HTTP是什么?
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
其传输层由 TCP 协议提供支持。
请求报文
请求报文的结构和一个简单的例子如下图所示

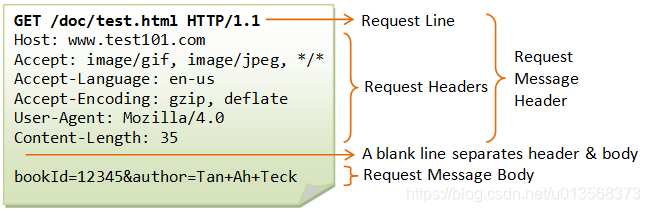
先宏观的看请求报文,之后本文会对一些比较重要的地方进行细致的介绍。
请求报文可以被分为四个部分
- 请求行
- 首部字段
- 空行
- 请求正文
其中第三部分,空行,用来分割首部字段和请求正文这两部分,而且不管有没有请求正文,这个空行都要有!
第四部分,请求正文,是承载请求数据的部分,比如常用的 POST 请求方法,它携带的参数就保存在这里。
现在我们来细致的看下,第一部分和第二部分。
第一部分:请求行
第一部分,第一行,也就是 Request Line(请求行),主要有三个内容分别如下:
- 请求方法
- 请求的资源(URL)
- HTTP 协议的版本号
在介绍请求方法之前,非常有必要先将 URL 这个概念理清。所以我们以 URL、请求方法、HTTP 协议版本这个顺序来解读请求行。
一、URL
URL,全称是 Uniform Resource Locator, 中文叫统一资源定位符,是互联网上用来标识某一处资源的地址。
这部分的内容参考下面这位老哥的文章,我觉得总结的非常清晰且详细,这里直接将内容搬运过来,如果侵权,请通知我删除,下面是原文链接。
以下面这个 URL 为例,介绍下普通 URL 的各部分组成
http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name
从上面的URL可以看出,一个完整的URL包括以下几部分:
1、协议部分:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在"HTTP"后面的“//”为分隔符
2、域名部分:该URL的域名部分为“www.aspxfans.com”。一个URL中,也可以使用IP地址作为域名使用
3、端口部分:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口80
4、虚拟目录部分:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/news/”
5、文件名部分:从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.asp”。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名
6、锚部分:从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分
7、参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为“boardID=5&ID=24618&page=1”。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。
