MongoDB查询与游标详解
游标定义:是一种能从数据记录的结果集中每次提取一条记录的机制
游标作用:可以随意控制最终结果集的返回,如限制返回数量、跳过记录、按字段排序、设置游标超时等。
MongoDB中的游标
对于MongoDB每个查询默认返回一个游标,游标包括定义、打开、读取、关闭。
MongoDB游标生命周期
游标声明 var cursor=db.collection.find({xxx}) (MongoDB单条记录的最大大小是16M)
打开游标 cursor.hasNext() 游标是否已经迭代到了最后(正在访问数据库)
读取游标 cursor.Next() 获取游标下一个文档(正在访问数据库)
关闭游标 cursor.close() 通常迭代完毕会自动关闭,也可以显示关闭
MongoDB游标常见方法
cursor.batchSize(size) 指定游标从数据库每次批量获取文档的个数限制
cursor.count() 统计游标中记录总数
cursor.explain(verbosity) 输出对应的执行计划
cursor.forEach() 采用js函数forEach对每一行进行迭代
cursor.hasNext() 判断游标记录是否已经迭代完毕
cursor.hint(index) 认为强制指定优化器的索引选择
cursor.limit() 指定游标返回的最大记录数
cursor.maxTimeMS(time) 指定游标两次getmore间隔的最大处理时间(毫秒)推荐
cursor.next() 返回游标下一条记录
cursor.noCursorTimeout() 强制不自动对空闲游标进行超时时间计算(默认10分钟)慎用
MongoDB shell下游标示例 1
隐式游标
db.t2.find() // 默认迭代20次,其后采用it手动迭代
DBQuery.shellBatchSize = 10 调整游标每批次返回的记录数
显示游标
var cursor = db.test.find() 游标定义,此时不会正在访问数据库
while (cursor.hasNext()){
printjson(cursor.next())}
或
db.test.find().forEach(function(e){printjson(e)}) 匿名游标迭代
MongoDB shell下游标示例 2
游标方法hint()
db.person.find({age:1,name:"andy"}).explain()
db.person.find({age:1,name:"andy"}).hint("age_1_name_1").explain()
游标方法maxTimeMS(time)
DBQuery.shellBatchSize = 100000
db.t2.find({type:3}).maxTimeMS(1)
修改游标超时时间
db.adminCommand( { setParameter: 1, cursorTimeoutMillis: 300000 } )
MongoDB游标最佳实践
游标超时时间与batchsize大小需计算好,避免在getmore时发生不必要的超时
如果业务只需要第一批迭代则查询时可指定singleBatch:True及时关闭游标
MongoDB游标状态信息
db.serverStatus().metrics.cursor
MongoDB索引原理及优化
MongoDB索引原理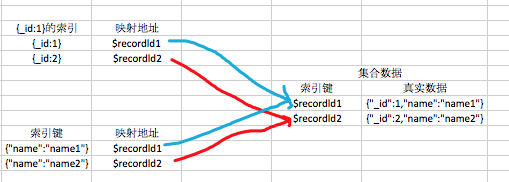
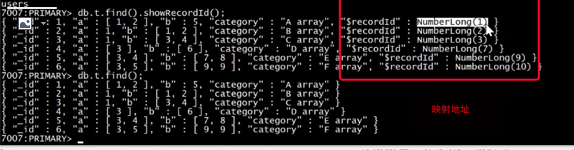
db.index.find({}).showRecordId()
可以理解为每条记录对应的映射地址
MongoDB索引类型:
db.test.createlndex({socre:1},{background:true,name:"xx_index"})默认创建索引加库级别排它锁,可指定 background为true避免阻塞,默认索引名词:字段名_1 /_-1使用background:true构建索引过程依然会阻塞(同DB下)db.collection.drop(),repairDatabase等命令
可执行db.currentOp()查看索引构建进度也可使用db.killOp()强制中断索引创建。
当副本集/分片节点索引创建被强制中断后可通过指定indexBuildRetry参数控制节点重启后是否自动重建索引,
同时只有当索引构建完毕后才能被对应的查询语句利用
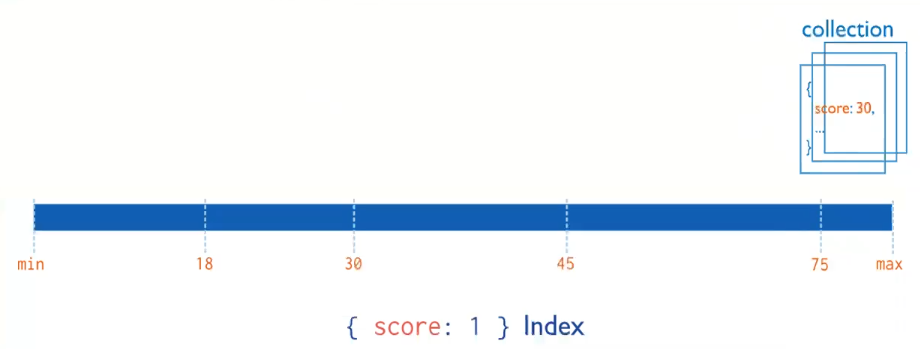
对单列索引而言,升序和降序都能够用到索引db.records.find({score:2})db.records.find({ score : {$gt :10}})
嵌套单列索引:
db.test.find()
{"_id": xxxxxxx,"score:100", "location":{contry:"china",city:beijing}}
在嵌入式文档上创建索引
db.test.createIndex({"location":1},{background:true})
如下查询会被用到
db.test.find({location:{contry:"china",city:"beijing"}})
在嵌入式字段上创建索引
db.test.createIndex({"location.city":1},{background:true})
如下查询会被用到
db.test.find({"location.city":"beijing"})
db.test.find({"location.contry":"chna","location.city":"beijing"})
在嵌入式文档上执行相应匹配命令时,字段顺序和嵌入式文档必须完全匹配
多列索引
db.test2.createIndex(
{"userid" : 1, "score" : -1, " age " :1},{background:true})
索引排序可以简记为:单列索引正反向排序都不受影响,多列索引则是乘以(-1)的排序可以使用相同的索引,即1,1和-1,-1可以使用相同的索引, -1,1和1,-1可以使用相同的索引

最左前缀原则
for (var i = 0 ;i<500000;i++){ db.test10.insert({userid:Math.round(Math.random()*40000),score:Math.round(Math.random()*100),age:Math.round(Math.random()*125)});}
创建索引:db.test10.createindex({"userid":1,"score":-1,"age":1},{background:true})
以下查询可以使用到索引
db.test10.find({userid:1,score:83,age:20});
db.test10.find({score:83,userid:1});
db.test10.find({age:20,score:83,userid:1});
db.test10.find({age:20,userid:1});
以下查询不能使用到索引
db.test10.find({score:83,age:20});
db.test10.find({score:83});
db.test10.find({age:20});
db.test10.find({age:20,score:83});
强制索引
db.test.find({userid:28440,score:88,age:118}).hint("userid_1_score_-1_age_1") ;
索引交集
普通索引跟hash索引的组合
db.test.createIndex({age:1});
db.test.createIndex({age:"hashed"});
db.test.createIndex({score:1});
db.test.createIndex({score:"hashed"});
db.test.find({score:88,age:118}).explain()
是否采用索引交集的标志:
通过explain()查看执行计划的时候会出现AND_SORTED 或 AND_HASG阶段(stage)
or与索引db.test.find( { $or: [ { score: 88 }, { age: 8 } ] } ).explain()索引覆盖db.test.find({userid:681,score:33},{_id:0,age:1}).explain(1)多列索引与排序db.test.find({userid:1,score:{$gt:25}},{_id:0}).sort({userid:1}); //索引可以优化排序db.test.find({userid:1,score:{$gt:25}},{_id:0}).sort({score:-1}); //索引可以优化排序db.test.find({userid:1,score:{$gt:25}},{_id:0}).sort({score:1}); //索引可以优化排序db.test.find({userid:1,score:{$gt:25}},{_id:0}).sort({age:1}); //索引无法优化排序db.test.find({userid:1,score:{$gt:25}},{_id:0}).sort({age:-1});//索引无法优化排序db.test.find({userid:1,score:{$gt:25}},{_id:0}).sort({userid:1,score:-1}); // 