深度学习的多gpu并行尝试——工作学习中的一点体会
目录
一、 深度学习并行常用方法
二、 代码解析
三、 实验结果
四、 一些细节
(一)并行常用方法:
一般有两种方法,一种是模型并行,另一种是数据并行。
模型并行:
由于bp网络的过程是个串行的过程,所以模型并行主要用在一个gpu的显存不能把所有的图结构都保存下来,于是我们把一个完整的网络切分成不同块放在不同gpu上执行,每个gpu可能只处理某一张图的几分之一。
比如下图LSTM模型分别放在了6个gpu上:

数据并行:
我们对每个gpu使用同样的网络结构:对数据进行切分在不同的gpu上运行,每个gpu的计算结果同步或者异步的更新模型参数。
数据并行可行性的思考:
一般来说深度学习的网络结构是个串行的过程,我们很容易有一种感觉异步更新会不会对参数更新造成困扰,比如在一个梯度方向上原来要更新1,结果每个gpu都过来更新1,6个gpu就更新了6,这不是纠枉过正?另外一种想法是本来深度学习的模型中我们就希望会有一些随机的扰动,
http://blog.csdn.net/qjzcy/article/details/51745190多gpu恰好暗合了这个概念,于是模型的鲁棒性会更好。哪一种更正确呢?来上代码,跑跑看!
(二)代码解析
for i in xrange(FLAGS.num_gpus): #对每个gpu构建深度学习的图结构
2. with tf.device('/gpu:%d' % i): #指定对哪个gpu执行构图
3. with tf.name_scope('%s_%d' % (cifar10.TOWER_NAME, i)) as scope:
4. loss = tower_loss(scope)
5. tf.get_variable_scope().reuse_variables()
6. summaries = tf.get_collection(tf.GraphKeys.SUMMARIES, scope)
7. grads = opt.compute_gradients(loss)
8. tower_grads.append(grads)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
(三)实验结果
今天太晚,先挖坑吧
(四) 一些细节
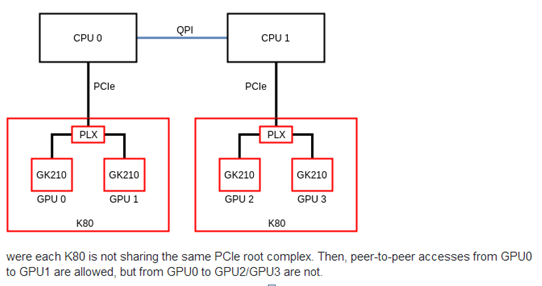
在设置多gpu的过程中发现tensorflow有这个提示,虽然并不影响运行,好奇心网上找了一下。大概是这么个意思如下图二,gpu0,1和gpu2,3并不能端对端直接交换数据,需要通过Qpi总线,显然这样效率要比端对端来的低。所以我们应该了解我们的GPU那些能端对端传递数据,尽量让数据在能端对端的gpu中处理,减少总线数据传输。
I tensorflow/core/common_runtime/gpu/gpu_init.cc:59] cannot enable peer access from device ordinal 0 to device ordinal 2
I tensorflow/core/common_runtime/gpu/gpu_init.cc:59] cannot enable peer access from device ordinal 0 to device ordinal 3
I tensorflow/core/common_runtime/gpu/gpu_init.cc:59] cannot enable peer access from device ordinal 1 to device ordinal 2
I tensorflow/core/common_runtime/gpu/gpu_init.cc:59] cannot enable peer access from device ordinal 1 to device ordinal 3
I tensorflow/core/common_runtime/gpu/gpu_init.cc:59] cannot enable peer access from device ordinal 2 to device ordinal 0
I tensorflow/core/common_runtime/gpu/gpu_init.cc:59] cannot enable peer access from device ordinal 2 to device ordinal 1
I tensorflow/core/common_runtime/gpu/gpu_init.cc:59] cannot enable peer access from device ordinal 3 to device ordinal 0
I tensorflow/core/common_runtime/gpu/gpu_init.cc:59] cannot enable peer access from device ordinal 3 to device ordinal 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9