聚合函数
聚合函数(aggregate function)针对一组数据行进行运算,并且返回一条结果。PostgreSQL 支持以下常见的聚合函数:
- AVG - 计算一组值的平均值
- COUNT - 统计一组值的数量
- MAX - 计算一组值的最大值
- MIN - 计算一组值的最小值
- SUM - 计算一组值的和值
- STRING_AGG - 连接一组字符串
以下示例分别返回了 IT 部门所有员工的平均薪水、员工总数、最高薪水、最低薪水、以及薪水总计:
SELECT AVG(salary),
COUNT(*),
MAX(salary),
MIN(salary),
SUM(salary)
FROM employees
WHERE department_id = 60;
avg |count|max |min |sum |
---------------------|-----|-------|-------|--------|
5760.0000000000000000| 5|9000.00|4200.00|28800.00|
关于聚合函数,需要注意两点:
- 函数参数前添加
DISTINCT可以在计算时排除重复值。 - 忽略参数中的 NULL 值。
来看以下查询:
SELECT COUNT(*),
COUNT(DISTINCT salary),
COUNT(commission_pct)
FROM employees
WHERE department_id = 60;
count|count|count|
-----|-----|-----|
5| 4| 0|
其中,COUNT(*) 返回了该部门员工的总数(5),COUNT(DISTINCT salary) 返回了薪水不相同的员工数量(4),COUNT(commission_pct) 返回了佣金百分比不为空值的数量(0),该部门员工都没有佣金提成。
以下示例使用STRING_AGG将 IT 部门员工的名字使用分号进行分隔,按照薪水从高到底排序后连接成一个字符串:
SELECT STRING_AGG(first_name, ';' ORDER BY salary DESC)
FROM employees
WHERE department_id = 60;
string_agg |
---------------------------------|
Alexander;Bruce;David;Valli;Diana|
更多的聚合函数可以参考官方文档。
分组聚合
我们已经获得了 IT 部门的一些汇总信息,如果还需要知道其他部门的相关信息,可以多次运行相同的查询(修改查询条件中的部门编号)。但是这种明显过于复杂,不适合实际应用。SQL 为此提供了GROUP BY子句,它用于将数据分成多个组,然后使用聚合函数对每个组进行汇总。
举例来说,如果想要知道每个部门内所有员工的平均薪水、员工总数、最高薪水、最低薪水、以及薪水总计,可以使用以下查询语句:
SELECT department_id,
AVG(salary),
COUNT(*),
MAX(salary),
MIN(salary),
SUM(salary)
FROM employees
GROUP BY department_id
ORDER BY department_id;
department_id|avg |count|max |min |sum |
-------------|----------------------|-----|--------|--------|---------|
10| 4400.0000000000000000| 1| 4400.00| 4400.00| 4400.00|
20| 9500.0000000000000000| 2|13000.00| 6000.00| 19000.00|
30| 4150.0000000000000000| 6|11000.00| 2500.00| 24900.00|
40| 6500.0000000000000000| 1| 6500.00| 6500.00| 6500.00|
50| 3475.5555555555555556| 45| 8200.00| 2100.00|156400.00|
60| 5760.0000000000000000| 5| 9000.00| 4200.00| 28800.00|
70|10000.0000000000000000| 1|10000.00|10000.00| 10000.00|
80| 8955.8823529411764706| 34|14000.00| 6100.00|304500.00|
90| 19333.333333333333| 3|24000.00|17000.00| 58000.00|
100| 8601.3333333333333333| 6|12008.00| 6900.00| 51608.00|
110|10154.0000000000000000| 2|12008.00| 8300.00| 20308.00|
| 7000.0000000000000000| 1| 7000.00| 7000.00| 7000.00|
查询执行时,首先根据GROUP BY子句中的列(department_id)进行分组,然后使用聚合函数汇总组内的数据。最后一条数据是针对部门编号字段为空的数据进行的分组汇总,GROUP BY将所有的 NULL 值分为一组。
