一、创建SimpleFeatureTypes方式
import org.locationtech.geomesa.utils.geotools.SimpleFeatureTypes
SimpleFeatureTypes.createType("example", "name:String,dtg:Date,*geom:Point:srid=4326")
二、支持的数据类型
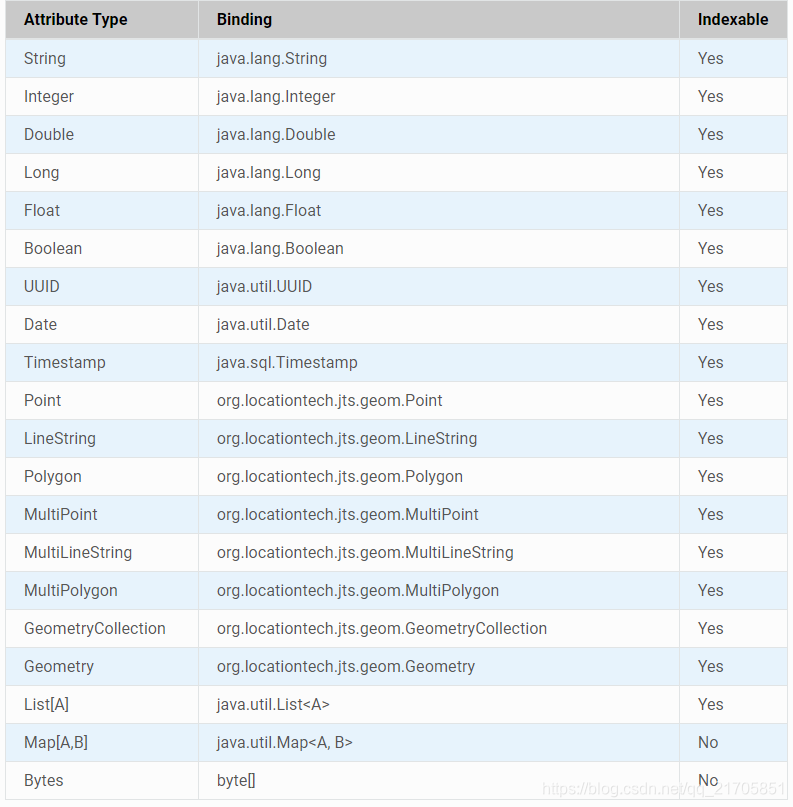
最后一列为是否可以作为索引
注:
1、只能索引一个几何类型的属性。
2、主日期类型属性既可以作为时空索引,又可以作为单独的属性索引。
3、列表类型可以被索引,但是查询列表类型可能会导致重复的结果
4、Geomesa会默认为时间和空间建立索引,也可以自己指定索引
三、索引类型
1、Z2索引:如果你的feature中有point这个类型,会自动创建Z2索引(使用二维曲线来索引经纬度点)
2、Z3索引:如果你的feature中有point和时间,会自动创建Z3索引(使用三维平面来索引经纬度点和时间)
3、XZ2索引:如果你的feature中有non-point这个类型,则自动创建XZ2索引(是Z索引的一个扩展,non-point是线段、多边形等)
4、XZ3索引:如果你的feature中有non-point和时间,会自动创建Z3索引
5、id索引:在 SimpleFeature.getID() 上建立id索引
6、属性索引
SimpleFeatureType. getgeometrydescriptor //返回几何图形。
四、建立属性索引
import org.locationtech.geomesa.utils.geotools.SchemaBuilder
val sft = SchemaBuilder.builder()
.addString("name").withIndex()//为name建立索引
.addDate("dtg")//日期类型
.addPoint("geom", default = true)//默认集合结构
.build("mySft")
五、SimpleFeatureType 表示方式
1.使用字符串表示
import org.locationtech.geomesa.utils.interop.SimpleFeatureTypes;
// append the user-data values to the end of the string, separated by a semi-colon
String spec = "name:String,dtg:Date,*geom:Point:srid=4326,option.one='foo',option.two='bar'";
SimpleFeatureType sft = SimpleFeatureTypes.createType("mySft", spec);
注:
*geom:Point:srid=4326:
*:默认空间几何
geom:属性名
Point:属性类型
srid:属性附加属性
=4326:值
多个属性之间用逗号分隔
2.通过配置文件表示:
geomesa {
sfts {
"mySft" = {
attributes = [
{ name = name, type = String, index = true }
{ name = dtg, type = Date }
{ name = geom, type = Point, srid = 4326 }
]
}
}}
3.对于已经建好的SimpleFeatureType 仍然可设置属性
// set the hint directly
SimpleFeatureType sft = ...
