横表就是普通的建表方式,如一个表结构为:
主键、字段1、字段2、字段3。。。
如果变成纵表后,则表结构为:
主键、字段代码、字段值。
而字段代码则为字段1、字段2、字段3。
具体为电信行业的例子。以用户帐单表为例一般出账时用户有很多费用客户,其数据一般存储为:时间,客户ID,费用科目,费用。这种存储结构一般称为纵表,其特点是行数多,字段少。 纵表在使用时由于行数多,统计用户数或对用户进行分档时还需要进行GROUP BY 操作,性能低,且操作不便,为提高性能,通常根据需要将纵表进行汇总,形成横表,比如:时间、客户ID,基本通话费、漫游通话费,国内长途费、国际长途费…。通常形成一个客户一行的表,这种表统计用户数或做分档统计时比较方便。另外,数据挖掘时用到的宽表一般也要求是横表结构。
纵表对从数据库到内存的映射效率是有影响的,但细一点说也要一分为二:
纵表的初始映射要慢一些;
纵表的变更的映射可能要快一些,如果只是改变了单个字段时,毕竟横表字段比纵表要多很多。
我想这个还是在讨论如何优化数据库数据结构的问题,而我的意见是:如果有可能,还是不要用数据库的好,呵呵。
另:我亲身遭受过帐务系统表的横表和纵表的问题的折磨,横表使结构一目了然,但几乎不能扩展,当用户部署新业务时捉襟见肘,纵表似乎有无限的扩展性,但代价是有些凌乱,不便于理解,更要命的是数据管理上不够安全,我就知道某地方的帐务系统帐务配置表(纵表)被某位专家级操作者无意删除了一条,就是一条啊!结果…,而横表,你要改他的结构不是那么容易的,不过两者对帐务程序性能的影响几乎没有任何区别。
MS SQL Server
纵表、横表互转的SQL
1、建表:
纵表结构 Table_A
create table Table_A
(
姓名 varchar(20),
课程 varchar(20),
成绩 int
)
insert into Table_A(姓名,课程,成绩) values(‘张三’,‘语文’,60)
insert into Table_A(姓名,课程,成绩) values(‘张三’,‘数学’,70)
insert into Table_A(姓名,课程,成绩) values(‘张三’,‘英语’,80)
insert into Table_A(姓名,课程,成绩) values(‘李四’,‘语文’,90)
insert into Table_A(姓名,课程,成绩) values(‘李四’,‘数学’,100)
姓名 课程 成绩
张三 语文 60
张三 数学 70
张三 英语 80
李四 语文 90
李四 数学 100
横表结构 Table_B
create table Table_B
(
姓名 varchar(20),
语文 int,
数学 int,
英语 int
)
insert into Table_B(姓名,语文,数学,英语) values(‘张三’,60,70,80)
insert into Table_B(姓名,语文,数学,英语) values(‘李四’,90,100,0)
姓名 语文 数学 英语
张三 60 70 80
李四 90 100 0
2、纵表变横表
纵表结构 Table_A --> 横表结构 Table_B
方法一:聚合函数[max或sum]配合case语句
select 姓名,
sum (case 课程 when ‘语文’ then 成绩 else 0 end) as 语文,
sum (case 课程 when ‘数学’ then 成绩 else 0 end) as 数学,
sum (case 课程 when ‘英语’ then 成绩 else 0 end) as 英语
from Table_A
group by 姓名
方法二:使用pivot
select * from Table_A pivot (max(成绩)for 课程 in(语文,数学,英语)) 临时表
3、横表变纵表
横表结构 Table_B --> 纵表结构 Table_A
方法一:union all
select 姓名,‘语文’ as 课程,语文 as 成绩 from Table_B union all
select 姓名,‘数学’ as 课程,数学 as 成绩 from Table_B union all
select 姓名,‘英语’ as 课程,英语 as 成绩 from Table_B
order by 姓名,课程 desc
方法二:使用unpivot
select 姓名,课程,成绩 from Table_B
unpivot
(成绩 for 课程 in ([语文],[数学],英语)) 临时表
说明:在实际开发中表名,列名不应该使用汉字,在插入的值中有汉字的应该用N修饰,以防止出现乱码,出现意想不到的结果,可能产生2异性的表名可以用[]修饰。
例如:
insert into Table_B(name,chinese,math,english) values(N’张三’,60,70,80)
create table [user]
oracle SQL 实现竖表转横表
T_T_STUDENT表查询记录如下,要转成横表
姓名 课程 成绩
1 张飞 语文 80
2 张飞 数学 87
3 关羽 语文 97
4 张飞 英语 68
5 关羽 数学 53
6 刘备 语文 90
方法一:
–用decode实现,
SELECT T.NAME,
SUM(DECODE(T.Course, ‘语文’, T.Score)) 语文,
SUM(DECODE(T.Course, ‘数学’, T.Score)) 数学,