GROUP BY并不一定需要与聚合函数一起使用,例如:
SELECT department_id
FROM employees
GROUP BY department_id
ORDER BY department_id;
department_id|
-------------|
10|
20|
30|
40|
50|
60|
70|
80|
90|
100|
110|
|
查询的结果就是不同的部门编号分组,这种查询的结果与DISTINCT效果相同:
SELECT DISTINCT department_id
FROM employees
ORDER BY department_id;
GROUP BY不仅可以按照一个字段进行分组,也可以使用多个字段将数据分成更多的组。例如,以下查询将员工按照不同的部门和职位组合进行分组,然后进行汇总:
SELECT department_id,
job_id,
AVG(salary),
COUNT(*),
MAX(salary),
MIN(salary),
SUM(salary)
FROM employees
GROUP BY department_id, job_id
ORDER BY department_id, job_id;
department_id|job_id |avg |count|max |min |sum |
-------------|----------|----------------------|-----|--------|--------|---------|
10|AD_ASST | 4400.0000000000000000| 1| 4400.00| 4400.00| 4400.00|
20|MK_MAN |13000.0000000000000000| 1|13000.00|13000.00| 13000.00|
20|MK_REP | 6000.0000000000000000| 1| 6000.00| 6000.00| 6000.00|
30|PU_CLERK | 2780.0000000000000000| 5| 3100.00| 2500.00| 13900.00|
30|PU_MAN |11000.0000000000000000| 1|11000.00|11000.00| 11000.00|
40|HR_REP | 6500.0000000000000000| 1| 6500.00| 6500.00| 6500.00|
50|SH_CLERK | 3215.0000000000000000| 20| 4200.00| 2500.00| 64300.00|
50|ST_CLERK | 2785.0000000000000000| 20| 3600.00| 2100.00| 55700.00|
50|ST_MAN | 7280.0000000000000000| 5| 8200.00| 5800.00| 36400.00|
60|IT_PROG | 5760.0000000000000000| 5| 9000.00| 4200.00| 28800.00|
70|PR_REP |10000.0000000000000000| 1|10000.00|10000.00| 10000.00|
80|SA_MAN | 12200.000000000000| 5|14000.00|10500.00| 61000.00|
80|SA_REP | 8396.5517241379310345| 29|11500.00| 6100.00|243500.00|
90|AD_PRES | 24000.000000000000| 1|24000.00|24000.00| 24000.00|
90|AD_VP | 17000.000000000000| 2|17000.00|17000.00| 34000.00|
100|FI_ACCOUNT| 7920.0000000000000000| 5| 9000.00| 6900.00| 39600.00|
100|FI_MGR |12008.0000000000000000| 1|12008.00|12008.00| 12008.00|
110|AC_ACCOUNT| 8300.0000000000000000| 1| 8300.00| 8300.00| 8300.00|
110|AC_MGR |12008.0000000000000000| 1|12008.00|12008.00| 12008.00|
|SA_REP | 7000.0000000000000000| 1| 7000.00| 7000.00| 7000.00|
使用了GROUP BY子句进行分组操作之后需要注意一点,就是SELECT列表中只能出现分组字段或者聚合函数,不能再出现表中的其他字段。下面是一个错误的示例:
SELECT department_id,
job_id,
AVG(salary),
COUNT(*),
MAX(salary),
MIN(salary),
SUM(salary)
FROM employees
GROUP BY department_id;