再补充两个概念:URI 和 URN
- URI(Uniform Resource Identifier),统一资源标识符,用来唯一的标识一个资源。HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息。
- URN(Uniform Resource Name),统一资源名称,是URI两种形式之一。唯一标识一个实体的标识符,但是不能给出实体的位置。URN 和 URL 都属于 URI。
总而言之,URL是URI的一个子集,告诉我们访问网络位置的方式。URL应该如下所示:
http://bitpoetry.io/posts/hello.html
URN是URI的子集,包括名字(给定的命名空间内),但是不包括访问方式,如下所示:
bitpoetry.io/posts/hello.html#intro
如果理解了 URL 的内容,其实大多数情况下就已经足够了,如果想要更清晰的理清 URI \URL\URN三者的关系与区别,可以参考下面这篇文章。
二、请求方法
HTTP1.0 定义了三种请求方法:GET, POST 和 HEAD 方法。
HTTP1.1 新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
下面是这八种方法的介绍。
| 方法 | 描述 |
|---|---|
| GET | 就四个字概括,获取资源!最常用的请求方法 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 |
| HEAD | 用于获取报文首部,和 GET 方法类似,但是不返回报文实体主体部分。主要用于确认 URL 的有效性以及资源更新的日期时间等。 |
| OPTIONS | 查询指定的 URL 能够支持的方法。 |
| PUT | 上传文件,存在安全性问题,一般不使用该方法。 |
| DELETE | 删除文件,跟PUT方法正好相反 |
| TRACE | 让服务器把通信路径返回给客户端。 |
| CONNECT | 使用 SSL(Secure Sockets Layer,安全套接层)和 TLS(Transport Layer Security,传输层安全)协议把通信内容加密后经网络隧道传输。 |
参与过 web 开发的朋友应该知道最常用的请求方法就是 GET 和 POST 这两个方法,一个用于获取数据,一个用于提交数据。面试时面试官也经常会问 GET 和 POST 这两个方法的区别,在这里顺便也给出这个问题的答案。
我们可以从五个层面来回答这个问题。
1. 作用
正如上面所说的,GET 主要用于获取资源,而 POST 主要用于传输实体主体。
2. 请求参数
GET 和 POST 的请求都能使用额外的参数,使用 GET 方法,请求参数是以查询字符串出现在 URL 中,而 POST 的参数存储在实体主体中。
不能因为 POST 参数存储在实体主体中就认为它的安全性更高,因为照样可以通过一些抓包工具(比如 WireShark、Fiddler)查看。