SUM(DECODE(T.Course, ‘英语’, T.Score)) 英语
FROM T_T_STUDENT T
GROUP BY T.NAME
方法二:
–用case when 实现
SELECT T.NAME,
SUM(CASE T.Course WHEN ‘语文’ THEN T.Score ELSE 0 END) 语文,
SUM(CASE T.Course WHEN ‘数学’ THEN T.Score ELSE 0 END) 数学,
SUM(CASE T.Course WHEN ‘英语’ THEN T.Score ELSE 0 END) 英语
FROM T_T_STUDENT T
GROUP BY T.NAME
输出结果如下:
姓名 语文 数学 英语
1 刘备 90 94 92
2 关羽 97 53 95
3 张飞 80 87 68
区别如果条件是单一值时,用decode比较简便,如果判断条件比较复杂是用case when实现
普通行列转换
假设有张学生成绩表(tb)如下:
Name Subject Result
张三 语文 74
张三 数学 83
张三 物理 93
李四 语文 74
李四 数学 84
李四 物理 94
*/
/*
想变成
姓名 语文 数学 物理
李四 74 84 94
张三 74 83 93
*/
create table tb
(
Name varchar(10) ,
Subject varchar(10) ,
Result int
)
insert into tb(Name , Subject , Result) values(‘张三’ , ‘语文’ , 74)
insert into tb(Name , Subject , Result) values(‘张三’ , ‘数学’ , 83)
insert into tb(Name , Subject , Result) values(‘张三’ , ‘物理’ , 93)
insert into tb(Name , Subject , Result) values(‘李四’ , ‘语文’ , 74)
insert into tb(Name , Subject , Result) values(‘李四’ , ‘数学’ , 84)
insert into tb(Name , Subject , Result) values(‘李四’ , ‘物理’ , 94)
go
–静态SQL,指subject只有语文、数学、物理这三门课程。
select name 姓名,
max(case subject when ‘语文’ then result else 0 end) 语文,
max(case subject when ‘数学’ then result else 0 end) 数学,
max(case subject when ‘物理’ then result else 0 end) 物理
from tb
group by name
/*
姓名 语文 数学 物理
李四 74 84 94
张三 74 83 93
*/
–动态SQL,指subject不止语文、数学、物理这三门课程。
declare @sql varchar(8000)
set @sql = ‘select Name as ’ + ‘姓名’
select @sql = @sql + ’ , max(case Subject when ‘’’ + Subject + ‘’’ then Result else 0 end) [’ + Subject + ‘]’
from (select distinct Subject from tb) as a
set @sql = @sql + ’ from tb group by name’
exec(@sql)
/*
姓名 数学 物理 语文
李四 84 94 74
张三 83 93 74
*/
/*加个平均分,总分
姓名 语文 数学 物理 平均分 总分
李四 74 84 94 84.00 252
张三 74 83 93 83.33 250
*/
–静态SQL,指subject只有语文、数学、物理这三门课程。
select name 姓名,
max(case subject when ‘语文’ then result else 0 end) 语文,
max(case subject when ‘数学’ then result else 0 end) 数学,
max(case subject when ‘物理’ then result else 0 end) 物理,
cast(avg(result1.0) as decimal(18,2)) 平均分,
sum(result) 总分
from tb
group by name
/
姓名 语文 数学 物理 平均分 总分
李四 74 84 94 84.00 252
张三 74 83 93 83.33 250
*/
–动态SQL,指subject不止语文、数学、物理这三门课程。
declare @sql1 varchar(8000)
set @sql1 = ‘select Name as ’ + ‘姓名’
select @sql1 = @sql1 + ’ , max(case Subject when ‘’’ + Subject + ‘’’ then Result else 0 end) [’ + Subject + ‘]’
from (select distinct Subject from tb) as a
