好程序员web前端教程分享引用类型与基本类型,本文将从以下六个方面讲解引用类型和基本类型
1. 概念
2. 内存图
3. 引用类型和基本类型作为函数的参数体现的区别
4. 引用类型的优点:
5. 引用类型的赋值(对比基本类型)
6. 浅拷贝和深拷贝
以下为详细内容:
1. 概念:
基本类型也叫简单类型,存储的数据是单一的,如:学生的个数就是一个数字而已;引用类型也叫复杂类型,存储的数据是复杂的,如:学生,包括学号,姓名,性别,年龄等等很多信息。从内存(大家如果不懂内存,请查阅相关资料)的角度来说:基本类型只占用一块内存区域;引用类型占用两块内存区域。即定义基本类型的变量时,在内存中只申请一块空间,变量的值直接存放在该空间;定义引用类型的变量时(容易理解的是,我门看到new运算符,一般就是定义引用类型的变量),在内存中申请两块空间,第一块空间存储的是第二块空间的地址,第二块空间存储的是真正的数据;第一块空间叫作第二块空间的引用(地址),所以叫作引用类型。
javaScript中的基本类型包括:数字(Number),字符串(String),布尔(Boolean),Null,Undefined五种;
javascript的引用类型是:Object。而Array,Date是属于Obejct类型。
2. 内存图:
如下代码(都是定义了两个局部变量):
function demoFun(){
var num = 20;//定义了一个基本类型的变量。
var arr = new Array(12,23,34);//定义了一个引用类型的变量
}
以上两行代码的内存图:
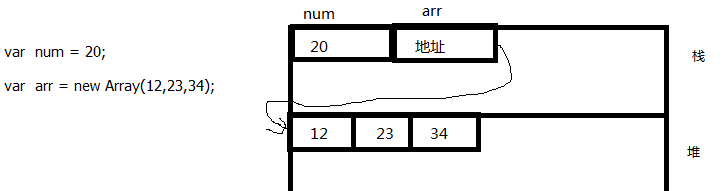
可以看到,num变量只占用了一块内存区域;arr变量占用了两块内存区域,arr变量在栈区(不懂栈区的人,先不要想太多)申请了一块内存区域,存储着地址,存储的地址是堆区的地址。而堆区中真正才存储着数据,所以说,arr变量占用了两块内存区域。这样看来,引用类型的变量好像还占用内存多了。哈哈,不要着急,后面了解了引用类型的优点后,你就会觉得这是问题了。
当我们读取num变量的值时,直接就能读到,但是当我们要读取arr里的值时,先找到arr中的地址,然后根据地址再找到对应的数据。
引用类型,类似于windows操作系统中的快捷方式。快捷方式就是一个地址,真正的内容是快捷方式所指向的路径的内容。如:我们把d:\t.txt文件创建一个快捷方式放在桌面上,那么,桌面上的快捷方式会占用桌面的空间,而d:\t.txt会占用d盘的空间,所以,占用了两块空间。
基本类型就相当于文件。
