Java Web系列文章汇总贴: Java Web知识总结汇总
索引概述
优缺点
优势:可以快速检索,减少I/O次数,加快检索速度;根据索引分组和排序,可以加快分组和排序;
劣势:索引本身也是表,因此会占用存储空间,一般来说,索引表占用的空间的数据表的1.5倍;索引表的维护和创建需要时间成本,这个成本随着数据量增大而增大;构建索引会降低数据表的修改操作(删除,添加,修改)的效率,因为在修改数据表的同时还需要修改索引表;
索引分类
常见的索引类型有:主键索引、唯一索引、普通索引、全文索引、组合索引
1、主键索引:即主索引,根据主键pk_clolum(length)建立索引,不允许重复,不允许空值;
2、唯一索引:用来建立索引的列的值必须是唯一的,允许空值
3、普通索引:用表中的普通列构建的索引,没有任何限制
4、全文索引:用大文本对象的列构建的索引
5、组合索引:用多个列组合构建的索引,这多个列中的值不允许有空值
参考:
深入理解MySQL索引原理和实现——为什么索引可以加速查询
MySQL索引优化及原理
通常我们所说的索引是指B-Tree索引,它是目前关系型数据库中查找数据最为常用和有效的索引,大多数存储引擎都支持这种索引。InnoDB引擎中使用的索引是B+树结构。
随着数据库中数据的增加,索引本身大小随之增加,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级。可以想象一下一棵几百万节点的二叉树的深度是多少?如果将这么大深度的一颗二叉树放磁盘上,每读取一个节点,需要一次磁盘的I/O读取,整个查找的耗时显然是不能够接受的。那么如何减少查找过程中的I/O存取次数?
一种行之有效的解决方法是减少树的深度,将二叉树变为m叉树(多路搜索树),而B+Tree就是一种多路搜索树。理解B+Tree时,只需要理解其最重要的两个特征即可:第一,所有的关键字(可以理解为数据)都存储在叶子节点(Leaf Page),非叶子节点(Index Page)并不存储真正的数据,所有记录节点都是按键值大小顺序存放在同一层叶子节点上。其次,所有的叶子节点由指针连接。如下图为高度为3的简化了的B+Tree。
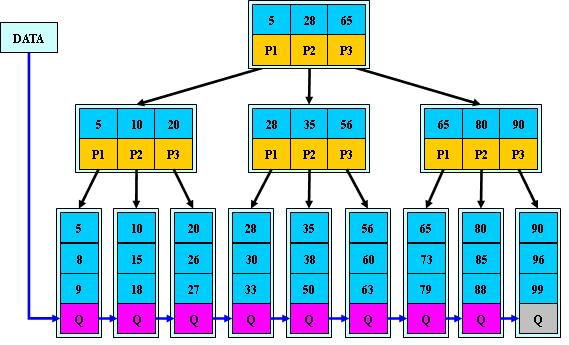
数据库索引采用B+树的主要原因是B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+树应运而生。B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)。B+树元素遍历效率极高,B+树的结构也特别适合带有范围的查找。比如查找学校18-22岁的学生人数,可以通过从根结点出发进行随机查找,找到第一个18岁的学生(此时到达了叶子结点),然后再在叶子结点出发顺序查找到符合范围的所有记录。
B+Tree中的B是指balance,意为平衡。需要注意的是,B+树索引并不能找到一个给定键值的具体行,它找到的只是被查找数据行所在的页,接着数据库会把页读入到内存,再在内存中进行查找,最后得到要查找的数据。
更多:
为什么MySQL数据库索引选择使用B+树?
MySql索引实现原理
数据库索引原理及优化
mysql索引的使用和优化
InnoDB B+树存多少数据
InnoDB一棵B+树可以存放多少行数据?这个问题的简单回答是:约2千万。
为什么呢?