下面是使用 GET 和 POST 方法携带额外参数的示例
GET /test/index.html?user_id=1&user_name=sam HTTP/1.1
POST /test/index.html HTTP/1.1
Host: test.com
user_id=1&user_name=sam
还有一点需要注意的是,因为 URL 只支持 ASCII 码,因此 GET 的参数中如果存在中文等字符就需要先进行编码。例如 中文 会转换为 %E4%B8%AD%E6%96%87,而空格会转换为 %20。POST 参数支持标准字符集。
3. 安全性
安全的 HTTP 方法不会改变服务器状态,也就是说它只是可读的。
GET 方法是安全的,而 POST 却不是,因为 POST 的目的是传送实体主体内容,这个内容可能是用户上传的表单数据,上传成功之后,服务器可能把这个数据存储到数据库中,因此状态也就发生了改变。
4. 幂等性
解释一下什么是幂等性。
幂等的 HTTP 方法,同样的请求被执行一次与连续执行多次的效果是一样的,服务器的状态也是一样的。换句话说就是,幂等方法不应该具有副作用(统计用途除外)。
在正确实现的条件下,GET 方法都是幂等的,而 POST 方法不是。
5. 可缓存
这里的可缓存,指的是对响应进行缓存,避免同样的数据被重复的请求。
如果要对响应进行缓存,需要满足以下条件:
- 请求报文的 HTTP 方法本身是可缓存的,GET 就是个例子,POST 在多数情况下不可缓存的。
- 响应报文的状态码是可缓存的,包括:200, 203, 204, 206, 300, 301, 404, 405, 410, 414, 501。
- 响应报文的 Cache-Control 首部字段没有指定不进行缓存。
另外:
关于 GET 和 POST 方法的区别,网上有的文章会提及使用 GET 方法提交的数据长度有限制(有的说法也会提及 POST 的实体数据大小也是有限制的),这样说是不准确的。因为 GET 是通过 URL 提交数据,那么 GET 可提交的数据量就跟 URL 的长度有直接关系了。而实际上,URL不存在参数上限的问题,HTTP 协议规范没有对URL长度进行限制。这个限制是特定的浏览器及服务器对它的限制。IE 对 URL 长度的限制是2083字节(2K+35)。对于其他浏览器,如 Netscape、FireFox 等,理论上没有长度限制,其限制取决于操作系统的支持。
感兴趣的可以看下这篇文章
两个长度限制问题的分析(来源于项目)
三、HTTP协议版本
按协议规范,主要分为 HTTP/1.0 、HTTP/1.1 、HTTP/2.0 这三种。
关于这三种规范对比,会在文章末尾给出,因为还需要了解一些首部字段的知识。
这里只简单的提一下。
到这里,关于请求行的内容算是大致上撸完了,接下来就是请求报文最后要介绍的一部分了:首部字段。
第二部分:首部字段
有 4 种类型的首部字段:通用首部字段、请求首部字段、响应首部字段、实体首部字段。