可以优化排序db.test.find({userid:1,score:{$gt:25}},{_id:0}).sort({userid:1,score:1}); //不可以优化排序db.test.find({userid:1,score:{$gt:25}},{_id:0}).sort({userid:1,score:-1,age:1}); //索引可以优化排序db.test.find({userid:1,score:{$gt:25}},{_id:0}).sort({userid:1,score:-1,age:-1}); //索引无法优化排序db.test.find({userid:1,score:53,age:{$gt:29}}).sort({userid:1,score:-1,age:1}); //索引可以优化排序db.test.find({userid:1,score:53,age:{$gt:29}}).sort({userid:-1,score:1,age:-1}); //索引可以优化排序db.test.find({userid:1,score:53,age:{$gt:29}}).sort({userid:1,score:-1,age:-1});//索引无法优化排序
多键索引
要索引一个包含数组值的字段,MongoDB会为数组中的每个元素创建一个索引键,这些多键索引支持针对数组字段的高效查询
多键索引可以在包含标量值(例如字符串、数字)和嵌套文档的数组上创建
db.multi_key.createIndex({ratings:1},{background:true})
db.multi_key.insert({ _id: 5, type: "food", item: "aaa", ratings: [ 5, 8, 9 ] })
db.multi_key.insert({ _id: 6, type: "food", item: "bbb", ratings: [ 5, 9 ] })
db.multi_key.insert({ _id: 7, type: "food", item: "ccc", ratings: [ 9, 5, 8 ] })
db.multi_key.insert({ _id: 8, type: "food", item: "ddd", ratings: [ 9, 5 ] })
db.multi_key.insert({ _id: 9, type: "food", item: "eee", ratings: [ 5, 9, 5 ] })
限制:
不许创建两个数组组合索引
不允许创建hash多key索引
不能指定为shard key索引
文本索引
一个集合最多只能创建一个文本索引
db.reviews.createlndex({ comment: "text" })
可以对多个字段创建文本索引
db.reviews.createlndex({subject:"text", comment: "text" })
2dsphere索引
2d索引
Hash索引
哈希索引通过索引字段的哈希值来维护条目
使用哈希分片键对集合进行分片会导致数据分布更加随机和均匀
哈希索引使用散列函数来计算索引字段的哈希值。哈希索引不支持多键(即数组)索引
创建哈希索引:
db.coll.createindex({_id:"hashed"})
不可创建具有哈希索引字段的复合索引,或者对哈希索引指定唯一约束。但是,可以在一个字段上同时创建哈希索引和升序/降序(即非哈希)索引
索引属性
唯一索引
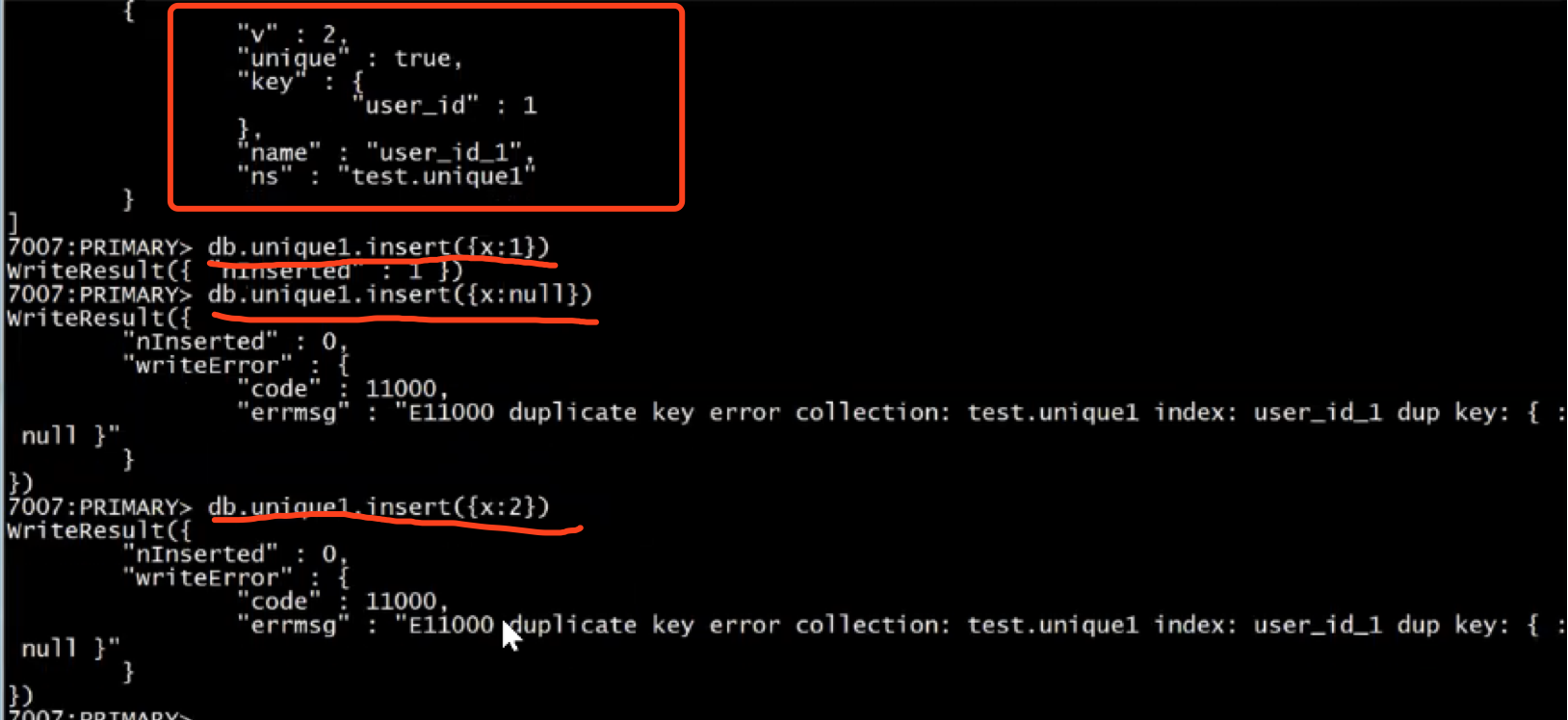
强制索引字段不含有重复值,默认情况下MongoDB会为_id字段创建唯一性索引
关键字:{unique:true}
唯一性索引创建:
db.unique1.createIndex({"user_id":1},{unique:true})
db.unique2.createIndex({"name":1,"birthday":1},{unique:true})
限制:
如果集合已经包含违反索引唯一约束的数据,则MongoDB无法再指定的索引字段上创建唯一索引
不能在Hash索引上指定唯一约束
唯一索引对缺失列的处理
如果文档在唯一索引中没有索引字段的值,则索引将为此文档存储null值。由于唯一的约束,MongoDB将只允许一个缺失索引字段的文档。
如果有多个文档没有索引字段的至或缺少索引字段,则在添加唯一索引时将失败,并报出重复键错误。
对集合的部分文档进行索引 :db.t.createIndex({ category: 1 },{ partialFilterExpression: { _id: { $gt: 2 } } } )