set @sql1 = @sql1 + ’ , cast(avg(result1.0) as decimal(18,2)) 平均分,sum(result) 总分 from tb group by name’
exec(@sql1)
/
姓名 数学 物理 语文 平均分 总分
李四 84 94 74 84.00 252
张三 83 93 74 83.33 250
*/
drop table tb
/*
如果上述两表互相换一下:即
姓名 语文 数学 物理
张三 74 83 93
李四 74 84 94
想变成
Name Subject Result
李四 语文 74
李四 数学 84
李四 物理 94
张三 语文 74
张三 数学 83
张三 物理 93
*/
create table tb1
(
姓名 varchar(10) ,
语文 int ,
数学 int ,
物理 int
)
insert into tb1(姓名 , 语文 , 数学 , 物理) values(‘张三’,74,83,93)
insert into tb1(姓名 , 语文 , 数学 , 物理) values(‘李四’,74,84,94)
select * from
(
select 姓名 as Name , Subject = ‘语文’ , Result = 语文 from tb1
union all
select 姓名 as Name , Subject = ‘数学’ , Result = 数学 from tb1
union all
select 姓名 as Name , Subject = ‘物理’ , Result = 物理 from tb1
) t
order by name , case Subject when ‘语文’ then 1 when ‘数学’ then 2 when ‘物理’ then 3 when ‘总分’ then 4 end
/*加个平均分,总分
Name Subject Result
李四 语文 74.00
李四 数学 84.00
李四 物理 94.00
李四 平均分 84.00
李四 总分 252.00
张三 语文 74.00
张三 数学 83.00
张三 物理 93.00
张三 平均分 83.33
张三 总分 250.00
*/
select * from
(
select 姓名 as Name , Subject = ‘语文’ , Result = 语文 from tb1
union all
select 姓名 as Name , Subject = ‘数学’ , Result = 数学 from tb1
union all
select 姓名 as Name , Subject = ‘物理’ , Result = 物理 from tb1
union all
select 姓名 as Name , Subject = ‘平均分’ , Result = cast((语文 + 数学 + 物理)*1.0/3 as decimal(18,2)) from tb1
union all
select 姓名 as Name , Subject = ‘总分’ , Result = 语文 + 数学 + 物理 from tb1
) t
order by name , case Subject when ‘语文’ then 1 when ‘数学’ then 2 when ‘物理’ then 3 when ‘平均分’ then 4 when’总分’ then 5 end
drop table tb1
动态列转行
----------------新建测试表
CREATE TABLE tmp_user_2(USER_ID NUMBER,MODE_NAME VARCHAR2(100),TYPE_ID NUmBER);
----------------第一部分测试数据
INSERT INTO tmp_user_2 VALUES(1001, ‘M1’,1);
INSERT INTO tmp_user_2 VALUES(1001, ‘M2’,2);
INSERT INTO tmp_user_2 VALUES(1002, ‘M1’,3);
INSERT INTO tmp_user_2 VALUES(1002, ‘M2’,4);
INSERT INTO tmp_user_2 VALUES(1002, ‘M3’,5);
INSERT INTO tmp_user_2 VALUES(1003, ‘M1’,6);
COMMIT;
----------------行转列存储过程
CREATE OR REPLACE PROCEDURE P_tmp_user_2 IS
V_SQL VARCHAR2(2000);
CURSOR CURSOR_1 IS
SELECT DISTINCT T.MODE_NAME FROM tmp_user_2 T ORDER BY MODE_NAME;
BEGIN
V_SQL := ‘SELECT USER_ID’;
FOR V_XCLCK IN CURSOR_1 LOOP
V_SQL := V_SQL || ‘,’ || ‘SUM(DECODE(MODE_NAME,’’’ || V_XCLCK.MODE_NAME ||
‘’’,TYPE_ID,0)) AS ’ || V_XCLCK.MODE_NAME;
END LOOP;
V_SQL := V_SQL || ’ FROM tmp_user_2 GROUP BY USER_ID’;
–DBMS_OUTPUT.PUT_LINE(V_SQL);