各种首部字段(不全,只提供参考)及其含义如下
通用首部字段
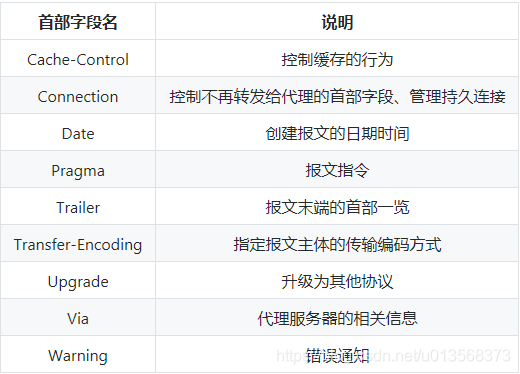
请求首部字段
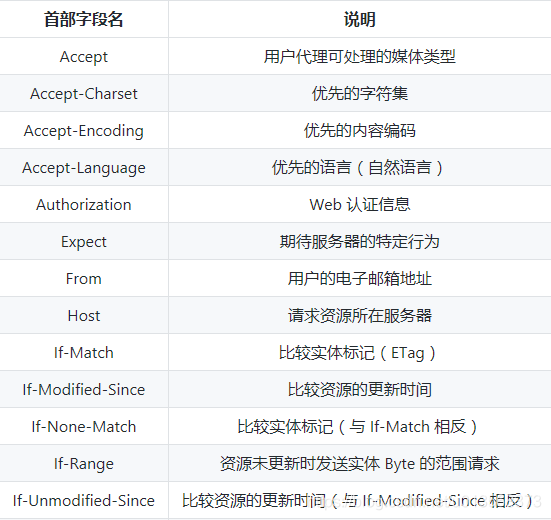
响应首部字段
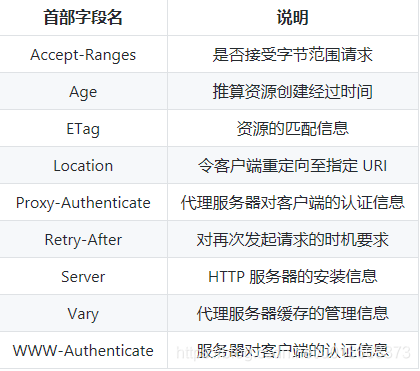
实体首部字段

了解一下即可,别傻呵呵的去背。
至此,请求报文的内容要点大致梳理完毕,接下来,我们来看一下响应报文。
响应报文
响应报文的结构和一个简单的例子如下图所示
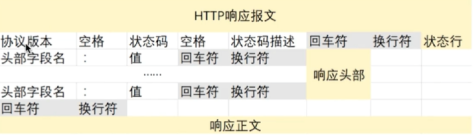
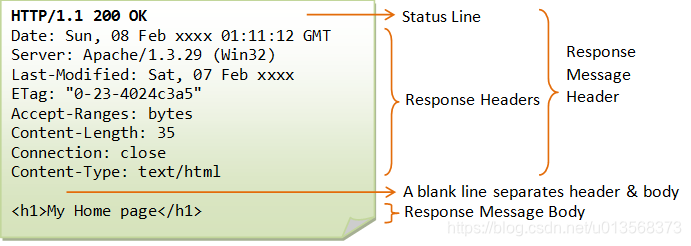
先宏观的看响应报文,之后本文会对一些比较重要的地方进行细致的介绍。
同请求报文一样,响应报文也可以被分为四个部分
- 响应行
- 首部字段
- 空行
- 响应正文
其中第二部分:首部字段 与 第三部分:空行。与请求报文同理,不多赘述。
第四部分响应报文,如其名,就是客户端请求服务端后,服务端反馈给你的你所要的资源或者是你执行了 POST 这种操作后,服务器反馈回来的额外的指示信息(比如成功或者失败)。
打个比方,你在你的浏览器地址栏中输入 www.baidu.com ,敲击回车后,根据上面我们所介绍的 HTTP 请求报文,现在你应该知道了,这时你的浏览器会向百度的服务器递交一个 HTTP 请求报文,请求方法就是 GET。而百度的服务器会将百度的首页作为响应正文反馈给你。
输入 URL (这里的例子就是百度的网址),发生的具体的一系列事情,这个也经常作为面试的考点,这里不多介绍了。有需要的话,请看我的另一篇文章,有关于这个问题的一个简单阐述。
用 Chrome 的调试模式简单的看一下。
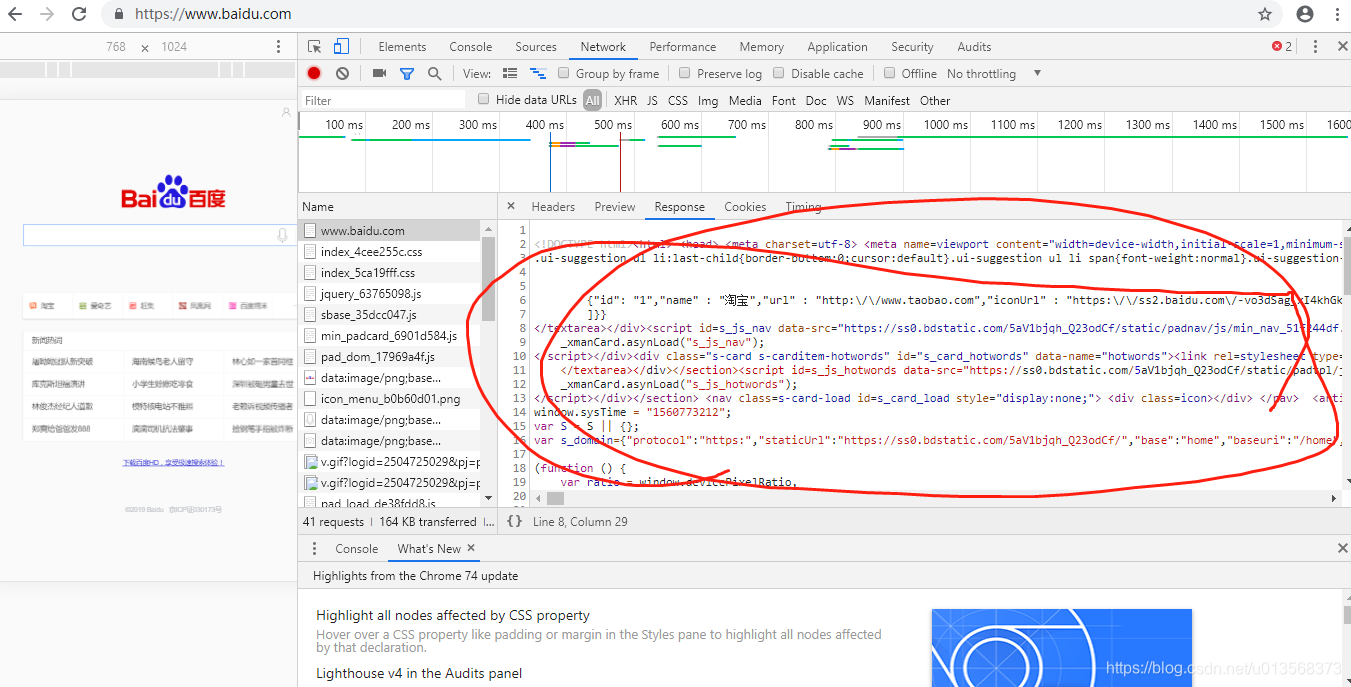
我圈红的这一大片就是响应正文,即百度首页的 HTML 文档。
那么对于响应报文,除了第一部分:响应行,其余的三个部分也都介绍完毕了,现在我们来看一下这个响应行。
响应行
同请求行一样,响应行也由三部分组成
- HTTP 协议版本
- 状态码
- 状态码描述
其中,HTTP 协议版本这个内容在请求报文中已经提到了,这里我们就只看一下状态码和其描述即可。
一共 5 种类型的状态码,分类和具体内容如下所述

1xx 指示信息
- 100 Continue :表明到目前为止都很正常,客户端可以继续发送请求或者忽略这个响应。
2xx 成功
- 200 OK
- 204 No Content :请求已经成功处理,但是返回的响应报文不包含实体的主体部分。一般在只需要从客户端往服务器发送信息,而不需要返回数据时使用。
- 206 Partial Content :表示客户端进行了范围请求,响应报文包含由 Content-Range 指定范围的实体内容。
3xx 重定向
- 301 Moved Permanently :永久性重定向
- 302 Found :临时性重定向