partialFilterExpression支持的选项:
等值表达式(如 field: value或使用$eq操作符)
$exists:true 表达式
$gt,$gte,$lt,$lte表达式
$type 表达式
第一层级的$and操作符
部分索引的使用
db.t.find({"category":"F array",_id:{$gt:1}}).explain() //无法利用部分索引
db.t.find({"category":"F array",_id:{$gt:3}}).explain() //可以利用部分索引
查询要使用部分索引则查询条件必须与索引表达式相同或是其子集
部分索引与唯一性
db.users.insert( { username: "david", age: 25 } )
db.users.insert( { username: "amanda", age: 26 } )
db.users.insert( { username: "andy", age: 30 } )
db.users.createIndex({ username: 1 },{ unique: true, partialFilterExpression: { age: { $gte: 20 } } })
再次插入用户名为andy年龄为13(不在$gte:20的范围)的文档
db.users.insert( { username: "andy", age: 13} ) //插入成功
限制
_id索引不可以是部分索引
shard key索引不可以是部分索引
稀疏索引
指仅仅包含具有索引字段的文档,稀疏索引可以认为是部分索引的子集
稀疏索引的创建
db.collection.insert({ y: 1 } );
db.collection.createIndex( { x: 1 }, { sparse: true } );
稀疏索引与hint
db.collection.find().hint( { x: 1 } ).count();
db.collection.find().hint( { x: 1 } ) ;
稀疏索引与唯一性
db.collection.createIndex( { z: 1 } , { sparse: true, unique: true } )
db.collection.insert({y:2}) // 正常
db.collection.insert({y:3}) // 正常
TTL索引
TTL索引在索引字段值超过指定的秒数后过期文档; 即,到期阈值是索引字段值加上指定的秒数。
如果字段是数组,并且索引中有多个日期值,则MongoDB使用数组中的最低(即最早)日期值来计算到期阈值。
如果文档中的索引字段不是日期或包含日期值的数组,则文档将不会过期。
如果文档不包含索引字段,则文档不会过期。
在后台创建TTL索引时,TTL索引可以在构建索引时删除文档。如果在前台构建TTL索引,则在索引构建完毕后立即删除过期文档
TTL索引的创建
db.exp.insert({lastDate:new Date()})
db.exp.createIndex({"lastDate":1},{expireAfterSeconds:60})
在线修改TTL过期时间
db.runCommand({collMod:"exp",index{keyPattern:{lastDate:1},expireAfterSeconds:120}})
查询数据库下的所有索引
db.getCollectionNames().forEach(function(collection) {
indexes = db[collection].getIndexes();
print("Indexes for " + collection + ":");
printjson(indexes);});
索引统计信息
db.serverStatus(scale)的统计输出
metrics.queryexecutor.scanned:查询和查询计划评估期间扫描的索引项的总数。盖计数器与explain()输出中totalkeysexamamed意思相同
metrics.operation.scanAndOrder:表示无法使用索引排序的查询总次数
db.users.stats(scale)的统计输出
totalindexSize:所有索引的总大小。scale参数影响输出。如一个索引使用前缀压缩(WiredTiger的默认),则返回的大小为索引的压缩大小
indexSizes:指定集合上每个现有索引对应的键和大小。scale参数影响输出
db.stats(scale)的统计输出
indexes:在此数据库中所有集合的索引总数目
indexSize:在此数据库中创建的所有索引的总大小。scale参数影响输出
索引设计原则
