在爬虫的过程中,很容易就遇到需要爬取的信息是 javascript 加载的,而 requests 抓取下来的网页是没有经过 javascript 渲染的。上文提到的 selenium 功能很强大,对于需要用 javascript 加载的网页有非常好的效果,所以本文将介绍 selenium 的一些用法。
增加头部
在 python 中可以用 selenium 模拟成一台手机访问网页,利用 options = webdriver.ChromeOptions() 对浏览器进行设置,设置为中文 options.add_argument('lang=zh_CN.UTF-8'),增加一个手机的头部:
options.add_argument('user-agent="Mozilla/5.0 (iPod; U; CPU iPhone OS 2_1 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5F137 Safari/525.20"')
此时打开 url = http://image.baidu.com/ 出现的网页为:
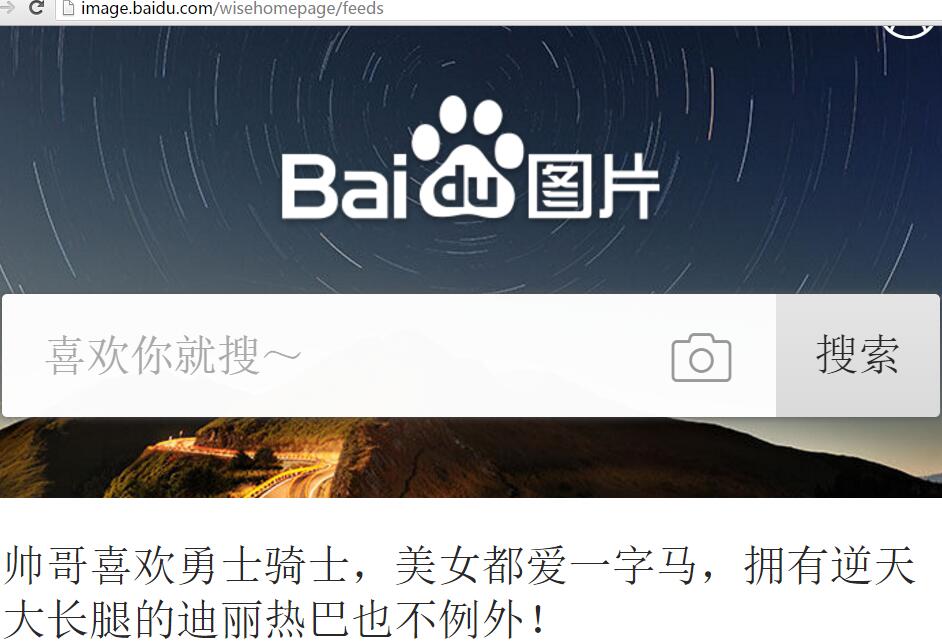
打开的网页和 PC 端的不一样了,因为设置了手机的头部,所以此时打开的是手机的网页。
无图模式
有时候加载图片使打开网页非常慢,添加如下代码,在 Chrome 中可以实现无图模式:
'''
遇到python不懂的问题,可以加Python学习交流群:1004391443一起学习交流,群文件还有零基础入门的学习资料
'''prefs = {
'profile.default_content_setting_values': {
'images': 2
}
}
options.add_experimental_option('prefs', prefs)
屏幕大小
在默认打开的浏览器中,浏览器的大小是默认适应屏幕的,如果想要全屏的话,加入设置 browser.maximize_window() 即可,但是需要自己控制浏览器大小,则控制的代码为:
# 1200*800分辨率
browser.set_window_size(1200,800)
打开新窗口
selenium 能通过 js 打开新的窗口:
newwindow = "window.open('https://www.baidu.com');"
# 通过js新打开一个窗口
browser.execute_script(newwindow)
但是在获取新窗口的 html 的时候,发现还是获取到了 image 的 html ,因为 selenium 还是默认在原来的句柄,只要将句柄切换到最新的窗口即可:
# 捕获所有的句柄
handles = browser.window_handles
# 窗口切换,切换为新打开的窗口
browser.switch_to_window(handles[-1])
# 切换回最初打开的窗口
browser.switch_to_window(handles[0])
携带cookie
selenium 也能实现携带 cookie 访问网页:
url = "https://www.baidu.com/"
browser.get(url)
# 通过js新打开一个窗口
newwindow='window.open("https://www.baidu.com");'
# 删除原来的cookie
browser.delete_all_cookies()
# 携带cookie打开
browser.add_cookie({'name':'ABC','value':'DEF'})
# 通过js新打开一个窗口
browser.execute_script(newwindow)
得到的结果为:
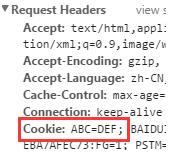
设置加载时间
有时候网络不太好的时候,或者网页出现一直在加载的情况的时候,selenium 会一直在等待网页加载完成,从而不能进行下一步操作。这里可以设置 selenium 对网页的加载时间,而且还能直接停止其加载:
# 设置最长加载时间为90秒
browser.set_page_load_timeout(90)
try:
# 输入网址
browser.get(url)
except:
# 超过90秒强制停止加载
browser.execute_script('window.stop()')
截图
selenium 能截取当前屏幕:
browser.save_screenshot("E:/img.png")
控制下拉框
像百度图片这样的网站是属于 异步加载 ,只有下拉到一定地步才会加载下面的内容,这时候能用 selenium 无限下拉直至底部:
url = "https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111111&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=21&oq=21&rsp=-1"
# 设置最长加载时间为90秒
browser.set_page_load_timeout(90)
try:
# 输入网址
browser.get(url)
time.sleep(10)
except:
# 超过90秒强制停止加载
browser.execute_script('window.stop()')
# 翻页到最后面
browser.execute_script("""
(function () {
var y = 0;
var step = 100;
window.scroll(0, 0);
function f() {
if (y < document.body.scrollHeight) {
y += step;
window.scroll(0, y);
setTimeout(f, 100);
} else {
window.scroll(0, 0);
document.title += "scroll-done";
}
}
setTimeout(f, 1000);
})();
""")
print("下拉中...")
# time.sleep(180)
while True:
if "scroll-done" in browser.title:
break
else:
print("还没有拉到最底端...")
time.sleep(10)
控制键盘
selenium 也能控制键盘,在前面我们进行百度搜索的时候,是用浏览器模拟点击了 百度一下 ,如果要用回车来实现点击 百度一下 呢:
# 填写TTyb
browser.find_element_by_id("kw").send_keys("TTyb")
# 填写完后按回车键
browser.find_element_by_id("kw").send_keys(Keys.ENTER)