PyTorch 动态计算图
在讨论 PyTorch 的各个组件前,我们需要了解它的工作流。PyTorch 使用一种称之为 imperative / eager 的范式,即每一行代码都要求构建一个图,作为定义完整计算图的一个部分。即使完整的计算图还没有完成构建,我们也可以独立地执行这些作为组件的小计算图,这种动态计算图被称为「define-by-run」方法。这种方法相比静态计算图更适合调试和科研。

此段文字转载自机器之心
Pytorch张量
pytorch的张量和numpy非常相似。
import torch
#coding=utf-8
x = torch.Tensor(5,3) # 创建一个张量
print(x)
x = torch.rand(5,3) # 随机初始化
print(x)
print(x.size()) # 获取size
print(x[:,2]) # 切片
## tensor和numpy互相转换
import numpy as np
# tensor转numpy
a = torch.ones(5)
print(a)
b = a.numpy()
print(b)
# numpy转tensor
a = np.ones(5)
b = torch.from_numpy(a)
np.add(a,1,out=a) # 转换本质其实还是共享同一块内存,使用加法可以验证这一点
print(a)
print(b)
## 将张量和模型放到gpu
# 查看内存占用,需要pip install nvidia-ml-py3
import pynvml
pynvml.nvmlInit()
handle = pynvml.nvmlDeviceGetHandleByIndex(0) # 这里的0是GPU id
a = torch.rand([5,5])
print(a)
meminfo = pynvml.nvmlDeviceGetMemoryInfo(handle)
print(meminfo.used) # 查看显存占用
a= a.cuda()
print(a)
meminfo = pynvml.nvmlDeviceGetMemoryInfo(handle)
print(meminfo.used) # 内存增加了几百兆,这主要是一些初始化占用的,a只占用了几个byte
import torchvision
model = torchvision.models.resnet50()
meminfo = pynvml.nvmlDeviceGetMemoryInfo(handle)
print(meminfo.used) # 当前model在cpu中
model = model.cuda()
meminfo = pynvml.nvmlDeviceGetMemoryInfo(handle)
print(meminfo.used) # model放到gpu中,增加了100多兆,这个应该是模型大小
for i in model.parameters(): # 输出模型第一层参数,确认是否放入gpu,tensor的最后可以看到device='cuda:0'
print(i)
break
print(i.shape) # model 第一层的参数 64 3 7 7
model = model.cpu() # 模型放回cpu
meminfo = pynvml.nvmlDeviceGetMemoryInfo(handle)
print(meminfo.used)
for i in model.parameters():
print(i)
break
# cpu和gpu耗时对比
import torch,torchvision,time
def function_gpu():
model = torchvision.models.resnet50()
imgs = torch.rand(32,3,224,224)
model = model.cuda()
imgs = imgs.cuda()
bt = time.time()
output = model(imgs)
et = time.time()
print(et-bt)
return output
def function_cpu():
model = torchvision.models.resnet50()
imgs = torch.rand(32,3,224,224)
bt = time.time()云
output = model(imgs)
et = time.time()
print(et - bt)
return output
output = function_gpu() # 显存溢出,调用nvidia-smi,显示cuda10.0,调用nvcc -V显示cuda9.0,有问题
print(output)
output = function_cpu()
print(output)
# 结果对比
# 0.14794516563415527
# 1.881101131439209
第一个网络mnist
网络初始化和前向传播
就像学编程语言的hello world一样,学习深度学习框架第一个代码一定是minst。
mnist数据集不多介绍,输入图片分辨率为28×28=784,网络输出0~9,显然是一个分类网络。
下面就通过mnist来学习pytorch。
Pytorch实现一个深度学习模型,需要用户实现网络初始化和前向传播两个部分,至于反向传播会自动推导(反传的推导是整个深度模型最难的部分,pytorch已经帮我们做好了,这也是为什么要使用深度学习模型的意义)。
class Net(nn.Module): # 我们通过一个Net类来实现深度模型,它需要继承nn.Module
def __init__(def): # 网络初始化
super(Net, self).__init__()
self.l1 = nn.Linear(784,520)
self.l2 = nn.Linear(520,320)
self.l3 = nn.Linear(320,240)
self.l4 = nn.Linear(240,120)
self.l5 = nn.Linear(120,10)
在__init__(self)函数中我们使用nn.Linear(in,out)定义了5层全连接网络,__init__(self)函数定义好之后,网络在内存或者显存的空间占用量就已经定义好了。
网络初始化之后,我们需要确定每层网络之间的关系,也就是网络的流向,即前向传播。
class Net(nn.Module): # 还是在Net类中
def forward(self, x):
x = x.view(-1, 784) # 使用view函数,将输入(n, 1, 28, 28)展平成(n, 784)
x = F.relu(self.l1(x)) # 添加激活函数relu
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
x = F.relu(self.l5(x))
return F.log_softmax(x) # 最后的输出套一个softmax,将值域限制在[0,1]之内
可以看到,view、relu、softmax等函数本质上不需要我们去初始化,所以写在forward里了
dataloader/dataprivder
深度学习使用随机梯度下降SGD进行训练,每次需要传入一批数据(batch),如何将数据集划分为一个一个的batch呢?我们需要一个dataloader/dataprivder。
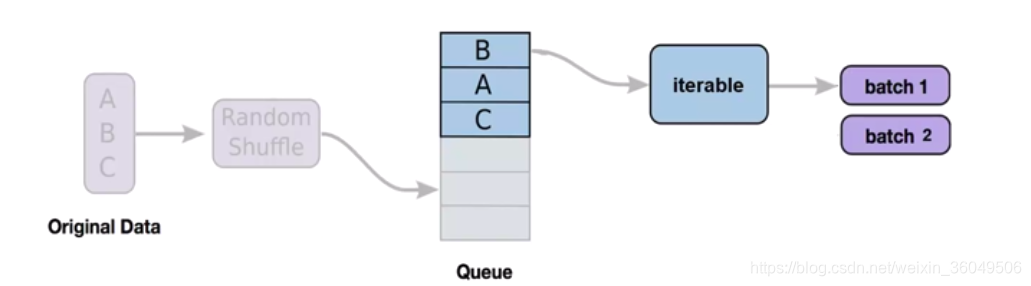
看一下dataloader如何使用:
# dataloader需要传入符合下面这个数据类的功能的实例
class CustomDataset(Dataset): # 需要继承pytorch的Dataset
def __init__(self):
# read data, initial data, prepare data, etc
def __getitem__(self,index):
# return one item on the index
def __len__(self):
return the data length
dataset = CustomDataset()
trainloader = DataLoader(dataset=dataset, # 一个数据类的实例
batch_size=32, # 一个batch的大小
shuffle=True, # 是否需要随机打乱,对于train一般为True,test一般为False
