本质:由于keras命名不一致导致的
原理:Keras版的训练它由多个输出支路,也就是多个loss,一般会给每个网络一个默认命名,在编译时通过命名寻找各层。
错误点:使用了keras.utils.training_utils.multi_gpu_model()后,名字发生了变化。 因此,在预测时,keras寻找不到各层路径
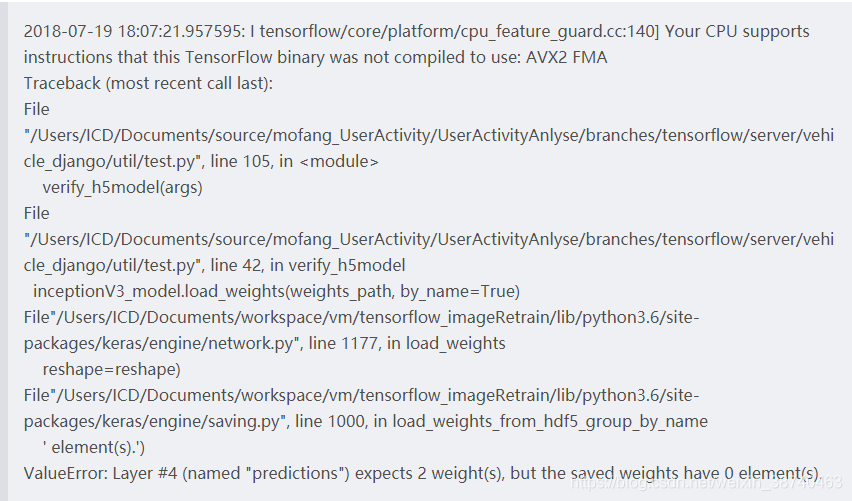
由于使用了两个GPU,因此报期望两个权重信息,单只有0个
解决方法:
我们使用多GPUS训练接口,使用单GPU的保存接口
def get_model(input_shape):
.
.
.
return model
model = get_model(input_shape) #此时为单GPU 搭建的model
from keras.utils import multi_gpu_model
# Replicates `model` on 4 GPUs.
# This assumes that your machine has 4 available GPUs.
paralleled_model = multi_gpu_model(model, gpus=4) #将搭建的model复制到4个GPU中
# for train
paralleled_model.compile(loss='categorical_crossentropy',
optimizer='adam')
model.save_weights("single_gpu_model.h5")
# fit data for train
tensorflow多GPUS原理:
tf将数据map到每个gpu上,分别计算loss和gradient,然后tf将所有的loss和gradient都reduce到cpu上,cpu求loss和gradient的平均后进行梯度优化
本质:多gpu加速的原理是增大batch的并行处理能力,每个GPU跑64 ,4个GPU一个Batch就跑256