版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_29027865/article/details/88132008
DW集训营数据库Mysql梳理[六]
1 行程和用户(难度:困难)
项目十:行程和用户(难度:困难)
Trips 表中存所有出租车的行程信息。每段行程有唯一键 Id,Client_Id 和 Driver_Id 是 Users 表中 Users_Id 的外键。Status 是枚举类型,枚举成员为 (‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’)。
+----+-----------+-----------+---------+--------------------+----------+
| Id | Client_Id | Driver_Id | City_Id | Status |Request_at|
+----+-----------+-----------+---------+--------------------+----------+
| 1 | 1 | 10 | 1 | completed |2013-10-01|
| 2 | 2 | 11 | 1 | cancelled_by_driver|2013-10-01|
| 3 | 3 | 12 | 6 | completed |2013-10-01|
| 4 | 4 | 13 | 6 | cancelled_by_client|2013-10-01|
| 5 | 1 | 10 | 1 | completed |2013-10-02|
| 6 | 2 | 11 | 6 | completed |2013-10-02|
| 7 | 3 | 12 | 6 | completed |2013-10-02|
| 8 | 2 | 12 | 12 | completed |2013-10-03|
| 9 | 3 | 10 | 12 | completed |2013-10-03|
| 10 | 4 | 13 | 12 | cancelled_by_driver|2013-10-03|
+----+-----------+-----------+---------+--------------------+----------+
Users 表存所有用户。每个用户有唯一键 Users_Id。Banned 表示这个用户是否被禁止,Role 则是一个表示(‘client’, ‘driver’, ‘partner’)的枚举类型。
+----------+--------+--------+
| Users_Id | Banned | Role |
+----------+--------+--------+
| 1 | No | client |
| 2 | Yes | client |
| 3 | No | client |
| 4 | No | client |
| 10 | No | driver |
| 11 | No | driver |
| 12 | No | driver |
| 13 | No | driver |
+----------+--------+--------+
写一段 SQL 语句查出 2013年10月1日 至 2013年10月3日 期间非禁止用户的取消率。基于上表,你的 SQL 语句应返回如下结果,取消率(Cancellation Rate)保留两位小数。
+------------+-------------------+
| Day | Cancellation Rate |
+------------+-------------------+
| 2013-10-01 | 0.33 |
| 2013-10-02 | 0.00 |
| 2013-10-03 | 0.50 |
+------------+-------------------+
2 各部门前3高工资的员工(难度:中等)
将昨天employee表清空,重新插入以下数据(其实是多插入5,6两行):
+----+-------+--------+--------------+
| Id | Name | Salary | DepartmentId |
+----+-------+--------+--------------+
| 1 | Joe | 70000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
+----+-------+--------+--------------+
编写一个 SQL 查询,找出每个部门工资前三高的员工。例如,根据上述给定的表格,查询结果应返回:
+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Max | 90000 |
| IT | Randy | 85000 |
| IT | Joe | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
+------------+----------+--------+
此外,请考虑实现各部门前N高工资的员工功能。
思路一:
因为只有两个部门,我们可以取巧分别对每个部门按工资降序排名,取前三行,然后UNION。
需要注意的是,ORDER BY 和 LIMIT本身不支持在子查询中使用。所以需要加上括号形成独立的几个表而不是UNION的子查询。
3 分数排名(难度:中等)
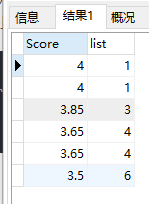
依然是昨天的分数表,实现排名功能,但是排名是非连续的,如下:
+-------+------+
| Score | Rank |
+-------+------+
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 3 |
| 3.65 | 4 |
| 3.65 | 4 |
| 3.50 | 6 |
+-------+------+
思考下之前的思路,训练五
之前的例子是编写一个 SQL 查询来实现分数排名。如果两个分数相同,则两个分数排名(Rank)相同,之前的实现为:
SELECT Score,
(SELECT COUNT(DISTINCT Score)
FROM score AS s2
WHERE s2.Score>=s1.Score
)
FROM score AS s1
ORDER BY Score DESC;
为了表示出排名,当时count的是排除重复数字过后的score,因此改变时,我们首先不能再加DISTINCT,这样如果4有两个的话,得到的默认值两个都为2,因此在筛选条件上我们不能让>=,将其变为>,变为>后,两个的默认值都会变为0,此时只要再在基础上加一就可以,如下:
SELECT Score,
(SELECT COUNT(Score)
FROM score AS s2
WHERE s2.Score > s1.Score
)+1 AS list
FROM score AS s1
ORDER BY Score DESC;
效果为: