YOLO训练和检测均是在一个单独网络中进行。
训练:
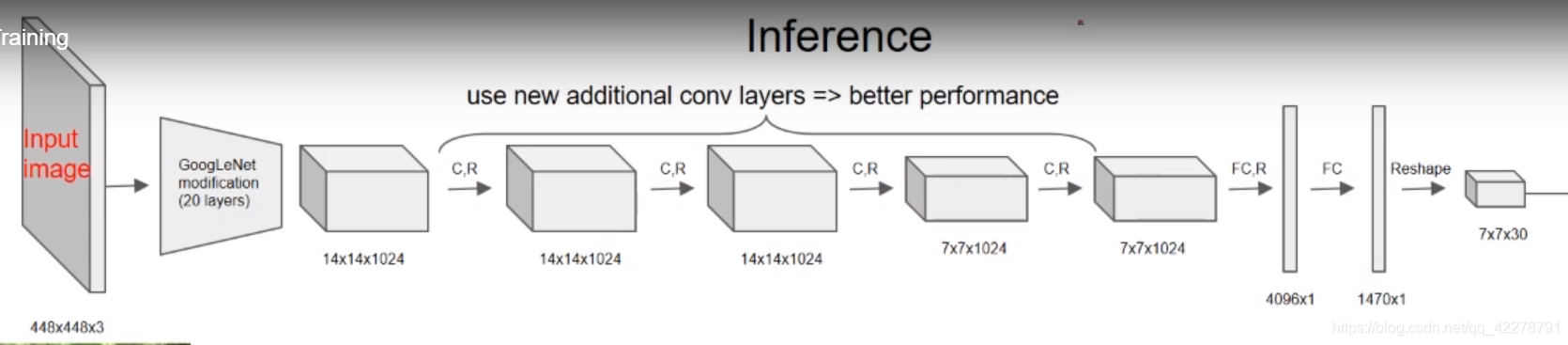
网络结构:
使用1x1和3x3的卷积来代替GoogleNet中原来的Inception模块,使用ImageNet数据集预先训练好GoogleNet。再加入一些新的卷积层,参数是随机初始化的。
输出tensor的值是没有任何意义的,我们通过训练,人为规定某个维度的值表示什么。我们规定如下:

其中训练样本的x,y,w,h都是已知的,Pr(Object),IOU也是已知的。

对于每个grid,训练时只用计算含有物体的grid中各个类别的概率。只有那些grid才有意义。
彻底搞懂YOLO
猜你喜欢
转载自blog.csdn.net/qq_42278791/article/details/91594894
今日推荐
周排行