V_SQL := 'CREATE OR REPLACE VIEW tmp_user_3 AS ’ || V_SQL;
–DBMS_OUTPUT.PUT_LINE(V_SQL);
EXECUTE IMMEDIATE V_SQL;
END;
----------------执行存储过程
BEGIN
P_tmp_user_2;
END;
----------------查看结果
SELECT * FROM tmp_user_3;
----------------第二部分测试数据
INSERT INTO tmp_user_2 VALUES(1003, ‘M2’,7);
INSERT INTO tmp_user_2 VALUES(1004, ‘M5’,8);
COMMIT;
----------------执行存储过程
BEGIN
P_tmp_user_2;
END;
----------------查看结果
SELECT * FROM tmp_user_3;
其他 :
一、横表和纵表
横表:通常指我们平时在数据库中建立的表,是一种普通的建表方式。
(主键、字段1、字段2…)如:时间、客户ID,基本通话费、漫游通话费,国内长途费、国际长途费…。
纵表:一般不多见,在表结构不确定的时候,如需增加字段的情况下的一种建表方式。
二、执行效率
横表:后台数据库管理员操作简单,直观,清晰可见,一目了然。但若要给横表中添加一个或者多个字段,就须重建表结构。
纵表:对于横表的弊端,纵表中只需要添加一条记录,就可以添加一个字段,所消耗的代价远比横表小。但是纵表的对于数据描述不是很清晰,而且会造成数据库数量很多。在查询的时候用到group等函数会大大降低执行效率。纵表的初始映射要慢一些,纵表的变更的映射可能要快一些,如果只是改变了单个字段时,毕竟横表字段比纵表要多很多。
三、转换
1.在平时的开发过程中,可能会遇到字段的添加或者更好的维护和管理大数据量的表,就 会涉及到纵表和横表之间的转换。
2.把不容易改动表结构的设计成横表,把容易经常改动不确定的表结构设计成纵表。
举例:
注:DECODE函数是ORACLE PL/SQL的功能强大的函数之一,目前还只有ORACLE公司的SQL提供了此函数,DECODE(value,if1,then1,if2,then2,if3,then3,…,else),表示如果value等于if1时,DECODE函数的结果返回then1,…,如果不等于任何一个if值,则返回else。
sign函数:在数学和计算机运算中,其功能是取某个数的符号(正或负): 当x≥0,sign(x)=1; 当x<0, sign(x)=-1;
纵表转横表
纵表结构: TEST_Z2H
FNAME FTYPE FVALUE
员工 zaocan 10
员工 zhongcan 20
员工 wancan 5
转换后的表结构:
FNAME ZAOCAN_VALUE ZHONGCAN_VALUE WANCAN_VALUE
员工 10 20 5
纵表转横表SQL示例:
SELECT FNAME,
SUM(DECODE(FTYPE,‘zaocan’,FVALUE,0)) AS ZAOCAN_VALUE,
SUM(DECODE(FTYPE,‘zhongcan’,FVALUE,0)) AS ZHONGCAN_VALUE,
SUM(DECODE(FTYPE,‘wancan’,FVALUE,0)) AS WANCAN_VALUE
FROM TEST_Z2H
GROUP BY FNAME;
横表转纵表
横表结构: TEST_H2Z
ID 姓名 语文 数学 英语
1 张三 80 90 70
2 李四 90 85 95
3 王五 88 75 90
转换后的表结构:
ID 姓名 科目 成绩
1 张三 语文 80
2 张三 数学 90
3 张三 英语 70
4 李四 语文 90
5 李四 数学 80
6 李四 英语 99
7 王五 语文 85
8 王五 数学 96
9 王五 英语 88
横表转纵表SQL示例:
SELECT 姓名,‘语文’ AS 科目,语文 AS 成绩 FROM TEST_H2Z UNION ALL
SELECT 姓名,‘数学’ AS 科目,数学 AS 成绩 FROM TEST_H2Z UNION ALL
SELECT 姓名,‘英语’ AS 科目,英语 AS 成绩 FROM TEST_H2Z
ORDER BY 姓名,科目 DESC;
四、这里有一篇用另一种方式实现转换而且带和值查询的博文:http://exceptioneye.iteye.com/blog/1153345
横表就是普通的建表方式,如一个表结构为:
主键、字段1、字段2、字段3。。。
如果变成纵表后,则表结构为:
主键、字段代码、字段值。
而字段代码则为字段1、字段2、字段3。
纵表对从数据库到内存的映射效率是有影响的,但细一点说也要一分为二:
纵表的初始映射要慢一些;
纵表的变更的映射可能要快一些,如果只是改变了单个字段时,毕竟横表字段比纵表要多很多。
横表的好处是清晰可见,一目了然,但是有一个弊端,如果现在要把这个表加一个字段,那么就必须重建表结构。对于这种情况,在纵表中只需要添加一条记录,就可以添加一个字段,所消耗的代价远比横表小,但是纵表的对于数据描述不是很清晰,而且会造成数据库数量很多,两者利弊在于此。所以,应 该把不容易改动表结构的设计成横表,把容易经常改动不确定的表结构设计成纵表。
测试例子:
create table a(name varchar2(12),