InnoDB存储引擎也有自己的最小储存单元——页(Page),一个页的大小是16K。
数据表中的数据都是存储在页中的,所以一个页中能存储多少行数据呢?假设一行数据的大小是1k,那么一个页可以存放16行这样的数据。
所以,单个叶子节点(页)中的记录数=16K/1K=16。(这里假设一行记录的数据大小为1k,实际上现在很多互联网业务数据记录大小通常就是1K左右)。
那么现在我们需要计算出非叶子节点能存放多少指针,其实这也很好算,我们假设主键ID为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节,这样一共14字节,我们一个页中能存放多少这样的单元,其实就代表有多少指针,即161024/14 = 16384/14=1170。那么可以算出一棵高度为2的B+树,能存放117016=18720条这样的数据记录。
根据同样的原理我们可以算出一个高度为3的B+树可以存放:1170117016=21902400条这样的记录。所以在InnoDB中B+树高度一般为1-3层,它就能满足千万级的数据存储。在查找数据时一次页的查找代表一次IO,所以通过主键索引查询通常只需要1-3次IO操作即可查找到数据。
详细:
InnoDB一棵B+树可以存放多少行数据?
InnoDB中一棵B+树能存多少行数据
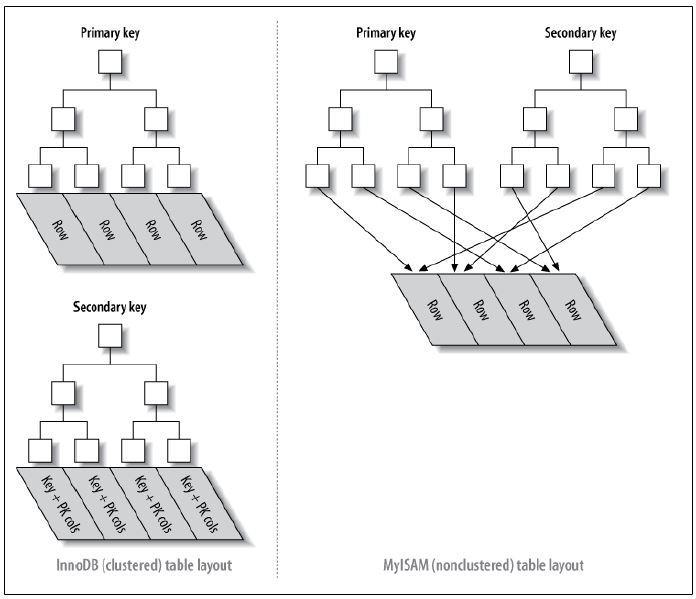
聚簇索引和非聚簇索引(辅助索引)
概述
索引分为聚簇索引和非聚簇索引两种,聚簇索引是按照数据存放的物理位置为顺序的,而非聚簇索引就不一样了;聚簇索引能提高多行检索的速度,而非聚簇索引对于单行的检索很快
MySQL中,不同的存储引擎对索引的实现方式不同,大致说下MyISAM和InnoDB两种存储引擎。
MyISAM的B+Tree的叶子节点上的data,并不是数据本身,而是数据存放的地址。主索引和辅助索引没啥区别,只是主索引中的key一定得是唯一的。这里的索引都是非聚簇索引。
MyISAM还采用压缩机制存储索引,比如,第一个索引为“her”,第二个索引为“here”,那么第二个索引会被存储为“3,e”,这样的缺点是同一个节点中的索引只能采用顺序查找。
InnoDB的数据文件本身就是索引文件,B+Tree的叶子节点上的data就是数据本身,key为主键,这是聚簇索引。非聚簇索引,叶子节点上的data是主键(所以聚簇索引的key,不能过长)。为什么存放的主键,而不是记录所在地址呢,理由相当简单,因为记录所在地址并不能保证一定不会变,但主键可以保证。
至于为什么主键通常建议使用自增id呢?
答:聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。如果主键不是自增id,那么可以想象,它会干些什么,不断地调整数据的物理地址、分页,当然也有其他一些措施来减少这些操作,但却无法彻底避免。但,如果是自增的,那就简单了,它只需要一页一页地写,索引结构相对紧凑,磁盘碎片少,效率也高。
使用推荐:

摘自:
MySQL的聚集索引和非聚集索引
MyISAM–非聚簇索引
- MyISAM存储引擎采用的是非聚簇索引,非聚簇索引的主索引和辅助索引几乎是一样的,只是主索引不允许重复,不允许空值,他们的叶子结点的key都存储指向键值对应的数据的物理地址。
- 非聚簇索引的数据表和索引表是分开存储的。
- 非聚簇索引中的数据是根据数据的插入顺序保存。因此非聚簇索引更适合单个数据的查询。插入顺序不受键值影响。
- 只有在MyISAM中才能使用FULLTEXT索引。(mysql5.6以后innoDB也支持全文索引)
- 既然非聚簇索引的主索引和辅助索引指向相同的内容,为什么还要辅助索引这个东西呢,后来才明白索引不就是用来查询的吗,用在那些地方呢,不就是WHERE和ORDER BY 语句后面吗,那么如果查询的条件不是主键怎么办呢,这个时候就需要辅助索引了。
InnoDB–聚簇索引
- 聚簇索引的主索引的叶子结点存储的是键值对应的数据本身,辅助索引的叶子结点存储的是键值对应的数据的主键键值。因此主键的值长度越小越好,类型越简单越好。
- 聚簇索引的数据和主键索引存储在一起。
- 聚簇索引的数据是根据主键的顺序保存。因此适合按主键索引的区间查找,可以有更少的磁盘I/O,加快查询速度。但是也是因为这个原因,聚簇索引的插入顺序最好按照主键单调的顺序插入,否则会频繁的引起页分裂,严重影响性能。
- 在InnoDB中,如果只需要查找索引的列,就尽量不要加入其它的列,这样会提高查询效率。
使用主索引的时候,更适合使用聚簇索引,因为聚簇索引只需要查找一次,而非聚簇索引在查到数据的地址后,还要进行一次I/O查找数据。
因为聚簇辅助索引存储的是主键的键值,因此可以在数据行移动或者页分裂的时候降低委会成本,因为这时不用维护辅助索引。但是辅助索引会占用更多的空间。
聚簇索引在插入新数据的时候比非聚簇索引慢很多,因为插入新数据时需要减压主键是否重复,这需要遍历主索引的所有叶节点,而非聚簇索引的叶节点保存的是数据地址,占用空间少,因此分布集中,查询的时候I/O更少,但聚簇索引的主索引中存储的是数据本身,数据占用空间大,分布范围更大,可能占用好多的扇区,因此需要更多次I/O才能遍历完毕。
下图可以形象的说明聚簇索引和非聚簇索引的区别
覆盖索引(Covering Indexes)
如果索引包含满足查询的所有数据,就称为覆盖索引。覆盖索引是一种非常强大的工具,能大大提高查询性能。只需要读取索引而不用读取数据有以下一些优点:
(1)索引项通常比记录要小,所以MySQL访问更少的数据;
(2)索引都按值的大小顺序存储,相对于随机访问记录,需要更少的I/O;
(3)大多数据引擎能更好的缓存索引。比如MyISAM只缓存索引。
(4)覆盖索引对于InnoDB表尤其有用,因为InnoDB使用聚集索引组织数据,如果二级索引中包含查询所需的数据,就不再需要在聚集索引中查找了。
InnoDB存储引擎支持覆盖索引,即从辅助索引中就可以得到查询的记录,而不需要查询聚集索引中的记录。
使用覆盖索引有啥好处?
- 可以减少大量的IO操作
- 有助于统计
覆盖索引不能是任何索引,只有B-TREE索引存储相应的值。而且不同的存储引擎实现覆盖索引的方式都不同,并不是所有存储引擎都支持覆盖索引(Memory和Falcon就不支持)。
对于索引覆盖查询(index-covered query),使用EXPLAIN时,可以在Extra一列中看到“Using index”。例如,在sakila的inventory表中,有一个组合索引(store_id,film_id),对于只需要访问这两列的查询,MySQL就可以使用索引,如下:
mysql> EXPLAIN SELECT store_id, film_id FROM sakila.inventory\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: inventory
type: index
possible_keys: NULL
key: idx_store_id_film_id
key_len: 3
ref: NULL
rows: 5007
Extra: Using index
1 row in set (0.17 sec)
在大多数引擎中,只有当查询语句所访问的列是索引的一部分时,索引才会覆盖。但是,InnoDB不限于此,InnoDB的二级索引在叶子节点中存储了primary key的值。因此,sakila.actor表使用InnoDB,而且对于是last_name上有索引,所以,索引能覆盖那些访问actor_id的查询,如:
mysql> EXPLAIN SELECT actor_id, last_name
-> FROM sakila.actor WHERE last_name = 'HOPPER'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: actor
type: ref
possible_keys: idx_actor_last_name
key: idx_actor_last_name
key_len: 137
ref: const
rows: 2
Extra: Using where; Using index
索引使用建议
什么时候要使用索引?
