HDFS写入剖析:
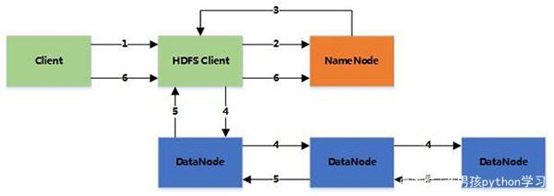
- 发请求:客户端向NameNode发出写文件请求。
- 检查:检查是否已存在文件、检查权限。若通过检查,直接先将操作写入编辑日志(详情见NameNode文件目录),并返回输出流对象。
- 切块:client端按128MB的块切分文件,形成数据队列。
- 返回管线:NameNode挑选一组合适的DataNode(按照默认副本存放策略),称为一个管线。将其返回给客户端。
默认副本存放策略:副本1.客户端所在节点(离客户端最近);副本2.不同于第一个节点的机架上;副本3.同第二个节点相同机架的不同节点,副本4如果还有其他的就随机。 - 写入:客户端向输出流中写入数据和校验码(一个块的所有校验码组成校验和,在写入前计算,保存在相同hdfs命名空间下),并流式的写入管线中的每个节点。
(第一个DataNode接收后,将数据写入本地磁盘,通过管道进行复制传输给第二个DataNode,然后是采用同样的方式传输给第三个DataNode,直至最后一个DataNode) - 故障:当DataNode发生故障,关闭管线。 在该数据块所在的其他DataNode做个标识,发送给NameNode。 管线中删除故障DataNode。 数据包继续在管线中的正常NameNode间发送。 (当副本量不足时,在新节点上创建新副本)
- 写完一块:最后一个DataNode写完后,向前一个DataNode发送确认,最终第一个DataNode发送确认给客户端,客户端会向NameNode发送最终确认。然后写下一个块。
- 全部写完:文件写入完成后,通知NameNode,关闭输入流。
HDFS读取剖析:
- 客户端向NameNode发送请求。
- NameNode返回文件位置列表和输入流
- 客户端挑选最近的DataNode发送请求,读取第一个块数据
- 客户端极端校验和并且和保存的原始校验和比较。
(如果不匹配,将这个块标记为损坏,报告给NameNode,将这个块在其他DataNode的副本复制到其他节点。随后会删除已损坏的副本。最终选择在其他节点读取文件。) - 读到末尾,关闭与此DataNode的连接,访问下一个块的最佳DataNode
- 客户端读取完成,关闭输入流。
参考链接:
https://blog.csdn.net/whdxjbw/article/details/81072207
https://www.cnblogs.com/luminous1/p/8360980.html
https://blog.csdn.net/weixin_43093501/article/details/89423504