转载:https://blog.csdn.net/wxb141001yxx/article/details/82422527
【前言】
在做任何事情的过程中,都可能会遇到各种各样的问题,同样编程开发就更不用说啦。在遇到问题之后,我们要用于挑战,因为那些都是我们宝贵的财富呀。
【内容】
小编在开发的过程中,遇到这样的问题就是运行index.jsp文件是显示中文乱码。
出现问题主要是与字符集的格式有关。
小编在编写的时候编写字符集的格式是:ISO-8859-1时,出现的中文乱码。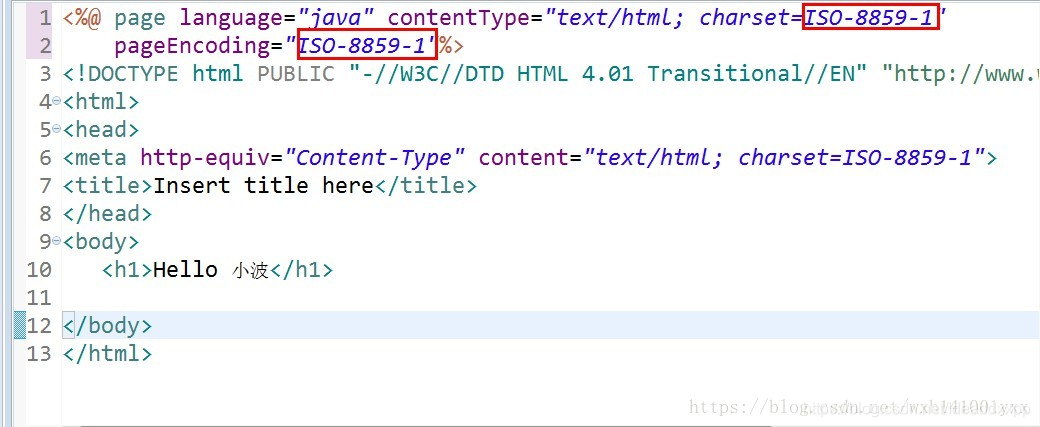
解决的方式一:
在编写index.jsp文件时,将其字符集改为UTF-8,并且网页显示的pageEncoding=UTF-8.如下图所示。改完之后运行时index.jsp中的中文就不会出现乱码啦。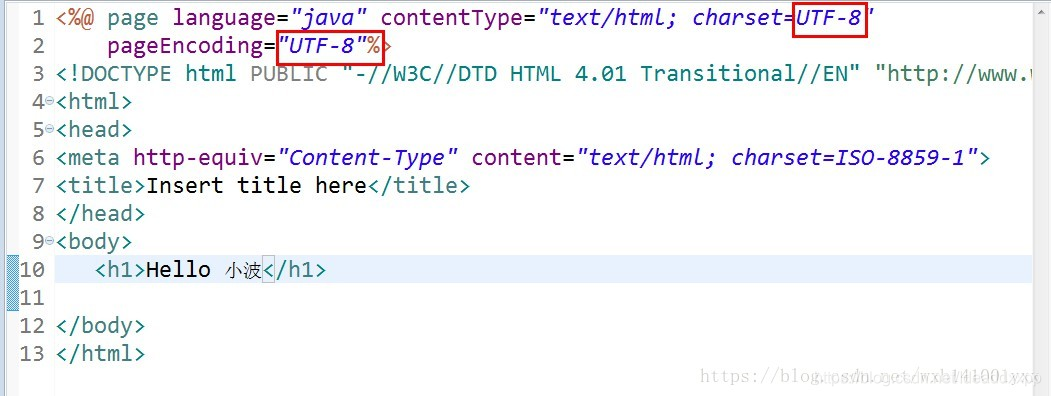
解决方式二:
先进Window——preferences——General——Workspace——Text file encoding修改为other选项,然后设置自己需要的编码格式。
在Eclipse中的Window——preferences——Content Type——Text——JSP会显示Defalut encoding 将其改为自己需要的编码格式即可。
解决方式三:
修改tomcat/bin/catalina.sh文件,在JAVA_OPTS变量后新增以下参数:
-Dfile.encoding=UTF8 -Dsun.jnu.encoding=UTF8
然后重启tomcat即可。
为什么将字符集格式从:ISO8859-1改成UTF-8就不会出现中文乱码呢?
因为ISO8859-1属于单字节编码,最多能表示的字符范围是0-255,应用于英文系列。比如,字母a的编码为0x61=97。
很明显,iso8859-1编码表示的字符范围很窄,无法表示中文字符。但是,由于是单字节编码,和计算机最基础的表示单位一致,所以很多时候,仍旧使用iso8859-1编码来表示。而且在很多协议上,默认使用该编码。比如,虽然”中文”两个字不存在iso8859-1编码,以gb2312编码为例,应该是”d6d0 cec4”两个字符,使用iso8859-1编码的时候则将它拆开为4个字节来表示:”d6 d0 ce c4”(事实上,在进行存储的时候,也是以字节为单位处理的)。而如果是UTF编码,则是6个字节”e4 b8 ad e6 96 87”。很明显,这种表示方法还需要以另一种编码为基础。
UTF字符集考虑到unicode编码不兼容iso8859-1编码,而且容易占用更多的空间:因为对于英文字母,unicode也需要两个字节来表示。所以unicode不便于传输和存储。因此而产生了utf编码,utf编码兼容iso8859-1编码,同时也可以用来表示所有语言的字符,不过,utf编码是不定长编码,每一个字符的长度从1-6个字节不等。另外,utf编码自带简单的校验功能。一般来讲,英文字母都是用一个字节表示,而汉字使用三个字节。
注意,虽然说utf是为了使用更少的空间而使用的,但那只是相对于unicode编码来说,如果已经知道是汉字,则使用GB2312/GBK无疑是最节省的。不过另一方面,值得说明的是,虽然utf编码对汉字使用3个字节,但即使对于汉字网页,utf编码也会比unicode编码节省,因为网页中包含了很多的英文字符。
【总结】
遇到问题解决问题,不要害怕Bug,因为它们都是我们成长的小伙伴。