The microservice architectural style is an approach to developing a
single application as a suite of small services, each running in its
own process and communicating with lightweight mechanisms, often an
HTTP resource API.These services are built around business capabilities and
independently deployable by fully automated deployment machinery.There is a bare minimum of centralized management of these services ,
which may be written in different programming languages and use
different data storage technologies.
以上是来自James Lewis 和 Martin Fowler关于微服务架构的定义。归纳起来,有以下几点:
- 整个应用系统由若干个独立运行的服务组成
- 服务之间有轻量级的通讯机制,通常是REST API
- 每个服务都有自己的业务逻辑,并且可以单独部署
- 去中心化的服务管理机制
- 每个服务可以用不同的编程语言实现,使用不同的数据存储技术
在整个微服务架构中,主角自然是一个个独立部署,独立运行的服务,而如果缺少一种管理这些服务的机制,就像这个社会突然没有了道德法律的约束了,整个微服务架构也就不成体系了。
笔者所理解的微服务架构大致是这个样子的:
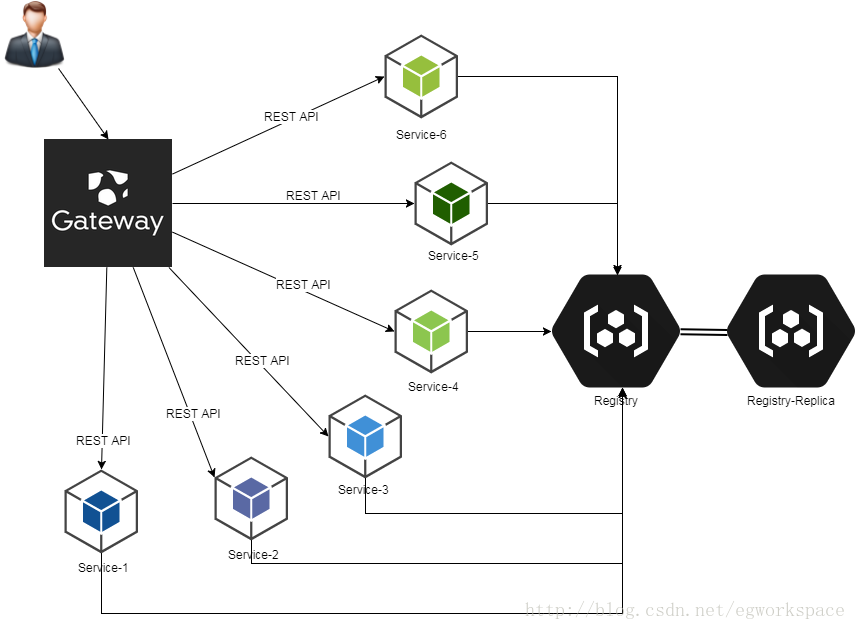
从这张图上可以看出,除了核心的微服务之外,还加入了API网关(Gateway)和注册发现中心(Registry)。但是这张图还并不是很完美,只能算是把一些核心机制表现出来了。
笔者还没想到用什么样的姿势能把微服务的各个机制较为完整的表现在一张图上,还是费一些笔墨加以叙述吧!
1、从Gateway说起
我们可以将Gateway视为整个系统的Entry Point,是具有非常重要的战略意义的,从上图中的位置可见一斑。让我们先考虑一个问题:
问:为什么需要Gateway?这部分可以舍弃吗?
答:从服务的用户角度考虑,没有Gateway,就意味着需要了解每个服务对外暴露的接口,这无疑是一个繁杂而毫无意义的工作;从服务的管理者角度考虑,没有Gateway,无论是日常的开发工作,还是日后的维护扩展工作,都将是一个严峻的考验。
所以结论很显然,Gateway对于整个微服务架构体系来说是不可或缺的。
实际上,我们的部署策略通常是一个服务部署多个实例,那么客户端发送一个请求过来,Gateway应该路由到哪个实例上呢?
是时候让Load Balance出场了。
所以,如果是以上的部署策略的话,通常是需要在Gateway和Services之间加一层Load Balance,通过一定的转发策略,最终路由到其中的一个服务实例上。
我们不妨再大胆假设一下:如果有多个Gateway,那会怎么样?