- 303 See Other :和 302 有着相同的功能,但是 303 明确要求客户端应该采用 GET 方法获取资源。
- 304 Not Modified :如果请求报文首部包含一些条件,例如:If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since,如果不满足条件,则服务器会返回 304 状态码。
- 307 Temporary Redirect :临时重定向,与 302 的含义类似,但是 307 要求浏览器不会把重定向请求的 POST 方法改成 GET 方法。
4xx 客户端错误
- 400 Bad Request :请求报文中存在语法错误。
- 401 Unauthorized :该状态码表示发送的请求需要有认证信息(BASIC 认证、DIGEST 认证)。如果之前已进行过一次请求,则表示用户认证失败。
- 403 Forbidden :请求被拒绝。
- 404 Not Found : 资源没找到
5xx 服务端错误
- 500 Internal Server Error :服务器正在执行请求时发生错误。
- 503 Service Unavailable :服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。
梳理完了请求/响应报文,再来看看 HTTP 其他几个比较重要的知识点
Cookie
详情见我另外一篇文章,链接在下面。
连接管理
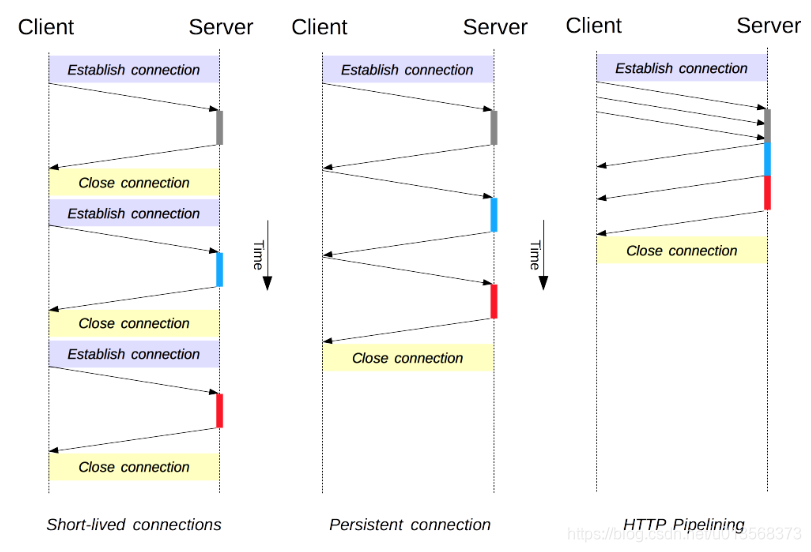
从左到右分别为 短连接、持久连接、流水线,其中持久连接又名长连接。
1. 短连接与持久连接
当浏览器访问一个包含多张图片资源的 HTML 页面时,除了请求访问的 HTML 页面资源,还会请求这些其他的资源。如果每进行一次 HTTP 通信就要新建一个 TCP 连接,那么开销会很大。
持久连接只需要建立一次 TCP 连接就能进行多次 HTTP 通信。
从 HTTP/1.1 开始默认是持久连接的,如果要断开连接,需要由客户端或者服务器端提出断开,使用 Connection : close
在 HTTP/1.1 之前默认是短连接的,如果需要使用持久连接,则使用 Connection : Keep-Alive。
2. 流水线
默认情况下,HTTP 请求是按顺序发出的,下一个请求只有在当前请求收到响应之后才会被发出。由于受到网络延迟和带宽的限制,在下一个请求被发送到服务器之前,可能需要等待很长时间。
流水线是在同一条长连接上连续发出请求,而不用等待响应返回,这样可以减少延迟。
HTTP/1.1对比HTTP/1.0
- 默认是持久连接,这个是最重要的区别
- 支持流水线
- 支持同时打开多个 TCP 连接
- 新增了五个请求方法 OPTIONS, PUT, DELETE, TRACE 和 CONNECT
- 新增缓存处理指令 max-age
现在应用广泛的主要还是 HTTP/1.1
关于 HTTP/1.1 与 HTTP/2.0 的对比可以参考下面这篇文章。