引用类型,类似于我们在入学报名填写报名表时,填写家庭地址,这个家庭地址就相当于第一块空间,真正你家(第二块内存空间)不在报名表上。学校要找你家,先在报名表上找到你家的地址,然后根据地址,才能找到你家去。
3. 引用类型的优点:
引用类型作为函数的参数时,优点特别明显,第一,形参传递给实参时,只需要传递地址,而不需要搬动大量的数据(节约了内存开销);第二,形参对应的数据改变时,实参对应的数据也在改变(很多时候,我们希望这样)。
如以下代码:
先定义函数(冒泡排序)
function bubble(arr){
for(var i=0;i
for(var j=0;j
if(arr[j]>arr[j+1]){
var temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
}
当调用冒泡排序时,
var arr1 = [250,2,290,35,12,99];
bubble(arr1);
看看内存以上代码执行时的,内存变化:
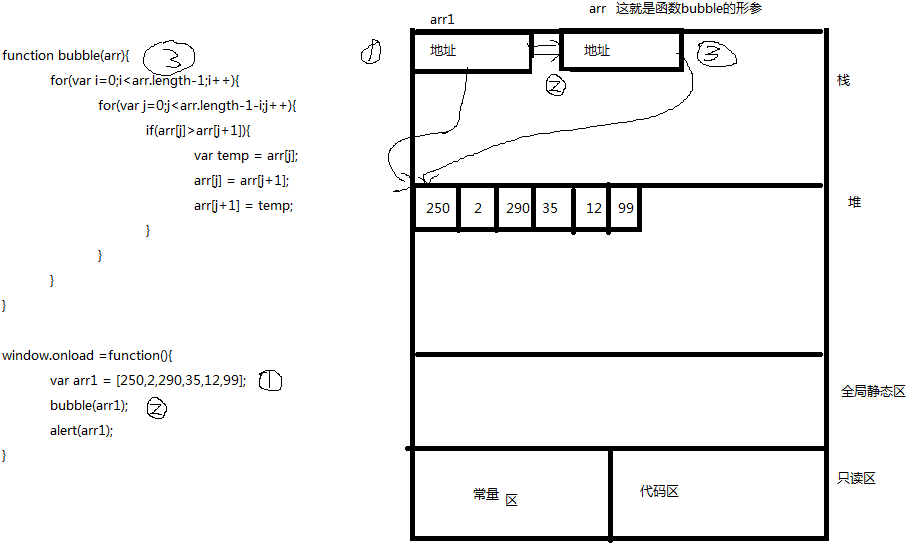
图中,当执行,①对应的代码(var arr1 = [250,2,290,35,12,99];)时,内存中会产生①对应的变化,即在栈中申请一块内存区域,起名为arr1,在堆区中申请内存空间放置250,2,290,35,12,99,并把堆区中的内存的地址赋给arr1的内存中;当执行②对应的代码bubble(arr1)时,调用函数。这时候会定义形参arr(内存中③对应的变化),即在栈中申请一块内存区域,起名为arr,并把arr1保存的地址赋给了arr(内存中②表示的赋值),这样,形参arr和实参arr1就指向了同一块内存区域。数组中的值250,2,290,35,12,99在内存中只有一份。即,不用把数组中每个元素的值再复制一份,节约了内存。如果对内存图看懂了,那么,当形参arr对应的数据顺序改变了,实参arr1对应的数据顺序也就改变了。即,实现了形参数据改变时,实参数据也改变了。所以,bubble函数不需要返回值,依然可以达到排序的目的。可以运行我示例中的代码,看看是不是达到了排序的效果。
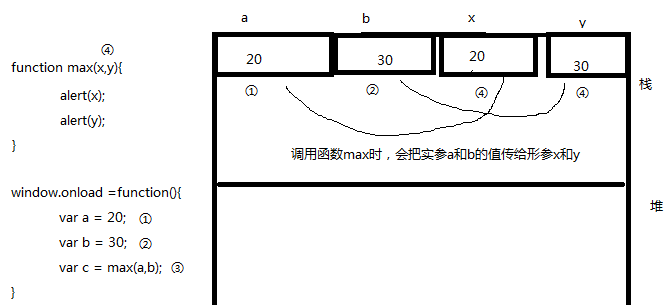
补充,基本类型作为函数参数的内存变化:
内存图:
4. 引用类型变量的赋值:
引用类型变量赋值时,赋的是地址。即两个引用类型变量里存储的是同一块地址,也就是说,两个引用类型变量都指向同一块内存区域。所以,两个引用类型变量对应的数据时一样的。

再如:
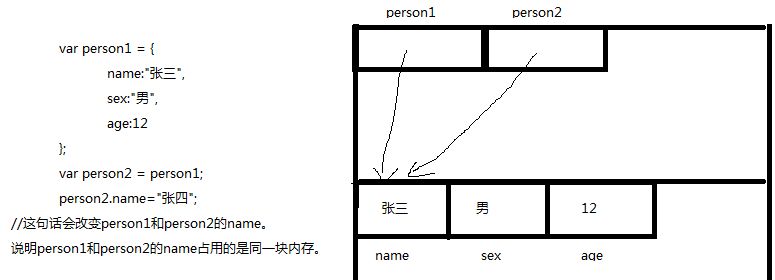
var person1 = {
name:"张三",
sex:"男",
age:12
};