SQL 错误 [42803]: ERROR: column "employees.job_id" must appear in the GROUP BY clause or be used in an aggregate function
Position: 31
错误的原因在于 job_id 既不是分组的条件,也不是聚合函数。查询要求按照部门进行分组汇总,但是每个部门存在多个不同的职位,数据库无法知道需要显示哪个职位编号。
分组过滤
当我们需要针对分组汇总后的数据再次进行过滤时,例如找出平均薪水值大于 10000 的部门,直观的想法就是在WHERE子句中增加一个过滤条件,例如:
SELECT department_id,
AVG(salary),
COUNT(*),
MAX(salary),
MIN(salary),
SUM(salary)
FROM employees
WHERE AVG(salary) > 10000
GROUP BY department_id
ORDER BY department_id;
SQL 错误 [42803]: ERROR: aggregate functions are not allowed in WHERE
Position: 150
不过查询并没有返回期望的结果,而是出现了一个错误:WHERE子句中不允许出现聚合函数。因为在 SQL 询中,如果同时存在WHERE子句和GROUP BY子句,WHERE子句在GROUP BY子句之前执行。因此,WHERE子句无法对分组后的结果进行过滤。
WHERE子句执行时还没有进行分组计算,它只能基于分组之前的数据进行过滤。如果需要对分组后的结果进行过滤,需要使用HAVING子句。以上查询的正确写法如下:
SELECT department_id,
AVG(salary),
COUNT(*),
MAX(salary),
MIN(salary),
SUM(salary)
FROM employees
GROUP BY department_id
HAVING AVG(salary) > 10000
ORDER BY department_id;
department_id|avg |count|max |min |sum |
-------------|----------------------|-----|--------|--------|--------|
90| 19333.333333333333| 3|24000.00|17000.00|58000.00|
110|10154.0000000000000000| 2|12008.00| 8300.00|20308.00|
HAVING出现在GROUP BY之后,也在它之后执行,因此能够使用聚合函数进行过滤。
我们可以同时使用WHERE子句进行数据行的过滤,使用HAVING进行分组结果的过滤。以下示例用于查找哪些部门中薪水大于 10000 的员工的数量多于 2 个:
SELECT department_id,
COUNT(*) AS headcount
FROM employees
WHERE salary > 10000
GROUP BY department_id
HAVING COUNT(*) > 2;
department_id|headcount|
-------------|---------|
80| 8|
90| 3|
查询时,首先通过WHERE子句找出薪水大于 10000 的所有员工;然后,按照部门编号进行分组,计算每个组内的员工数量;最后,使用HAVING子句过滤员工数量多于 2 个人的部门。
高级选项
PostgreSQL 除了支持基本的GROUP BY分组操作之外,还支持 3 种高级的分组选项:GROUPING SETS、ROLLUP以及CUBE。
GROUPING SETS 选项
GROUPING SETS是GROUP BY的扩展选项,用于指定自定义的分组集。举例来说,以下是一个销售数据表:
CREATE TABLE sales (
item VARCHAR(10),
year VARCHAR(4),
quantity INT
);
INSERT INTO sales VALUES('apple', '2018', 800);
INSERT INTO sales VALUES('apple', '2018', 1000);
INSERT INTO sales VALUES('banana', '2018', 500);
INSERT INTO sales VALUES('banana', '2018', 600);
INSERT INTO sales VALUES('apple', '2019', 1200);
INSERT INTO sales VALUES('banana', '2019', 1800);
按照产品(item)和年度(year)进行分组汇总时,所有可能的 4 种分组集包括:
- 按照产品和年度的组合进行分组;
- 按照产品进行分组;
- 按照年度进行分组;
- 所有数据分为一组。
可以通过以下多个查询获取所有分组集的分组结果:
-- 按照产品和年度的组合进行分组
SELECT item, year, SUM(quantity)
FROM sales
GROUP BY item, year;
item |year|sum |