通常有这种考虑,是因为背后的服务数量非常多了,一个Gateway承载不了这么大的流量,所以才考虑多加几个帮手,每个Gateway路由一部分服务,最后可以形成一个Gateway的集群。
这个时候,整个架构的复杂度又上升了一个层次,新的问题又产生了,对于这群Gateway,必须要有效的管理起来。
简单的解决办法就是在这群Gateway前面加一个Load Balance,大概是这个样子:
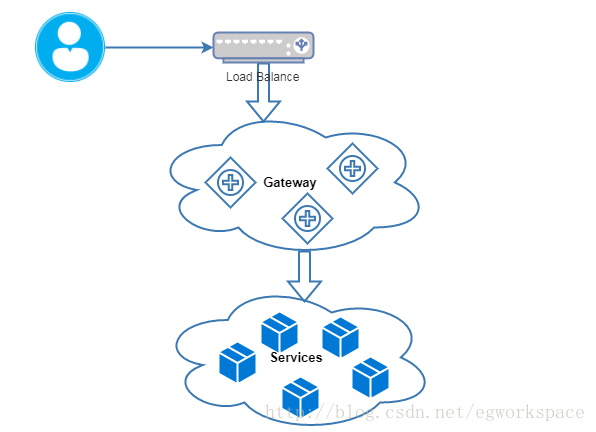
但是前面有多个Load Balance又该怎么办呢?
……
这个问题还没完没了了。只能是依实际情况而定了,这让我想起了一句话:

在Gateway层面还有很多好玩的东西,比如做监控,限流什么的。Gateway的实现手段也是多样的,NodeJs,Zuul,Nginx等等。
2、如何通讯
文章开头便提到了,微服务之间通常以REST API形式进行通讯。这里对REST稍作解释。
REST API并不是那么神秘,REST是建立在HTTP请求之上的,所以REST请求本质上是HTTP请求。
REST是面向资源(resources)的架构,API的每种操作都可以认为是资源的状态转移。
有三个重要的概念:
- Resource:资源,即数据。比如 goods,orders等;
- Representational:资源的某种表现形式,比如用JSON,XML,JPEG等;
- State Transfer:状态变化,通过HTTP动词实现。
当你的技术团队决定使用REST架构时,有两个细节需要斟酌一下:
- HTTP动词应该选哪个?尤其是PATCH和PUT的选择,要考虑清楚。
- 资源命名规范。REST的标准是命名都是名词,而且是复数形式。
既然是基于HTTP协议,我们不得不考虑因为各种原因导致一次请求失败了的问题。
通常情况下,我们会在系统中引入重试机制。请求重试的策略也不尽相同,比如最大重试3次,5秒内重试3次,如果多实例,还可以设置在每个实例上允许的最大重试次数。那么,即便是把重试次数都用光了,请求还是无法到达,该怎么应对呢?
我们试着感受一下:
Service-1因为某种原因被迫下线了,如果没有其他副本集的支撑,那么路由到Service-1的所有链路都将会被迫中断。如果这种状况不能尽快改善的话,可能在数秒内导致所有应用资源(线程,队列等)被耗尽,整条请求链路将会被拖累,甚至导致整个系统瘫痪。
这就是经典的雪崩效应(Cascading Failure)。
此时,需要在通向各个服务的链路上安插一个开关,就像家里面的空气开关,一旦遇到紧急情况,就会自动断开链路,不至于影响到其他的链路,进而保证整个系统的正常运行。
这就是所谓的熔断机制(Circuit Breaker)。这个机制并不是IT界独有的,在金融界也是赫赫有名的。这些概念都是来源于生活,提炼出一个又一个人类生存的法则。
还有一个与熔断相近的概念:降级。
在微服务领域,「服务熔断」和「服务降级」确实会对初学者造成一定的困惑。
其实仔细推敲一下,也不难理解。
两者都是出于对系统稳定性和安全性考虑,并且达到了一定的条件才会触发。不同的是触发的方式和场景是不一样的。
服务熔断一般是系统根据预设的条件自动触发的,比如连续请求失败10次,为了避免造成进一步的损失,系统直接让对应的服务下线。此时,开关相当于出于Closed状态,等到服务重新上线,建立了心跳连接后,开关状态就转换成Open状态。
服务降级的触发可以是人工干预的,也可以是系统自动触发的。这时候,服务之间是有层次之分的,被降级的某些服务的可用性降低了,用户在使用的时候,有时候会得不到预期的结果。
