一、CDN缓存(网络请求上游)
CDN其实是一种资源的分布式存放和备份的方法。解决因分布、带宽、服务器性能带来的访问延迟问题,适用于站点加速、秒杀、点播、直播等场景。使用户可以就近取得所需内容,解决Internet网络拥挤的状况,提高用户访问网站的响应速度和成功率。
通俗讲就是讲web服务器上的资源进行缓存,用户请求时,在网络请求的上游就可以就近将资源分发给用户。而不需要所有的用户都去web跟服务器就去请求资源。
-
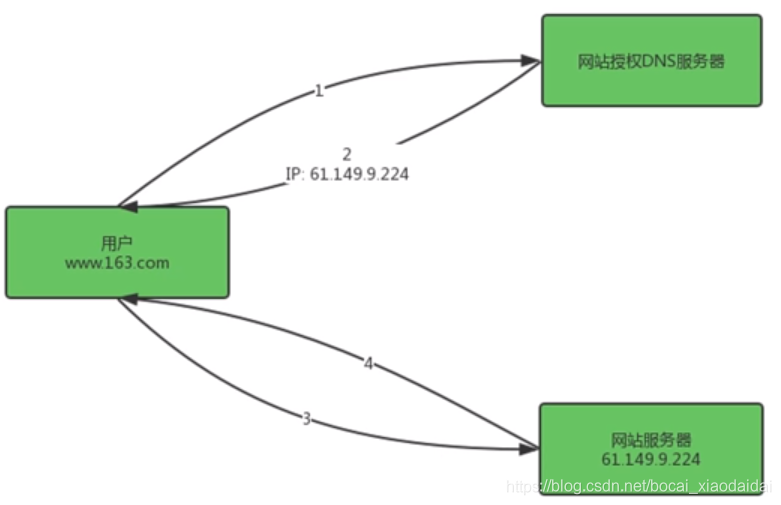
常规web请求处理流程
1.用户在自己的浏览器中输入要访问的网络域名
2.浏览器向本地DNS(域名解析服务器)服务器请求对该域名的解析
3.本地DNS服务器中如果缓存有这个域名的解析结果,则直接响应用户的解析请求
4.本地DNS服务器中如果没有关于这个域名的解析结果的缓存,则以递归方式向整个DNS系统请求解析,获得应答后将结果反馈给浏览器
5.浏览器得到域名解析结果,就是该域名相应的服务设备的ip
6.浏览器向服务器请求内容
7.服务器将用户请求内容传送给浏览器
-
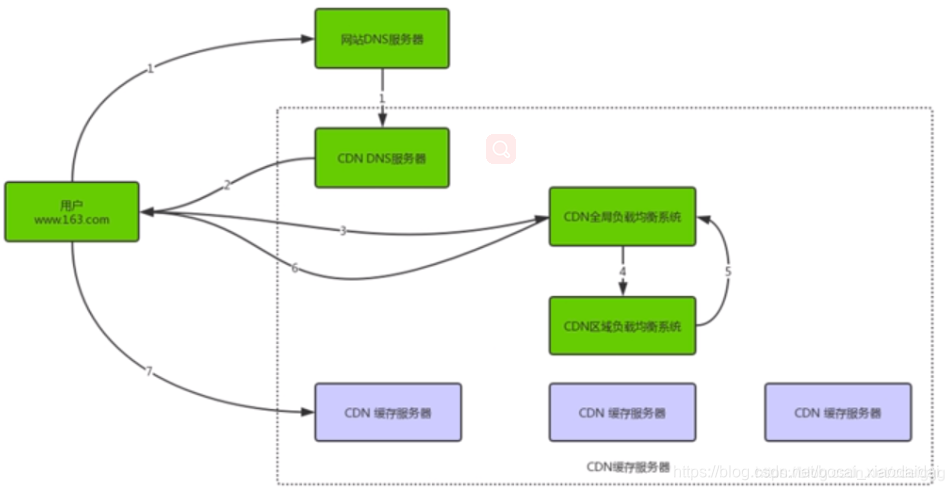
引入CDN后web请求处理流程
1.当用户点击网站页面的内容URL,经过本地DNS系统解析,DNS系统会最终将域名的解析权交给CNAME指向的CDN专用DNS服务器。
2.CDN的DNS服务器将CDN的全局负载均衡设备IP返回用户
3.用户向CDN的全局负载均衡设备发情内容URL访问请求
4.CDN全局负载均衡设备根据用户IP地址,及用户请求的内容URL,选择一台用户所属区域负载均衡设备,让用户向这台设备发起请求
5.区域负载均衡设备会为用户选择一台合适的缓存服务器提供服务
6.用户向缓存服务器发起请求,缓存服务器响应用户请求,将用户所需内容传送到用户终端
7.如果这台缓存服务器上没有用户想要的内容,那么这台服务器就要向它的上一级缓存服务器请求内容,直至追溯到网站原服务器将内容拉取到本地
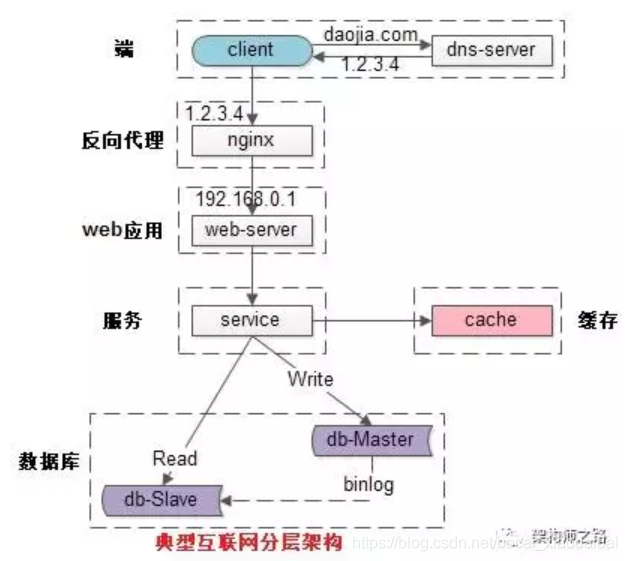
二、nginx反向代理(网络请求中间层)
nginx反向代理的作用:
- 负载均衡:
使用反向代理同时代理多个相同内容的应用服务器(比如tomcat),将客户端请求分发到各个应用服务器上并接收响应返回给客户端
- 动静分离:
运用Nginx的反向代理功能分发请求:所有动态资源的请求交给应用服务器,而静态资源的请求(例如图片、视频、CSS、JavaScript文件等)则直接由Nginx返回到浏览器
常见web网站架构设计:
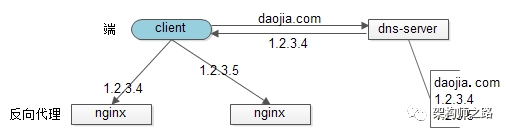
- 反向代理的水平扩展