var person2 = person1;
person2.name="张四"; //这句话会改变person1和person2的name。说明person1和person2的name占用的是同一块内存。
alert(person1.name+","+person1.sex+","+person1.age);
alert(person2.name+","+person2.sex+","+person2.age);
基本类型变量赋值时的内存变化。
5. 浅拷贝和深拷贝
先说对象的复制,上面说了,引用类型(对象)的赋值,只是赋的地址,那么要真正复制一份新的对象(即克隆)时,又该怎么办。
var person1 = {
name:"张三",
sex:"男",
age:12
};
var person2={};
for(var key in person1){
person2[key] = person1[key];
}
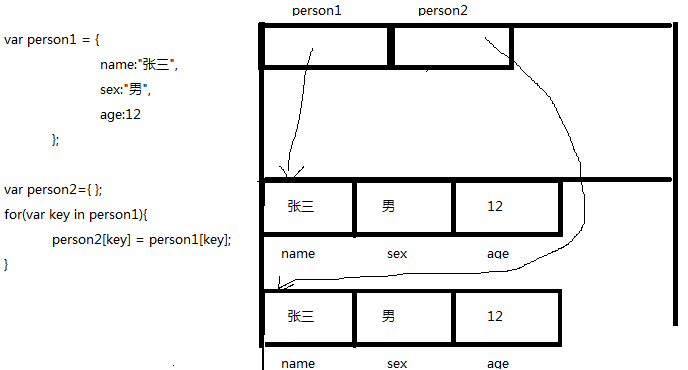
但是,当一个对象的属性又是一个引用类型时,会出现浅拷贝和深拷贝的问题。用一个自定义的object类型来说明问题。
如:
var person1 = {
name:"张三",
sex:"男",
age:12,
address:{
country:"陕西",
city:"渭南"
}
};
//对象person1的address又是个对象,即,要对person1做真正的克隆,需要把address中的每个属性也进行克隆。
var person2={};
for(var key in person1){
person2[key] = person1[key];
}
person2.name="张四"; //不会改变掉person1的name属性。
person2.address.country="北京";//会改变掉person1的address.country
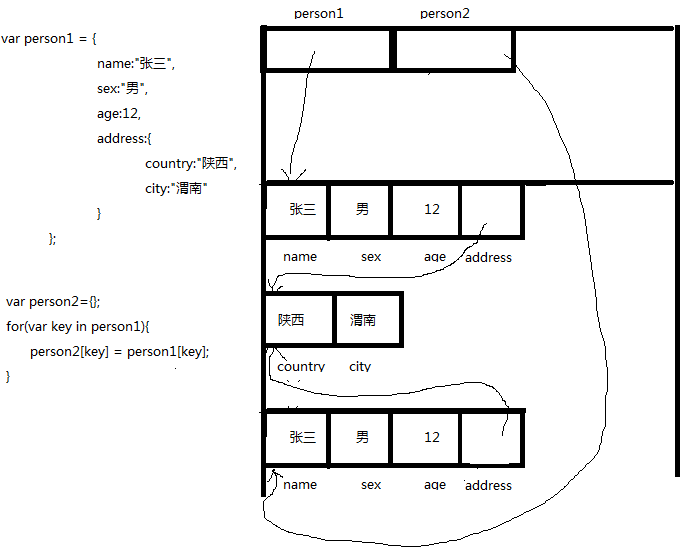
大家注意看,person1和person2的name属性各有各的空间,但是person1.address.country和person2.address.country是同一块空间。所以,改变person2.address.country的值时,person1.address.country的值也会改变。这就说明拷贝(克隆)的不到位,这种拷贝叫作浅拷贝,而进一步把person1.address.country和person1.address.name也拷贝(克隆)了,就是深拷贝。要做到深拷贝,就需要对每个属性的类型进行判断,如果是引用类型,就再循环进行拷贝(需要用到递归)。