Q1 Collection
java的集合以及集合之间的继承关系?

数组和链表的区别?
固定长度,连续内存,不能扩展,随机访问快,插入删除慢。链表相反
List, Set, Map的区别?
List,Set继承Collection接口
List可以放重复数据,Set不能,Map是k-v对
List和Map的实现方式以及存储方式?
ArrayList: 底层动态数组。随机访问快,增删慢,线程不安全。
扩容导致数组复制,批量删除会导致找两个集合交集,效率低。
LinkedList: 底层链表(双向列表)。增删快,查找慢,线程不安全。
遍历: 1.普通for循环,元素越多后面越慢 2.迭代器:每次访问,用游标记录当前位置
根据下标获取node,会根据index处于前半段还是后半段进行折半,提升效率。
HashMap: 散列表, 数组+链表+红黑树(JDK1.8) 默认16, 扩容2的幂
Q2 List
ArrayList实现原理?
动态数组,默认10,扩容grow(minCapacity),增加到1.5倍
ArrayList和LinkedList的区别,以及应用场景?
1.动态数组和双向队列链表。
2.ArrayList用for循环遍历优于迭代器,LinkedList则相反。
3.ArrayList在数组任意位置插入,或导致该位置后面元素重新排列,效率相对低。
LinkedList增删只需移动指针,时间效率高。不需扩容,空间效率也高。但随机访问元素时间效率低。
链表翻转? 手写链表逆序代码?
方法1:递归: 从最后一个Node开始,在弹栈的过程中将指针顺序置换。


1 public class Node { 2 3 private String data; 4 5 private Node next; 6 7 // Getter() & Setter() 8 9 } 10 11 public Node reverse(Node head) { 12 13 if (head == null || head.getNext() == null) { 14 15 return head; 16 17 } 18 19 Node temp = head.getNext(); 20 21 Node newHead = reverse(head.getNext()); 22 23 temp.setNext(head); 24 25 head.setNext(null); 26 27 return newHead; 28 29 }
解析:递归本质是系统压栈,压栈时保留现场。
例子:A->B->C->D
程序先压栈,到达倒数第2个节点时(C),C的next为D, reverse(D)返回D。
接着就是弹栈过程,执行temp.setNext(head); 此时temp是D, head是C,temp的next设置为C, 就是D->C, 不过head是C,还有next是D,这句会形成环(D->C->D)。需要下一句head.setNext(null);把C的next指针断开,形成D->C(C.next->null)的反转最后2个节点。返回新链表的头结点newHead,也就是D。后面进行相同操作,最终完成整个链表的反转。
方法2:遍历: 在链表遍历的过程中将指针顺序置换。
1 public Node traverseReverse(Node head) { 2 3 Node pre = null; 4 5 Node next; 6 7 while(head != null) { 8 9 next = head.getNext(); 10 11 head.setNext(pre); 12 13 pre = head; 14 15 head = next; 16 17 } 18 19 return pre; 20 21 }
解析:在head点遍历, 第一次时为A节点,next为B节点,head(A)节点的next设置为前一个节点pre(当前为null),把head节点赋给pre,pre为A节点,再把next节点(B)赋给head。
进行下一次循环,head为B节点,pre为A节点,head(B)节点的next设置为前一个节点pre(A),形成B->A,再复制给pre。Head移动到下一个节点。依次继续循环。。。
判断一个单链表是否有环?如果有环找出环的起点,以及环的长度?
方法一,穷举遍历。用新节点ID和此节点之前所有节点ID依次比较,如发现存在相同ID,则有环。时间复杂度O(N*N), 没有额外空间,空间复杂度O(1)
方法二,哈希表HashSet缓存。如发现存在相同节点,则说明有环。时间复杂度O(N),空间复杂度O(N)。
方法三,快慢指针。快指针移动2个节点,慢指针移动1个节点。然后比较2个指针节点是否相同。相同有环。
Q3 Map
HashMap数据结构,实现原理?put, get, resize等工作原理?