sft.getDescriptor("name").getUserData().put("index", "true");
六、设置索引的日期属性
// 指定当前属性的索引日期为'myDate'
sft1.getUserData().put("geomesa.index.dtg", "myDate");
// 禁用当前属性的索引日期
sft2.getUserData().put("geomesa.ignore.dtg", true);
七、自己指定索引
eomesa.indices.enabled 来指定,后边每个用冒号分隔。
import org.locationtech.geomesa.utils.interop.SimpleFeatureTypes;
String spec = "name:String,dtg:Date,*start:Point:srid=4326,end:Point:srid=4326";
SimpleFeatureType sft = SimpleFeatureTypes.createType("mySft",spec);
// 为 start + dtg建立Z3索引
sft.getUserData().put("geomesa.indices.enabled", "z3");
// 或者,在start + dtg上启用z3索引,在end + dtg上启用z3索引,在name上启用属性索引,在dtg上启用辅助索引。注意,这将覆盖前面的配置
sft.getUserData().put("geomesa.indices.enabled","z3:start:dtg,z3:end:dtg,attr:name:dtg");
import org.locationtech.geomesa.utils.geotools.SchemaBuilder
val sft = SchemaBuilder.builder()
.addString("name")
.addDate("dtg")
.addPoint("geom", default = true)//默认空间属性
.userData
.indices(List("id", "z3", "attr"))//建立哪些索引
.build("mySft")
八、指定id为uuid
sft.getUserData().put("geomesa.fid.uuid", "true");
datastore.createSchema(sft);
对于已经存在的SimpleFeatureType ,仍然可以指定id为uuid,但必须要指出不是使用geomesa.fid.uuid-encoded来序列化的:
SimpleFeatureType existing = datastore.getSchema("existing");
existing.getUserData().put("geomesa.fid.uuid","true");
existing.getUserData().put("geomesa.fid.uuid-encoded","false");
datastore.updateSchema("existing", existing);//更新schema
九、Geometry 的序列化
Geometry默认是使用WKB方式进行序列化的,也可是使用TWKB
磁盘上的TWKB将更小,但不允许完全双浮点精度。
对于point,TWKB将使用4-12字节(取决于指定的精度),而WKB使用18字节。
对于线段、多边形或其他具有多个坐标的几何图形,TWKB节省空间更多。
对于任何几何类型属性,都可以通过precision 设置浮点的精度来启用TWKB序列化。
精度表示要存储的小数位数,包括-7和7之间的小数位数。
负精度可以用来表示整数到小数点左边的四舍五入。经纬度精度的6位数字可以存储大约10cm的分辨率。
对于二维以上的几何形状,可以分别指定Z维和M维的精度。
通常,这些维度不需要以与X/Y相同的分辨率存储。
默认情况下,Z的精度为1,M的精度为0。
要更改这一点,请在X/Y精度之后指定附加精度,并用逗号分隔。
Z和M的精度必须在0到7之间(含7)。
例如,6,1,0将X/Y精度设为6,Z精度设为1,M精度设为0。
可以在创建新模式时设置TWKB序列化,也可以通过updateSchema方法随时启用。如果修改现有schema,则不会更新已经编写的任何数据。
SimpleFeatureType sft = ...