- 主键自动建立唯一索引;
- 经常作为查询条件在WHERE或者ORDER BY 语句中出现的列要建立索引;
- 作为排序的列要建立索引;
- 查询中与其他表关联的字段,外键关系建立索引
- 高并发条件下倾向组合索引;
什么时候不要使用索引?
- 经常增删改的列不要建立索引;
- 有大量重复的列不建立索引;
- 表记录太少不要建立索引;
- 在组合索引中不能有列的值为NULL,如果有,那么这一列对组合索引就是无效的;
- 在一个SELECT语句中,索引只能使用一次,如果在WHERE中使用了,那么在ORDER BY中就不要用了;
- LIKE操作中,’%aaa%'不会使用索引,也就是索引会失效,但是‘aaa%’可以使用索引;
- 在索引的列上使用表达式或者函数会使索引失效,例如:select * from users where YEAR(adddate)<2007,将在每个行上进行运算,这将导致索引失效而进行全表扫描,因此我们可以改成:select * from users where adddate<’2007-01-01′。
- 在查询条件中使用正则表达式时,只有在搜索模板的第一个字符不是通配符的情况下才能使用索引。
- 在查询条件中使用<>会导致索引失效。
- 在查询条件中使用IS NULL会导致索引失效。
- 在查询条件中使用OR连接多个条件会导致索引失效,这时应该改为两次查询,然后用UNION ALL连接起来。
- 尽量不要包括多列排序,如果一定要,最好为这队列构建组合索引;
- 只有当数据库里已经有了足够多的测试数据时,它的性能测试结果才有实际参考价值。如果在测试数据库里只有几百条数据记录,它们往往在执行完第一条查询命令之后就被全部加载到内存里,这将使后续的查询命令都执行得非常快–不管有没有使用索引。只有当数据库里的记录超过了1000条、数据总量也超过了MySQL服务器上的内存总量时,数据库的性能测试结果才有意义。
其他建议
1、MySQL只对一下操作符才使用索引:<,<=,=,>,>=,between,in,以及某些时候的like(不以通配符%或_开头的情形)
2、缺省情况下建立的索引是非聚簇索引,但有时它并不是最佳的。在非群集索引下,数据在物理上随机存放在数据页上。合理的索引设计要建立在对各种查询的分析和预测上。一般来说:
- a.有大量重复值、且经常有范围查询( > ,< ,> =,< =)和order by、group by发生的列,可考
虑建立群集索引; - b.经常同时存取多列,且每列都含有重复值可考虑建立组合索引;
- c.组合索引要尽量使关键查询形成索引覆盖,其前导列一定是使用最频繁的列。索引虽有助于提高性能但不是索引越多越好,恰好相反过多的索引会导致系统低效。用户在表中每加进一个索引,维护索引集合就要做相应的更新工作。
3、ORDER BY和GROPU BY使用ORDER BY和GROUP BY短语,任何一种索引都有助于SELECT的性能提高。
4、索引不会包含有NULL值的列
5、多表操作在被实际执行前,查询优化器会根据连接条件,列出几组可能的连接方案并从中找出系统开销最小的最佳方案。连接条件要充份考虑带有索引的表、行数多的表;内外表的选择可由公式:外层表中的匹配行数*内层表中每一次查找的次数确定,乘积最小为最佳方案。
6、任何对列的操作都将导致表扫描,它包括数据库函数、计算表达式等等,查询时要尽可能将操作移至等号右边。
7、IN、OR子句常会使用工作表,使索引失效。如果不产生大量重复值,可以考虑把子句拆开。拆开的子句中应该包含索引。
索引优化
- 最左前缀,把排序分组频率最高的列放在最左边,以此类推
- 带索引的模糊查询优化,使用LIKE进行模糊查询的时候,’%aaa%'不会使用索引
- 为检索的条件构建全文索引,然后使用
- 使用短索引,对串列进行索引,如果可能应该指定一个前缀长度。
- 索引不会包含有NULL值的列
- 索引列排序
- 不要在列上进行运算