------|----|----|
banana|2019|1800|
apple |2019|1200|
apple |2018|1800|
banana|2018|1100|
-- 按照产品进行分组
SELECT item, NULL AS year, SUM(quantity)
FROM sales
GROUP BY item;
item |year|sum |
------|----|----|
banana| |2900|
apple | |3000|
-- 按照年度进行分组
SELECT NULL AS item, year, SUM(quantity)
FROM sales
GROUP BY year;
item|year|sum |
----|----|----|
|2018|2900|
|2019|3000|
-- 所有数据分为一组
SELECT NULL AS item, NULL AS year, SUM(quantity)
FROM sales;
item|year|sum |
----|----|----|
| |5900|
为了统一显示,查询中增加了一些 NULL 值列。在后续的文章中我们会介绍如何使用集合运算符(UNION ALL)将 4 个查询结果合并到一起。但是这种方法存在一些问题:首先,查询语句比较冗长,查询的次数随着分组字段的增加呈指数增长;其次,多次查询意味着需要多次扫描同一张表,存在性能上的问题。
GROUPING SETS是GROUP BY的扩展选项,能够为这种查询需求提供更加简单有效的解决方法。我们使用分组集改写上面的示例:
SELECT item, year, SUM(quantity)
FROM sales
GROUP BY GROUPING SETS (
(item, year),
(item),
(year),
()
);
item |year|sum |
------|----|----|
| |5900|
banana|2019|1800|
apple |2019|1200|
apple |2018|1800|
banana|2018|1100|
banana| |2900|
apple | |3000|
|2018|2900|
|2019|3000|
GROUPING SETS选项用于定义分组集,每个分组集都需要包含在单独的括号中,空白的括号(())表示将所有数据当作一个组处理。查询的结果等于前文 4 个查询的合并结果,但是语句更少,可读性更强;而且 PostgreSQL 执行时只需要扫描一次销售表,性能更加优化。
另外,默认的GROUP BY使用的是由所有分组字段构成的一个分组集,本示例中为 (item, year)。
CUBE 选项
随着分组字段的增加,即使通过GROUPING SETS列出所有可能的分组方式也会显得比较麻烦。设想一下使用 4 个字段进行分组统计的场景,所有可能的分组集共计有 16 个。这种情况下编写查询语句仍然很复杂,为此 PostgreSQL 提供了简写形式的GROUPING SETS:CUBE和ROLLUP。
CUBE表示所有可能的分组集,例如:
CUBE ( c1, c2, c3 )
等价于:
GROUPING SETS (
( c1, c2, c3 ),
( c1, c2 ),
( c1, c3 ),
( c2, c3 ),
( c1 ),
( c2 ),
( c3 ),
( )
)
因此,我们可以进一步将上面的示例改写如下:
SELECT item, year, SUM(quantity)
FROM sales
GROUP BY CUBE (item,year);
item |year|sum |
------|----|----|
| |5900|
banana|2019|1800|
apple |2019|1200|
apple |2018|1800|
banana|2018|1100|
banana| |2900|
apple | |3000|
|2018|2900|
|2019|3000|
ROLLUP 选项
GROUPING SETS第二种简写形式就是ROLLUP,用于生成按照层级进行汇总的结果,类似于财务报表中的小计、合计和总计。例如:
ROLLUP ( c1, c2, c3 )
等价于:
GROUPING SETS (
( c1, c2, c3 ),
( e1, e2 ),
( e1 ),
( )
)
以下查询返回按照产品和年度组合进行统计的销量小计,加上按照产品进行统计的销量合计,再加上所有销量的总计:
SELECT item, year, SUM(quantity)
FROM sales
GROUP BY ROLLUP (item,year);
item |year|sum |
------|----|----|
| |5900|
banana|2019|1800|
apple |2019|1200|
apple |2018|1800|
banana|2018|1100|
banana| |2900|
apple | |3000|
查看结果时,需要根据每个字段上的空值进行判断。比如第一行的产品和年度都为空,因此它是所有销量的总计。为了便于查看,可以将空值进行转换显示:
SELECT coalesce(item, '所有产品') AS "产品",