sft.getDescriptor("geom").getUserData().put("precision", "4");//指定经度为4
十、配置列组
将属性的子集复制到单独的列组中
这样,查询时可以只扫描列组,避免从磁盘读取未使用的数据。
对于具有大量属性的情况,可加快一些查询的速度,代价是向磁盘写入更多的数据。
属性可以属于多个列组,在这种情况下,它将被复制多次。
所有属性将属于默认列组,而无需指定任何东西。
列组使用column-groups指定
列组名尽可能短(理想情况下为单个字符),以便最小化磁盘使用。
如果列组与GeoMesa使用的默认组之一发生冲突,则在创建模式时将抛出异常。目前,HBase的保留组为d, Accumulo的保留组为F、A、I和B。(也就是在自己指定列组名时,HBase别用d,。。。)
例:
import org.locationtech.geomesa.utils.geotools.SchemaBuilder
val sft = SchemaBuilder.builder()
.addString("name").withColumnGroups("a")//设置列组
.addDate("dtg").withColumnGroups("a", "b")//设置列组
.addPoint("geom", default = true).withColumnGroups("a", "b")//设置列组
.build("mySft")
十一、Z索引分片
可将Z2/Z3/XZ2/XZ3索引进行切分。
对于每个SimpleFeatureType,可以单独更改此参数。如果没有指定,geomesa将默认为4个碎片。碎片的数量必须在1到127之间。
将碎片的数量设置得过高会降低性能,因为它需要对每个查询执行更多的计算。
调用createSchema时,可以使用geomesa.z.split指定数量。
sft.getUserData().put("geomesa.z.splits", "4");
十二、Z索引时间间隔
在基于时间进行查询时使用z-curve索引。
默认情况下,时间被划分为长达一周的块,并按周索引。
也可自己指定时间间隔,有四种间隔——day、week、month或year。
随着间隔越来越大,必须检查的查询分区也越来越少,但是每个间隔的精度会下降。
如果您通常一次查询几个月的数据,那么每月索引可能提供更好的性能。
如果您通常一次查询几分钟的数据,那么每天索引可能更快。
默认的每周分区为大多数场景提供了良好的平衡。
注意,最佳分区取决于查询模式,而不是数据的分布。
调用createSchema时设置时间间隔。它可以使用 geomesa.z3.interval来指定。
sft.getUserData().put("geomesa.z3.interval", "month");
十三、XZ索引的精度
GeoMesa使用XZ索引来存储具有区段的几何图形。
可以通过指定用于存储几何图形的分辨率级别来定制索引。
默认情况下,分辨率级别为12。
几何图形比较大则可以降低这个值
几何图形比较小则可以提高这个值
sft.getUserData().put("geomesa.xz.precision", 12);
十四、属性索引分片
对于每个SimpleFeatureType,可以单独更改属性索引的分片数。
默认4个分片,数量必须在1到127之间
通过geomesa.attro.split设置分片数量。
sft.getUserData().put("geomesa.attr.splits", "4");
十五、属性优先级、
要设置属性的优先级,使用属性上的cardinality ,其值为高或低。
例:
import org.locationtech.geomesa.utils.geotools.SchemaBuilder
import org.locationtech.geomesa.utils.stats.Cardinality
val sft = SchemaBuilder.builder()
.addString("name").withIndex(Cardinality.HIGH)//设置高优先级
.addDate("dtg")
.addPoint("geom", default = true)
.build("mySft")
十六、分区索引
可将每个feature的每个属性索引划分为单独的表。
为一个索引拥有多个表可以简化集群的管理
使用geomesa.table.partition指定,只等根据时间进行分区
import org.locationtech.geomesa.utils.geotools.SchemaBuilder
val sft = SchemaBuilder.builder()
.addString("name")
.addDate("dtg")
.addPoint("geom", default = true)
.userData
.partitioned()//将表按时间进行分区
.build("mySft")
注意,要启用分区,必须包含一个默认日期字段。
启用分区时,每个索引将由多个物理表组成。表是根据Z索引分区的,需要时动态创建表。
分区表仍然可以预先拆分。
对于Z3分割,最小/最大日期配置由分区自动确定,不需要指定。
当查询必须扫描多个表时,默认情况下将按顺序扫描这些表。
若要并行扫描表,通过geomesa.part .scan.parallel=true。
注意,当启用时,跨多个分区的查询可能会给系统带来很大的负载。
十七、索引切片
当计划摄取大量数据时,如果预先知道分布情况,那么在编写之前对表进行预分割是很有用的。
这从一开始就提供了跨集群的并行性,并且不依赖于实现触发器(通常根据大小拆分表)。
分割是通过org.locationtech.geomesa.index.conf.TableSplitter 接口实现的
十八、指定表拆分器
