版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_43215250/article/details/90043155
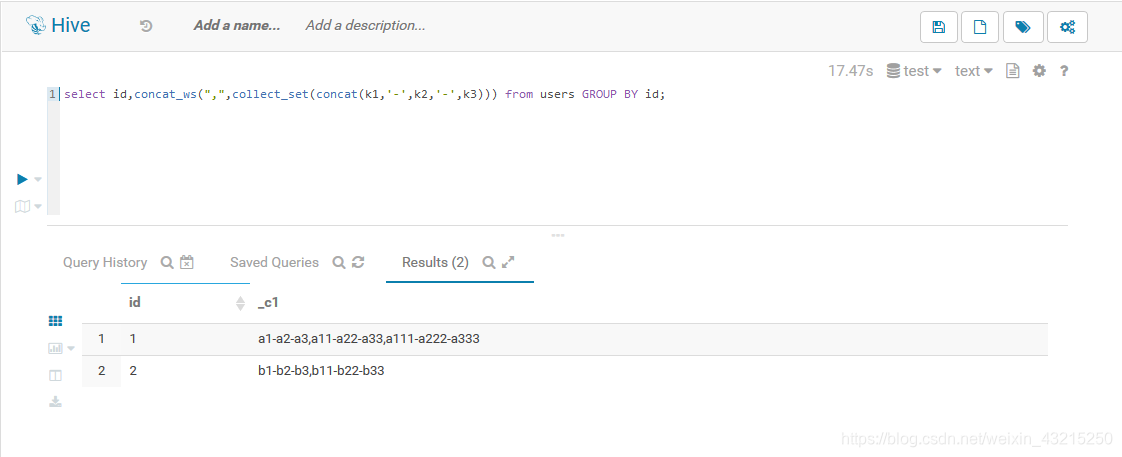
-
保存结果到本地
方法一:通过重定向方式,将查询结果写到指定的文件中
hive -e "SELECT id,concat_ws(',',collect_set(concat(k1,'-',k2,'-',k3))) from test.users GROUP BY id;" > users.data查看
[root@node00 ~]# cat users.data 1 a1-a2-a3,a11-a22-a33,a111-a222-a333 2 b1-b2-b3,b11-b22-b33方法二:使用
INSERT OVERWRITE LOCAL DIRECTORY保存结果到本地hive -e " INSERT OVERWRITE LOCAL DIRECTORY '/home/charles/users.data' ROW format delimited fields terminated BY '\t' SELECT id,concat_ws(',',collect_set(concat(k1,'-',k2,'-',k3))) from test.users GROUP BY id; "查看
[root@node00 charles]# ll -a users.data total 16 -rw-r--r-- 1 root root 61 May 9 17:24 000000_0 -rw-r--r-- 1 root root 12 May 9 17:24 .000000_0.crc [root@node00 charles]# cat users.data/000000_0 1 a1-a2-a3,a11-a22-a33,a111-a222-a333 2 b1-b2-b3,b11-b22-b33 -
保存结果到HDFS中
hive -e " INSERT OVERWRITE DIRECTORY '/users.data' ROW format delimited fields terminated BY '\t' SELECT id,concat_ws(',',collect_set(concat(k1,'-',k2,'-',k3))) from test.users GROUP BY id; "查看
[root@node00 ~]# hdfs dfs -ls /users.data Found 1 items -rwxrwxrwx 3 root supergroup 61 2019-05-09 17:28 /users.data/000000_0 [root@node00 ~]# hdfs dfs -cat /users.data/000000_0 1 a1-a2-a3,a11-a22-a33,a111-a222-a333 2 b1-b2-b3,b11-b22-b33