今天带大家简单的了解一下MQ(消息队列 Message Queue)的简单理论知识。
什么是MQ
消息队列(Message Queue,简称MQ),从字面意思上看,本质是个队列,FIFO先入先出,只不过队列中存放的内容是message而已。
其主要用途:不同进程Process/线程Thread之间进行通信。
如图:
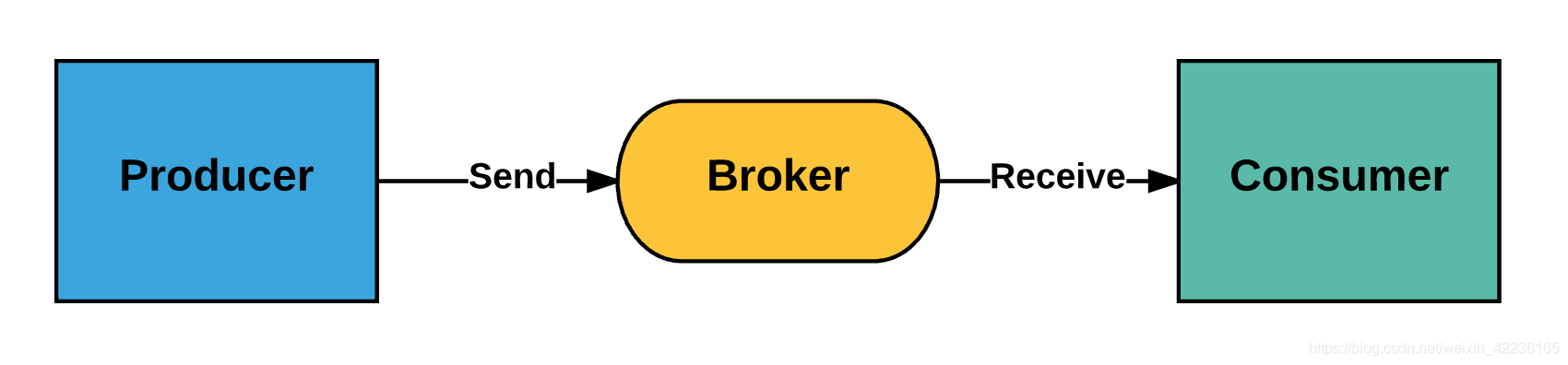
Producer:消息生产者,负责产生和发送消息到 Broker;
Broker:消息处理中心。负责消息存储、确认、重试等,一般其中会包含多个 queue;
Consumer:消息消费者,负责从 Broker 中获取消息,并进行相应处理;
特性:
异步性
将耗时的同步操作,通过以发送消息的方式,进行了异步化处理。减少了同步等待的时间。
松耦合
消息队列减少了服务之间的耦合性,不同的服务可以通过消息队列进行通信,而不用关心彼此的实现细节,只要定义好消息的格式就行。
分布式
通过对消费者的横向扩展,降低了消息队列阻塞的风险,以及单个消费者产生单点故障的可能性(当然消息队列本身也可以做成分布式集群)。
可靠性
消息队列一般会把接收到的消息存储到本地硬盘上(当消息被处理完之后,存储信息根据不同的消息队列实现,有可能将其删除),这样即使应用挂掉或者消息队列本身挂掉,消息也能够重新加载。
为什么会产生消息队列
1.不同进程(process)之间传递消息时,两个进程之间耦合程度过高,改动一个进程,引发必须修改另一个进程,为了隔离这两个进程,在两进程间抽离出一层(一个模块),所有两进程之间传递的消息,都必须通过消息队列来传递,单独修改某一个进程,不会影响另一个;
2.不同进程(process)之间传递消息时,为了实现标准化,将消息的格式规范化了,并且,某一个进程接受的消息太多,一下子无法处理完,并且也有先后顺序,必须对收到的消息进行排队,因此诞生了事实上的消息队列;
MQ的缺陷
1)系统更复杂,多了一个MQ组件
2)消息传递路径更长,延时会增加
3)消息可靠性和重复性互为矛盾,消息不丢不重难以同时保证
4)上游无法知道下游的执行结果,这一点是很致命的
调用方实时依赖执行结果的业务场景,请使用调用,而不是MQ。
MQ的优点
1)不需要预留buffer,上游任务执行完,下游任务总会在第一时间被执行
2)依赖多个任务,被多个任务依赖都很好处理,只需要订阅相关消息即可
3)有任务执行时间变化,下游任务都不需要调整执行时间
MQ只用来传递上游任务执行完成的消息,并不用于传递真正的输入输出数据。
什么时候不使用MQ
上游实时关注执行结果
什么时候使用MQ
1)数据驱动的任务依赖
2)上游不关心多下游执行结果
3)异步返回执行时间长
MQ框架非常多,比较流行的有RabbitMq、ActiveMq、ZeroMq、kafka,以及阿里开源的RocketMQ。