1、每个查询原则上都需要创建对应索引
2、单个索引设计应考虑满足尽量多的查询
3、索引字段选择及顺序需要考虑查询覆盖率及选择性
4、对于更新及其频繁的字段上创建索引需慎重
5、对于数组索引需要慎重考虑未来元素个数
6、对于超长字符串类型字段上慎用B数索引
7、并发更新较高的单个集合上不宜创建过多索引
MongoDB通用优化建议与实践
MongoDB查询缓存逻辑
索引选择基于采样代价模型,查询第一次执行如果有多个执行计划则会根据模型选出最优计划并缓存
语句执行会根据执行计划的表现对缓存进行重用或重建,如多次迭代都没有返回足够的文档则可能会触发重构
当MongoDB创建或删除索引时,会将对应集合的缓存执行计划清空并重新选择
如果MongoDB重新启动或关闭,则查询计划缓存会被清理然后依据查询进行重建
MongoDB查询缓存操作
db.eof.find({x:1}); db.eof.find({x:3}).sort({y:1}); 执行查询模拟查询计划缓存
db.eof.getPlanCache().listQueryShapes(); 查询对应集合的查询计划缓存指纹
db.eof.getPlanCache().getPlansByQuery({"x":1},{},{"y":1}); 通过指纹查看查询计划缓存信息
注:查询指纹或叫形状是由query条件、sort条件及projection(投影)组成
db.eof.getPlanCache().clearPlansByQuery({"x":1},{},{"y":1}) 通过指定指纹清空对应查询计划缓存
db.eof.getPlanCache().clear() 清空对应集合所有执行计划的缓存信息
查询计划详解
支持查询计划的操作
aggregate()
count()
distinct()
find()
group()
remove()
update()
findAndModify()
查询计划语法:
1、db.collection.explain(verbosity).<method(...)> 返回游标mongo shell 默认迭代
2、db.collection.<method(...)>.explain(verbosity) 返回json文档化结果
查询计划详解:
queryPlanner模式
MongoDB通过查询优化器对查询评估后选择一个最佳的查询计划(默认模式)
executionStats模式
MongoDB通过查询优化器对查询进行评估并选择一个最佳的查询计划执行后返回统计信息
对于写操作则返回关于更新和删除操作的统计信息,但并不真正修改数据库数据
对于非最优执行计划不返回对于统计信息
allPlansExecution模式
与上述两种模式的差别是除返回两种模式的信息的同时还包含非最优计划执行的统计信息
ceshi27020_mongo:PRIMARY> db.eof.find({x:2100}).explain()
{ "queryPlanner" : { //查询计划信息
"plannerVersion" : 1, //查询计划版本
"namespace" : "test.eof", //查询集合
"indexFilterSet" : false, //查询过滤器
"parsedQuery" : { //查询具体条件
"x" : {
"$eq" : 2100
}
},
"winningPlan" : { //最优计划
"stage" : "FETCH", //获取文档阶段
"inputStage" : { // 过滤条件
"stage" : "IXSCAN", //索引扫描阶段
"keyPattern" : { //要遍历的索引
"x" : 1
},
"indexName" : "idx_x", //索引名称
"isMultiKey" : false, //是否是多key索引
"isUnique" : false, //是否是唯一索引
"isSparse" : false, //是否是稀疏索引
"isPartial" : false, //是否是部分索引
"indexVersion" : 1, //索引版本号
"direction" : "forward", //索引扫描方向(forward对应1,backward对应-1)
"indexBounds" : { //索引扫描的边界
"x" : [ "[2100.0, 2100.0]"] } } }, "rejectedPlans" : [ ] },
"serverInfo" : {
"host" : "LeDB-VM-124064213",
"port" : 27020,
"version" : "3.2.20",
"gitVersion" : "a7a144f40b70bfe290906eb33ff2714933544af8" }, "ok" : 1}