HashMap存储key-value键值对。Key和value都允许为null。Key重复会被覆盖,value可以重复。无序。非线程安全。
JDK1.7 数组+链表,JDK1.8 数组+链表+红黑树。
默认集合容量16,默认填充因子0.75,链表长度2的幂,链表长度>8,集合容量>64,链表转红黑树,当红黑树节点个数小于6,又会转化为链表。新增红黑树作为底层数据结构,在数据量较大且哈希碰撞较多时,提高索引效率。
HashMap实现原理:
底层table,是一个Node<K,V>的数组,当添加一个元素时,先计算key的hash值,以此确定插入table的位置。如果同一个hash的元素已经放入在table的同一位置,则添加到该元素的后面,形成链表。当链表过长时,转化为红黑树,提高查询效率。
计算数组table索引的方法:(算hash是1,2步,第3步算table索引)
1. 取 hashCode 值: h = key.hashCode()
2. 高位参与运算:h>>>16
3. 取模运算:(table.length - 1) & hash
Put()方法工作原理:
① 判断键值对数组 table 是否为空或为null,否则执行resize()进行扩容;
② 根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③ 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
④ 判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
⑤ 遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树(treeifyBin),在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥ 插入成功后,判断实际存在的键值对数量size是否超过了最大容量threshold,如果超过,进行扩容resize()。
⑦ 如果新插入的key不存在,则返回null,如果新插入的key存在,则返回原key对应的value值(注意新插入的value会覆盖原value值)
Resize扩容的工作原理:
1.计算新桶数组的容量 newCap
2.新阀值 newThr
3. 将原集合的元素重新映射到新集合中
3.1 既不是链表又不是红黑树,直接插入
3.2 红黑树,调用split方法重新分配
3.3.链表,不用像JDK1.7重新计算hash,只看原hash值新增的bit是1还是0,是0则索引不变,是1则索引变为”原索引+oldCap”
Get工作原理:
1. 通过key的hash计算table索引位置:hash & (length - 1)。
2. 检查数组该位置节点是否刚好是要找的元素,如果是则返回,如果不是则第3步。
3. 判断该元素时否TreeNode, 如果是则用红黑树TreeNode的方法find查找元素。如果不是则第4步。
4.遍历链表,找到相等(==或equals)的key。
HashMap线程不安全实际会如何体现?
1. 多线程同时Put元素,假设key发生碰撞(hash相同),这个两个key会添加到数组同一个位置,其中一个线程的数据被覆盖。
2. 多线程同时检查到需要扩容,都在重新计算元素位置及复制数据,最终只有一个线程扩容后的数组会赋值给table,其他线程会丢失。
HashMap如何变成线程安全?
1. Collections.synchronizeMap();
2. ConcurrentHashMap(java.util.concurrent). JDK1.5+
为什么String, Integer这样的wrapper类适合作为键?
String是不可变的,所以他创建的时候hashcode就被缓存了,不需要重新计算。还有字符串的处理速度要快过其他的键对象。
Integer的hashcode返回本身的值,也是不变的。
重新调整HashMap的大小存在什么问题?
JDK1.7多线程会产生竞争条件(race condition)。
两个线程同时尝试调整大小。调整过程,存储链表中元素次序会反过来,放在头部不是尾部,是为了避免尾部遍历(tail traversing)。如果竞争条件发生,就产生死循环。
HashMap中如何解决碰撞问题?如何减少碰撞?
在调用Put和get方法时,首先通过key的hashcode方法计算哈希桶的位置在存储对象。当获取对象时,通过键对象的equals()方法找到正确的键值对。
HashMap使用链表来解决碰撞问题,当碰撞发生了,对象将会存储在链表的下一个节点。
减少碰撞:1. 使用不可变,声明为final的对象,比如String 作为Key。
2.采用合适的equals()和hashCode()方法,将会减少碰撞发生,提高效率。String已经重写了equals和hashcode方法,很适合作为HashMap的Key。
LinkedHashMap和TreeMap是如何保证它的顺序的?
LinkedHashMap继承HashMap.Node的属性,额外增加了before, after用于指向前一个Entry和后一个Entry,在哈希表继承上构成双向链表。可以按照插入的顺序排序的Map。
TreeMap是按照Key的自然顺序或者Comparator的顺序进行排序。
LinkedHashMap是双向链表,TreeMap是红黑树。
它们两个哪个的有序实现比较好?