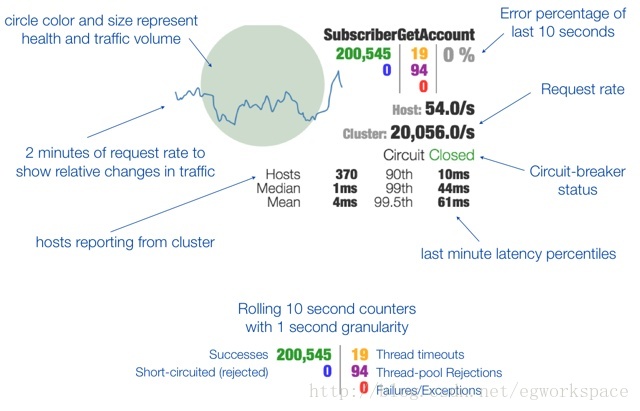
这两者之间也有一定的关系,总结起来就是:
由于长期的服务降级,导致了永久的服务熔断。
如果还不是很清楚,可以看我附上的第4个参考文献。
3、再谈Registry
在高度自治的微服务架构中,注册与发现中心(Registry)这个角色是十分重要的。
Registry的作用就好比是一本书的目录,通过目录可以找到相应的内容。Registry装载的就是微服务的元数据。当一个服务尝试去调用另一个服务,就会去Registry上请求一份元数据,找到被调用的服务在什么地方。
这样看来,每个服务都可以看作是一个Registry Client,Gateway也不例外。
Registry如此重要,通常我会希望其高可用,所以至少会为其多部署一个副本,每个Registry都持有一份完整的服务元数据。
此处不得再次提及文章开头说到的去中心化的服务管理机制。
在SOA架构体系中,ESB是整个系统的中心,如果ESB瘫痪了,那么也就意味着整个系统就不可用了。
微服务与SOA的一个重大区别就是去ESB,也就是去中心化。也就意味着,当Registry全部下线了,各个服务仍能正常运行。其中,做的一个主要的工作就是,每个Registry Client都缓存一份服务的元数据信息,以备不时之需。
在分布式系统领域有个著名的CAP定理:
- C——数据一致性(Consistency)
- A——服务可用性(Available)
- P——服务对网络分区故障的容错性(Partition tolerance)
这三个特性在任何分布式系统中不能同时满足,最多同时满足两个。架构师不要将精力浪费在如何设计能满足三者的完美分布式系统,而是应该进行取舍。
在SOA架构体系中,ESB优先满足的是一致性,以zookeeper为例,在使用Zookeeper获取服务列表时,如果zookeeper正在选主,或者zookeeper集群中半数以上机器不可用,那么将就无法获得数据了,所以说,zookeeper不能保证服务可用性,满足的是CP两个条件。
但是就服务发现这个场景来说,如果数据达不到一致性的要求,并不会造成什么灾难性后果,我们应该更看重的是服务的可用性,从这个方面考虑,AP是胜过CP的。这也是Spring Cloud Netflix在设计Eureka时遵守AP原则的原因。
4、浅谈链路跟踪
这是本文的最后一部分内容,也算是微服务领域的一个「高级话题」。
在笔者看来,调用链的跟踪算是一种运维手段,要做好这一部分的工作,并不是那么简单。
以往在单体应用环境下,所有的业务都在同一个服务器上,如果服务器出现错误和异常,我们只要盯住一个点,就可以快速定位和处理问题。
而微服务的架构已经决定了系统是在分布式环境下完成一系列的业务活动的,此时,对于问题的追踪和定位会变得比较麻烦。
链路跟踪工具常见于一些中大型的系统,因为人肉排查问题的效率实在是太低了。
即便不是排查问题,若PM想跟踪一下业务流,也会逐渐变得不可能了。
这是一张让人看了会产生不适感的图片:

这张图片描述的是各个服务节点的调用关系,很恐怖,对不对?
对于链路跟踪工具的实现,著名的有Twitter Zipkin,Google Dapper。至于工具的介绍,不在本文的讨论范畴内,笔者将会另起新篇。
总结
本文介绍了微服务架构风格的定义以及4个与微服务治理相关的技术概念,其实也是对于当下DevOps理念的一种体现。
希望对你有所帮助。
THANKS!
附:
参考文献:
6、我所了解的微服务

每日干货分享,传递互联网世界有价值的讯息,尽在「技术汇」。