math number,
englist number,chinese number);
插入两行记录:
张三 85 90 95
李四 90 85 86
转行查询语句:
SELECT flag, MAX(李四) AS 李四, MAX(张三) AS 张三
FROM (SELECT decode(NAME, ‘李四’, fensu) as 李四,
decode(NAME, ‘张三’, fensu) AS 张三,
flag
FROM (SELECT a.NAME, a.math AS fensu, ‘math’ AS flag
FROM a
UNION ALL
SELECT a.NAME, a.englist AS fensu, ‘englist’ AS flag
FROM a
UNION ALL
SELECT a.NAME, a.chinese AS fensu, ‘chinese’ AS flag FROM a) b
ORDER BY NAME, flag, fensu)
GROUP BY flag
现有emp和dept表
EMP
empno number(4)
ename varchar2(10)
job varchar2(9)
mgr number(4)
hiredate date
sal number(7,2)
comm number(7,2)
deptno number(2)
DEPT
deptno number(2)
dname varchar2(14)
loc varchar2(13)
统计不同部门和工作的员工的总工资
实现横标转换为纵表
decode实现
select d.dname dname,
sum(decode(e.job, ‘CLERK’, e.sal, 0)) CLERK,
sum(decode(e.job, ‘SALESMAN’, e.sal, 0)) SALESMAN,
sum(decode(e.job, ‘ANALYST’, e.sal, 0)) ANALYST,
sum(decode(e.job, ‘MANAGER’, e.sal, 0)) MANAGER,
sum(decode(e.job, ‘PRESIDENT’, e.sal, 0)) PRESIDENT
from emp e
join dept d
on e.deptno = d.deptno
group by d.dname;
case when实现
select d.dname dname,
sum(
case e.job
when ‘CLERK’ then e.sal
else 0
end
) CLERK,
sum(
case e.job
when ‘SALESMAN’ then e.sal
else 0
end
) SALESMAN,
sum(
case e.job
when ‘PRESIDENT’ then e.sal
else 0
end
) PRESIDENT,
sum(
case e.job
when ‘MANAGER’ then e.sal
else 0
end
) MANAGER,
sum(
case e.job
when ‘ANALYST’ then e.sal
else 0
end
) ANALYST
from emp e
join dept d
on e.deptno = d.deptno
group by d.dname;
带合计项的
select d.dname dname,
sum(decode(e.job, ‘CLERK’, e.sal, 0)) CLERK,
sum(decode(e.job, ‘SALESMAN’, e.sal, 0)) SALESMAN,
sum(decode(e.job, ‘ANALYST’, e.sal, 0)) ANALYST,
sum(decode(e.job, ‘MANAGER’, e.sal, 0)) MANAGER,
sum(decode(e.job, ‘PRESIDENT’, e.sal, 0)) PRESIDENT
from emp e
join dept d on e.deptno = d.deptno
group by d.dname
union
select ‘总计’ dname,
sum(decode(e.job, ‘CLERK’, e.sal, 0)) CLERK,
sum(decode(e.job, ‘SALESMAN’, e.sal, 0)) SALESMAN,
sum(decode(e.job, ‘ANALYST’, e.sal, 0)) ANALYST,
sum(decode(e.job, ‘MANAGER’, e.sal, 0)) MANAGER,
sum(decode(e.job, ‘PRESIDENT’, e.sal, 0)) PRESIDENT
from emp e
join dept d2 on e.deptno = d2.deptno
SQL(横表和纵表)行列转换,PIVOT与UNPIVOT的区别和使用方法举例,合并列的例子
牵手的承诺1 2016-10-13 原文
使用过SQL Server 2000的人都知道,要想实现行列转换,必须综合利用聚合函数和动态SQL,具体实现起来需要一定的技巧,而在SQL Server 2005中,使用新引进的关键字PIVOT/UNPIVOT,则可以很容易的实现行列转换的需求。
在本文中我们将通过两个简单的例子详细讲解PIVOT和UNPIVOT的用法。
PIVOT是行转列,用法如下:
假如表结构如下:
id name quarter profile
1 a 1 1000
1 a 2 2000
1 a 3 4000
1 a 4 5000
2 b 1 3000
2 b 2 3500
2 b 3 4200
2 b 4 5500
使用PIVOT将四个季度的利润转换成横向显示:
select id,name,
[1] as "一季度",[2] as "二季度",[3] as "三季度",[4] as "四季度"
from test
pivot
(
sum(profile)
for quarter in ([1],[2],[3],[4])
)
as pvt
得出的结果如下:
id name 一季度 二季度 三季度 四季度
1 a 1000 2000 4000 5000
2 b 3000 3500 4200 5500
========================================================================================
UNPIVOT是列转行,用法如下:
假如表结构如下:
id name Q1 Q2 Q3 Q4
1 a 1000 2000 4000 5000
2 b 3000 3500 4200 5500
使用UNPIVOT,将同一行中四个季度的列数据转换成四行数据:
select id,name,quarter,profile
from test
unpivot
(
profile
for quarter in ([Q1],[Q2],[Q3],[Q4])
)
as unpvt
得出的结果如下:
id name quarter profile
1 a Q1 1000
1 a Q2 2000
1 a Q3 4000
1 a Q4 5000
2 b Q1 3000
2 b Q2 3500
2 b Q3 4200
2 b Q4 5500
ORACLE纵向表转换为横向表写法
设存在如下纵向表,第一列为id(可能是某个业务数据的id),第二列为类型,第三列为类型对应的值,如下图:
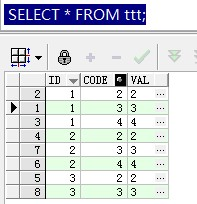
如上表,存在2,3,4三种类型,其中业务数据ID为1的三种类型都有值,业务数据ID为2的三种类型都有值,业务数据ID为3的只有类型2和3有值,现在要把纵向表横过来显示,可以采用如下代码:
1.-- =========================================================
2.-- 纵向表变横向表:
3.-- 1. 转换类型,类型的值必须是整数,且不等于0,即0没有意义,0可以表示为空
4.-- =========================================================
5.SELECT
6.t.id,
7.SUM(DECODE(t.code, 2, 2, 0)) “第二项”, – 如果该行类型为2则就是2,其它的都为0
8.SUM(DECODE(t.code, 3, 3, 0)) “第三项”,
9.SUM(decode(t.code, 4, 4, 0)) “第四项”
10.FROM ttt t WHERE t.id=1 GROUP BY t.id;
11.-- =========================================================
12.-- 纵向表变横向表:
13.-- 1. 转换类型对应的数据,且数据需要是数值,且0没有意义,即0可以表示为空
14.-- =========================================================
15.SELECT
16.t.id,
17.SUM(DECODE(t.code, 2, t.val, 0)) “第二项”, – 如果该行类型为2则显示2类型对应的值DECODE,否则都显示0
18.SUM(DECODE(t.code, 3, t.val, 0)) “第三项”,
19.SUM(DECODE(t.code, 4, t.val, 0)) “第四项”
20.FROM ttt t GROUP BY t.id;
oracle合并列的函数wm_concat的使用详解
oracle wm_concat(column)函数使我们经常会使用到的,下面就教您如何使用oracle wm_concat(column)函数实现字段合并,如果您对oracle wm_concat(column)函数使用方面感兴趣的话,不妨一看。
shopping:
u_id goods num
1 苹果 2
2 梨子 5
1 西瓜 4
3 葡萄 1
3 香蕉 1
1 橘子 3
想要的结果为:
u_id goods_sum
1 苹果,西瓜,橘子
2 梨子
3 葡萄,香蕉
1.select u_id, wmsys.wm_concat(goods) goods_sum 2. 3.from shopping 4. 5.group by u_id
想要的结果2:
u_id goods_sum
1 苹果(2斤),西瓜(4斤),橘子(3斤)
2 梨子(5斤)
3 葡萄(1斤),香蕉(1斤)
使用oracle wm_concat(column)函数实现:
select u_id, wmsys.wm_concat(goods || ‘(’ || num || ‘斤)’ ) goods_sum
from shopping
group by u_id
mysql—group_concat