num_workers=2) # 调用的线程数
从上面我们可以看到我们只需要实现一个数据类,就可以使用dataloader
下面给出一个数据类的例子:
class CustomDataset(Dataset):
def __init__(self):
xy = np.loadtxt('data-diabetes.csv',delimiter=',',dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:,0:-1])
self.y_data = torch.from_numpy(xy[:,[-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
参考自https://blog.csdn.net/zw__chen/article/details/82806900
优化器和损失函数
了解过优化的应该知道,优化器能够自动选择梯度更新的步长,使得网络更快的收敛,减少训练时间。
例子:
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = torch.optim.Adam([var1, var2], lr=0.0001)
参考自https://ptorch.com/docs/1/optim
损失函数是指导神经网络学习的方向的,换句话说,优化器本质上更新的是损失函数的梯度。
criterion = nn.L1Loss() # L1 损失
loss = criterion(sample, target)
print(loss)
参考自https://blog.csdn.net/jacke121/article/details/82812218
训练过程
下面我们看一下整个的训练过程,我们将它定义成train函数:
def train(epoch):
model.train()
for batch_idx, (data, target) in eumerate(train_loader): # 从dataloader里抽batch
optimizer.zero_grad() # 初始化优化器
output = model(data) # 计算前传
loss = F.nll_loss(output, target) # 计算损失
loss.backward() # 反传
optimizer.step() # 显然,优化,也就是更新权重,要在反传之后
if batch_idx % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
完整代码
#coding=utf-8
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
# training settings
batch_size = 64
# mnist dataset
train_dataset = datasets.MNIST(root='./mnist_data/',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.MNIST(root='./mnist_data/',
train=False,
transform=transforms.ToTensor())
# data loader (input pipeline)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = nn.Linear(784, 520) # 全连接层
self.l2 = nn.Linear(520, 320)
self.l3 = nn.Linear(320, 240)
self.l4 = nn.Linear(240, 64)
self.l5 = nn.Linear(64, 10)
def forward(self, x):
# Flatten the data (n, 1, 28, 28) -> (n, 784)
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
x = self.l5(x)
return F.log_softmax(x)
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# torch.nn.Conv2d(in_channels, out_channels, kernel_size)
# nn.MaxPool2d(kernel_size)
# 定义卷积层,1个输入通道,6个输出通道,5*5的卷积filter,外层补上了两圈0,使得第一次卷积后尺寸不变
self.conv1 = nn.Conv2d(1, 6, 5, padding=2)
# 第二个卷积层,6个输入,16个输出,5*5的卷积filter
self.conv2 = nn.Conv2d(6, 16, 5)
# 最后是三个全连接层
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 先卷积,然后调用relu激活函数,再最大值池化操作
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 第二次卷积+池化操作
x = F.max_pool2d(F.relu(self.conv2(x)), (2, 2))
# 重新塑形,将多维数据重新塑造为二维数据,256*400
x = x.view(-1, self.num_flat_features(x))
# print('size', x.size())
# 第一个全连接
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return F.log_softmax(x)
def num_flat_features(self, x):
# x.size()返回值为(256, 16, 5, 5),size的值为(16, 5, 5),256是batch_size
size = x.size()[1:] # x.size返回的是一个元组,size表示截取元组中第二个开始的数字
num_features = 1
for s in size:
num_features *= s
return num_features
# model = Net()
model = LeNet()
model = nn.DataParallel(model).cuda() # 为了使用cuda的并行优化
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # 更新整个模型的参数
# 如果只想更新l1层,使用model.l1()即可
def train(epoch):
model.train() # model.eval()会使网络固定不动
for batch_idx, (data, target) in enumerate(train_loader):
data = data.cuda()
target = target.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test():
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.cuda()
target = target.cuda()
output = model(data)
test_loss = criterion(output, target).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Acc: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
for epoch in range(1, 10):
train(epoch)
test()
## 实验结果
# Net类 最后一个全连接不加relu效果更好
# FC,relu,FC,relu,FC,relu,FC,relu,FC,softmax acc=96%
# FC,relu,FC,relu,FC,relu,FC,relu,FC,relu,softmax acc=87%
# LeNet类
# Conv relu maxpool Conv relu maxpool FC relu FC relu FC acc=98%
# Conv relu maxpool Conv relu maxpool FC relu FC relu FC softmax acc=98%