如果要按自然顺序或自定义顺序遍历键,那么TreeMap实现更好。如果需要输出的顺序和输入的相同,那么用LinkedHashMap实现更好。
附上Collection思维导图
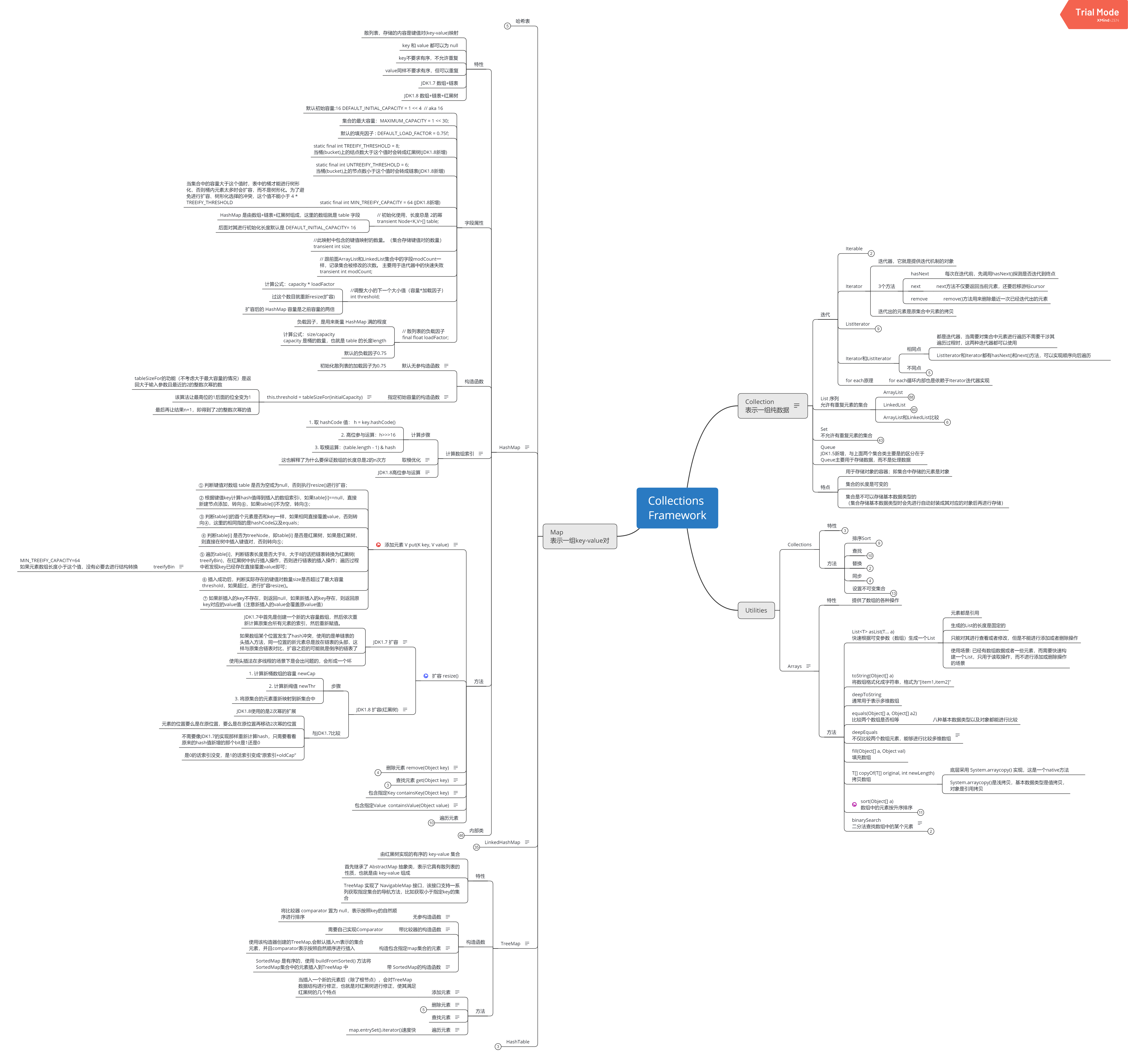
Collection思维导图Github地址:
https://github.com/channingy/JavaSummary/
参考资料:
https://www.cnblogs.com/ysocean/p/8657850.html