反向代理的水平扩展,是通过“DNS轮询”实现的:dns-server对于一个域名配置了多个解析ip,每次DNS解析请求来访问dns-server,会轮询返回这些ip。
当nginx成为瓶颈的时候,只要增加服务器数量,新增nginx服务的部署,增加一个外网ip,就能扩展反向代理层的性能,做到理论上的无限高并发。
- 站点层的水平扩展(分布式部署)
站点层的水平扩展,是通过“nginx”实现的。通过修改nginx.conf,可以设置多个web后端。
当web后端成为瓶颈的时候,只要增加服务器数量,新增web服务的部署,在nginx配置中配置上新的web后端,就能扩展站点层的性能,做到理论上的无限高并发。
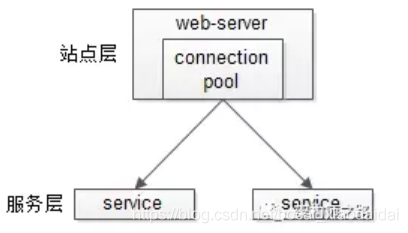
三、站点的缓存技术(web应用层)
-
1.数据缓存:
对于不会频繁变动而访问量又比较大的数据可以做缓存处理,可以缓存到内存型数据库、客户端等。 -
2.页面静态化:
html静态化也是某些缓存策略使用的手段,对于系统中频繁使用数据库查询但是内容更新很小的应用,可以考虑使用html静态化来实现 -
3.图片服务器分离:
对于Web服务器来说,图片是最消耗资源的,于是我们有必要将图片与页面进行分离,这是基本上大型网站都会采用的策略,他们都有独立的、甚至很多台的图片服务器。
四、数据库
-
1.硬件优化
-
2.数据库读写分离、主从同步
使用负载均衡实现,写操作都往主库上写,读操作往从服务器上读。 -
3.分库分表
分表方式
水平分割(按行)、垂直分割(按列)
分表场景
A: 根据经验,mysql表数据一般达到百万级别,查询效率就会很低。
B: 一张表的某些字段值比较大并且很少使用。可以将这些字段隔离成单独一张表,通过外键关联,例如考试成绩,我们通常关注分数,不关注考试详情。
C:把一个订单大表拆开,订单表、订单支付表、订单商品表。
水平分表策略
按时间分表:当数据有很强的实效性,例如微博的数据,可以按月分割。
按区间分表:例如用户表 1到一百万用一张表,一百万到两百万用一张表。
hash分表:通过一个原始目标id或者是名称按照一定的hash算法计算出数据存储的表名。 -
4.索引优化
将经常被用到且变动不太频繁的列使用索引,索引不是越多越好,因为数据变动时索引都要重新计算。 -
5.SQL优化
1、尽量避免全表扫描,首先硬考虑在 where 及 order by 涉及的列上简历索引。
2、应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描。
3、应尽量避免在 where 子句中使用 != 或者 <> 操作符,否则将引擎放弃使用索引而进行全表扫描。
4、like + 双通配符% 通常也会导致全表扫描。 -
6.字段优化
合理准确的使用字段类型及控制字段的长度等。
例如,char能满足就不用varchar