调用createSchema之前,在创建简单的特性类型时,可以通过用户数据指定表拆分器。
要指示table splitter类,使用 table.splitter.class:
sft.getUserData().put("table.splitter.class", "org.example.CustomSplitter");
要指示给定的表拆分器的任何选项,使用 table.splter.options:
sft.getUserData().put("table.splitter.options", "foo,bar,baz");
十九、默认的表拆分器
通常,table.splitter.class可以省略。
如果是这样,GeoMesa将使用一个默认实现,通过table.splitter.options配置。
如果没有指定选项,那么所有表通常都会创建4个split。
二十、Z3 / XZ3切分
日期是根据Z3时间前缀(通常是星期)来分割的。
它们以yyyy-MM-dd的形式指定。
如果指定了最小日期,但没有指定最大日期,则默认为当前日期。
在日期之后,Z索引可以基于若干位进行分割
(注意,由于索引格式的原因,没有日期不能指定位)。
例如,指定两个位将创建分割00、01、10和11。所创建的分割的总数将是
Z分片数时间周期数2 ^bits数
二十一、Z2 / XZ2切分
如果给定任何选项,则必须指定位的数目。
例如,指定两个位将创建分割00、01、10和11。所创建的分割的总数将是
Z分片数*2 ^bits数
二十二、Id和属性切分
分割由schame定义。
对于ID索引,schame应用于单个feature ID。
对于属性索引,通过将属性名指定为选项的一部分,可以分别配置索引的每个属性。
schame由一个或多个用方括号括起来的字符或范围组成。
格式:
有效字符可以是数字0到9中的任意一个,也可以是字母a到z中的任意一个(大写或小写)。
范围是由破折号分隔的两个字符。
每一组括号对应一个字符,允许嵌套分割。
schame[0-9]将基于数字0到9创建10个分割。
schame[0-9][0-9]将创建100个分割。
schame[0-9a-f]将基于小写十六进制字符创建16个分割。
模式[0-9A-F]将对大写字符执行相同的操作。
对于热点数据,可以通过在键后面添加附加选项2,3等来指定多个模式。例如,如果大多数名称值以字母f和t开头,则可以将分隔符指定为
attr.name.pattern:[a-z],attr.name.pattern2:[f][a-z],attr.name.pattern3:[t][a-z]
对于数字类型属性,只有数字被认为是有效字符。
**正常的数字前缀将无法正常工作。**例如,如果数据的数字在8000-9000之间,指定[8-9][0-9]将不能正确地分割数据。相反,应该添加尾随零以达到适当的长度,例如[8-9][0-9][0][0]。
完整实例
import org.locationtech.geomesa.utils.interop.SimpleFeatureTypes;
String spec = "name:String:index=true,age:Int:index=true,dtg:Date,*geom:Point:srid=4326";
SimpleFeatureType sft = SimpleFeatureTypes.createType("foo", "spec");
sft.getUserData().put("table.splitter.options","id.pattern:[0-9a-f],attr.name.pattern:[a-z],z3.min:2018-01-01,z3.max:2018-01-31,z3.bits:2,z2.bits:4");
二十三、配置查询拦截器
拦截查询,
可以在调用createSchema之前设置,或者通过调用updateSchema进行更新。
通过geomesa.query.interceptors指定
sft.getUserData().put("geomesa.query.interceptors", "com.example.MyQueryInterceptor");
该值必须是一个逗号分隔的字符串,由实现org.locationtech.geomesa.index.planning.QueryInterceptor的一个或多个类的名称组成:
/**
* Provides a hook to modify a query before executing it
*/
trait QueryInterceptor extends Closeable {
/**
* Called exactly once after the interceptor is instantiated
*
* @param ds data store
* @param sft simple feature type
*/
def init(ds: DataStore, sft: SimpleFeatureType): Unit
/**
* Modifies the query in place
* @param query query
*/
def rewrite(query: Query): Unit}
拦截器必须有一个默认的无参数构造函数。拦截器的生命周期包括:
1、实例通过反射实例化,使用它的默认构造函数
2、实例通过init方法初始化,反复调用包含简单特性类型重写的数据存储
3、通过close方法清理实例
二十四、复杂的几何类型
如果默认的几何体类型是Geometry (即同时支持point 和non-point 特性),则必须显式启用“mixed”索引模式。。
调用createSchema时必须声明混合几何。使用geomesa.mix.geometries指定
sft.getUserData().put("geomesa.mixed.geometries", "true");