coalesce(year, '所有年度') AS "年度",
SUM(quantity) as "销量"
FROM sales
GROUP BY ROLLUP (item,year);
产品 |年度 |销量 |
------|----|----|
所有产品|所有年度|5900|
banana |2019 |1800|
apple |2019 |1200|
apple |2018 |1800|
banana |2018 |1100|
banana |所有年度|2900|
apple |所有年度|3000|
COALESCE 函数返回第一个非空的参数值。
可以根据需要返回按照某些组合进行统计的结果,以下查询返回按照产品和年度组合进行统计的销量小计,加上按照产品进行统计的销量合计:
SELECT coalesce(item, '所有产品') AS "产品",
coalesce(year, '所有年度') AS "年度",
SUM(quantity) as "销量"
FROM sales
GROUP BY item, ROLLUP (year);
产品 |年度 |销量 |
------|----|----|
banana |2019 |1800|
apple |2019 |1200|
apple |2018 |1800|
banana |2018 |1100|
banana |所有年度|2900|
apple |所有年度|3000|
对于CUBE和ROLLUP而言,每个元素可以是单独的字段或表达式,也可以是使用括号包含的列表。如果是括号中的列表,产生分组集时它们必须作为一个整体。例如:
CUBE ( (c1, c2), (c3, c4) )
等价于:
GROUPING SETS (
( c1, c2, c3, c4 ),
( c1, c2 ),
( c3, c4 ),
( )
)
因为 c1 和 c2 是一个整体,c3 和 c4 是一个整体。
同样:
ROLLUP ( c1, (c2, c3), c4 )
等价于:
GROUPING SETS (
( c1, c2, c3, c4 ),
( c1, c2, c3 ),
( c1 ),
( )
)
GROUPING 函数
虽然有时候可以通过空值来判断数据是不是某个字段上的汇总,比如说按照年度进行统计的结果在字段 year 上的值为空。但是情况并非总是如此,考虑以下示例:
-- 未知产品在 2018 年的销量为 5000
INSERT INTO sales VALUES(NULL, '2018', 5000);
SELECT coalesce(item, '所有产品') AS "产品",
coalesce(year, '所有年度') AS "年度",
SUM(quantity) as "销量"
FROM sales
GROUP BY ROLLUP (item,year);
查询结果如下:
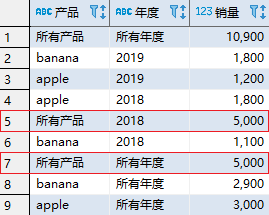
其中第 5 行和第 7 行的显示存在问题,它们分别应该是未知产品在 2018 年的销量小计和所有年度的销量合计。问题的关键在于无法区分是分组产生的 NULL 值还是源数据中的 NULL 值。为了解决这个问题,PostgreSQL 提供了一个分组函数:GROUPING。
以下查询显示了GROUPING函数的结果:
SELECT item AS "产品",
year AS "年度",
SUM(quantity) as "销量",
GROUPING(item),
GROUPING(year),
GROUPING(item, year)
FROM sales
GROUP BY ROLLUP (item,year);
返回的结果如下:

GROUPING函数如果只有一个参数,返回整数 0 或者 1。如果某个统计结果使用的分组集包含了函数中的参数字段,该函数返回 0,否则返回 1。比如说,第 1 行数据是所有产品所有年度的统计(分组集为空),所以 GROUPING(item) 和 GROUPING(year) 结果都是 1;第 7 行数据是未知产品所有年度的统计(分组集为 ( item, )),所以 GROUPING(item) 结果为 0,GROUPING(year) 结果为 1。
GROUPING函数如果包含多个参数,针对每个参数返回整数 0 或者 1,然后将它们按照二进制数值连接到一起。比如说,第 1 行数据中的 GROUPING(item, year) 结果等于 GROUPING(item) 和 GROUPING(year) 结果的二进制数值连接,也就是 3(二进制的 11)。
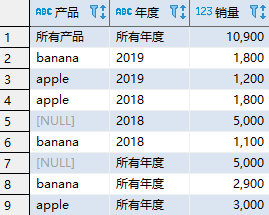
通过使用GROUPING函数,我们可以正确显示分组中的 NULL 值和源数据中的 NULL 值:
SELECT CASE GROUPING(item) WHEN 1 THEN '所有产品' ELSE item END AS "产品",
CASE GROUPING(year) WHEN 1 THEN '所有年度' ELSE year END AS "年度",
SUM(quantity) as "销量"
FROM sales
GROUP BY ROLLUP (item,year);
该查询的结果如下:
人生本来短暂,你又何必匆匆!点个赞再走吧!