让我们考虑一个简单的编程挑战:对大数组中的所有元素求和。现在可以通过使用并行性来轻松优化这一点,特别是对于具有数千或数百万个元素的巨大阵列,还有理由认为,并行处理时间应该与常规时间除以CPU核心数一样多。事实证明,这一壮举并不容易实现。我将向您展示几种并行执行此操作的方法,它们如何改善或降低性能以及以某种方式影响性能的所有细节。
简单的循环方法
private const int ITEMS = 500000; private int[] arr = null; public ArrayC() { arr = new int[ITEMS]; var rnd = new Random(); for (int i = 0; i < ITEMS; i++) { arr[i] = rnd.Next(1000); } } public long ForLocalArr() { long total = 0; for (int i = 0; i < ITEMS; i++) { total += int.Parse(arr[i].ToString()); } return total; } public long ForeachLocalArr() { long total = 0; foreach (var item in arr) { total += int.Parse(item.ToString()); } return total; }
只需要迭代循环就可以计算出结果,超级简单,这里没有用直接相加求出结果,原因是直接求出结果,发现每次基本的运行都比并行快,但是实际上,并行处理没有那么简单,所以这里的加法就简单的处理下total += int.Parse(arr[i].ToString())。现在,让我们尝试用并行性来打败数组迭代吧。
首次尝试
private object _lock = new object(); public long ThreadPoolWithLock() { long total = 0; int threads = 8; var partSize = ITEMS / threads; Task[] tasks = new Task[threads]; for (int iThread = 0; iThread < threads; iThread++) { var localThread = iThread; tasks[localThread] = Task.Run(() => { for (int j = localThread * partSize; j < (localThread + 1) * partSize; j++) { lock (_lock) { total += arr[j]; } } }); } Task.WaitAll(tasks); return total; }
请注意,您必须使用localThread变量来“保存”该iThread时间点的值。否则,它将是一个随着for循环前进而变化的捕获变量。当数据最后打的时候并行已经比普通的快了,但是发现快的不多,说明还可以优化
再次优化
public long ThreadPoolWithLock2() { long total = 0; int threads = 8; var partSize = ITEMS / threads; Task[] tasks = new Task[threads]; for (int iThread = 0; iThread < threads; iThread++) { var localThread = iThread; tasks[localThread] = Task.Run(() => { long temp = 0; for (int j = localThread * partSize; j < (localThread + 1) * partSize; j++) { temp += int.Parse(arr[j].ToString()); } lock (_lock) { total += temp; } }); } Task.WaitAll(tasks); return total; }
增加设置临时变量,减少lock次数,发现运行效果已经有质的提高,提高了几倍。忽然想起,有个Parallel.For的方法,研究性能是否可以更快。
Parallel.For优化
public long ParallelForWithLock() { long total = 0; int parts = 8; int partSize = ITEMS / parts; var parallel = Parallel.For(0, parts, new ParallelOptions(), (iter) => { long temp = 0; for (int j = iter * partSize; j < (iter + 1) * partSize; j++) { temp += int.Parse(arr[j].ToString()); } lock (_lock) { total += temp; } }); return total; }
运行结果比普通迭代快,但是没有ThreadPool快,但是觉得Parallel.For还可以继续优化,也许可以更快
Parallel.For继续优化
public long ParallelForWithLock2() { long total = 0; int parts = 8; int partSize = ITEMS / parts; var parallel = Parallel.For(0, parts, localInit: () => 0L, // Initializes the "localTotal" body: (iter, state, localTotal) => { for (int j = iter * partSize; j < (iter + 1) * partSize; j++) { localTotal += int.Parse(arr[j].ToString()); } return localTotal; }, localFinally: (localTotal) => { total += localTotal; }); return total; }
运行效果已经很快,和ThreadPool优化过的差不多,有些时候更快
结论和总结
并行化优化肯定可以提高性能,但是这取决于很多因素,每个案例都应该进行测量和检查。
当各种线程需要通过某种锁定机制相互依赖时,性能会显着降低。
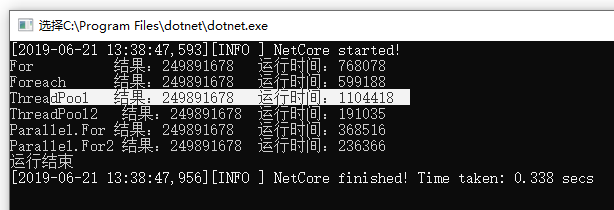
50万数据运行结果