
test_='abc' print(type(test_)
2.strip函数
用法: 去掉字符串的空格
str1 = ' hello cheng ' print(str1) # 去掉两边空格 print(str1.strip()) #去掉左边空格 print(str1.lstrip()) #去掉右边空格 print(str1.rstrip())
3.lowper和upper函数
用法: 大小写的转换
str1 = 'hello cheng' #转换成小写 print(str1.lower()) #转换成大写 print(str1.upper())
4.startswith,endswith函数
用法: 判断开头或者结尾的字符串的值是否相等,是返回True不是返回Flase
str1 = 'hello cheng' #判断str1字符开头是否等于hello print(str1.startswith('hello')) # True #判断str1字符末尾是否等于cheng print(str1.endswith('cheng')) # True
5.format函数
用法: 格式化输出
#format(格式化输出)的三种玩法 str1 = 'my name is %s, my age %s!' % ('cheng', 20) print(str1) #方式一: 根据位置顺序格式化 print('my name is {}, my age {}!'.format('cheng', 20)) #方式二: 根据索引格式化 print('my name is {0}, my age {1}!'.format('cheng', 18)) # 方式三: 指名道姓地格式化 print('my name is {name}, my age {age}!'.format(age=18, name='cheng'))
6.split函数
用法: 拆分字符串。通过指定分隔符对字符串进行切片,并返回分割后的字符串列表(list)
test_='a b c' print(test_.split())
7.join函数
用法: 字符串拼接
# join 字符串拼接 # 报错,只允许字符串拼接 print(' '.join(['cheng', 18])) #根据空格,把列表中的每一个字符串进行拼接 print(' '.join(['cheng', '18', 'from GZ'])) #根据_,把列表中的每一个字符串进行拼接 print('_'.join(['cheng', '18', 'from GZ']))
8.replace函数
用法: 字符串替换
#replace:字符串替换 str1 = 'my name is cheng, my age is 20!' print(str1) str2 = str1.replace('cheng', 'qian') print(str2)
9.isdight函数
用法: 判断字符串是否为数字
choice = input('请选择功能[0, 1, 2]: ') 判断用户输入的选择是否是数字 print(choice.isdigit())
三、总结
今天对我自己而已是第三次从新开始接触python,在大二上学期的时候为了实现离散数学中的Dijkstra算法,自主学习了python,但是只是了解性质的学习,并不是系统的学习.第二次的学习的契机是在大二下学期的时候为了方便数据结构的算法实现,开始重新学,最后遇到了一些瓶颈,在pta平台中,用python写的代码不能通过最后一个测试点的,因为最后一个测试点是大数据的测试,对于python语言来说需要的内存很多,但是pta中给的内存比较小,往往会产生超出内存的问题.这使得我在学习的后期,逐渐放弃了使用python来完成数据结构中的算法实现.第三次就是今天开始的认知实习,这次机会让我开始能够系统得复习和重新学习python这门语言.
四、作业
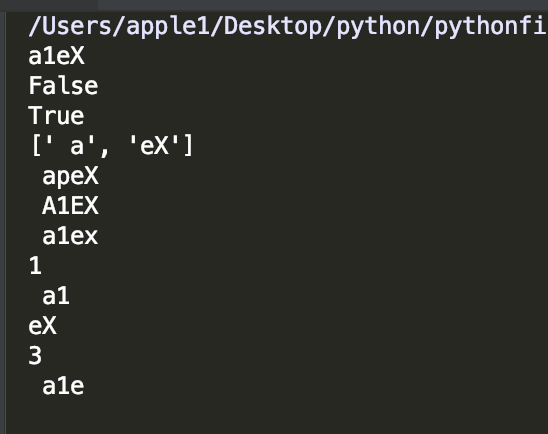
#homework #author_1704011044 程前 #python_study_day01_homework name=' a1eX' #print(type(name)) #Q1移除name变量对应的值两边的空格,并输出处理结果 print(name.strip()) #Q2判断name变量对应的值是否以"a1” 开头,并输出结果 print(name.startswith("a1")) #Q3判断name变量对应的值是否以"X”结尾,并输出结果 print(name.endswith("X")) #Q4将name变量对应的值中的 “1” 替换为“p”,并输出结果 print(name.split('1')) #Q5将name变量对应的值根据“1” 分割,并输出结果 new_name=name.replace('1','p') print(new_name) #Q6将name 变量对应的值变大写,并输出结果 print(name.upper()) #Q7将name 变量对应的值变小写,并输出结果 print(name.lower()) #8请输出name 变量对应的值的第2个字符 print(name[2]) #9请输出name 变量对应的值的前3个字符 print(name[0:3]) #10请输出name变量对应的值的后2个字符 print(name[-2:]) #Q11请输出name变量对应的值中“e” 所在索引位置? print(name.find('e')) #Q12获取子序列,去掉最后-一个字符 print(name[:-1])