较上次内容增加的内容: 自动登陆抽屉网,自动点赞,自动换页
1.自动登陆网站
登陆时故意在浏览器输错出现login,查看内容,获取form data
2.cookies的使用
本次爬取的网站采用了cookies授权机制,得先访问总网站,分配到未授权的cookies,登陆后带着cookies去授权
代码:
import requests from bs4 import BeautifulSoup #1.先访问抽屉,获取cookie(未授权),点赞前肯定会访问此网站 r1 = requests.get( url='https://dig.chouti.com/all/hot/recent/1', headers={ 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36' } ) r1_cookie_dict=r1.cookies.get_dict() #2.发送用户名和密码认为认证 + cookie(未授权) response_login = requests.post( url='https://dig.chouti.com/login', data={ 'phone':'8613026354610', 'password':'halou445513', 'oneMonth':'1' }, headers={ 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36' }, cookies=r1_cookie_dict ) # 1.获取点赞id for page_num in range(1,3): response_index = requests.get( url='https://dig.chouti.com/all/hot/recent/%s'%page_num, headers={ 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36' } ) # print(response_index.text) soup = BeautifulSoup(response_index.text,"html.parser") div = soup.find(attrs={'id':'content-list'}) items = div.find_all(attrs={'class':'item'}) for item in items: tag = item.find(attrs={'class':'part2'}) if not tag: continue nid = tag.get('share-linkid') print(nid) #点赞 r1 = requests.post( url='https://dig.chouti.com/link/vote?linksId=%s'%nid, headers={ 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36' }, cookies = r1_cookie_dict ) print(r1.text)
其他知识点:
1.requests常用参数:
url,params,headers,cookies:

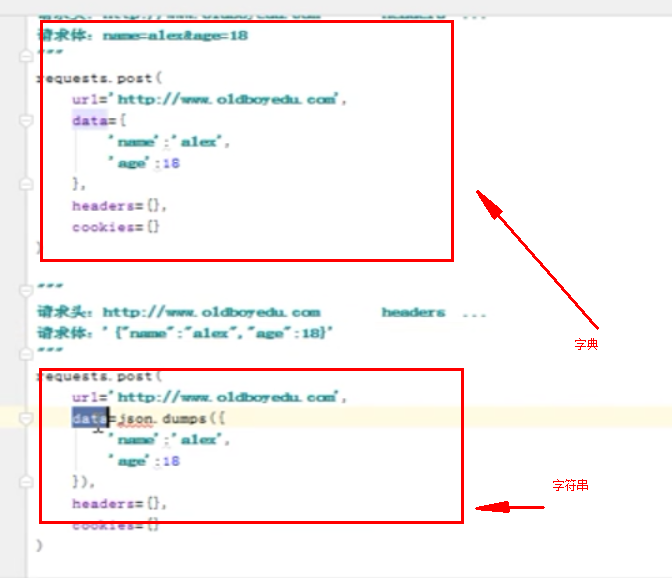
data,json:data传的是字典,json传的是字符串

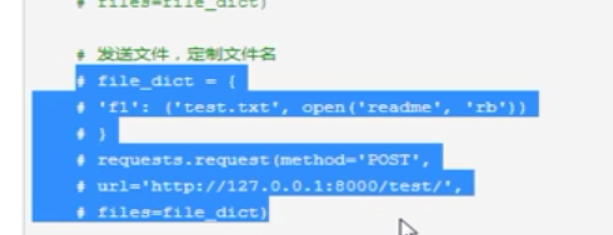
files:上传文件(stream分段上传,此处不列出)
auth:浏览器内置弹窗的数据


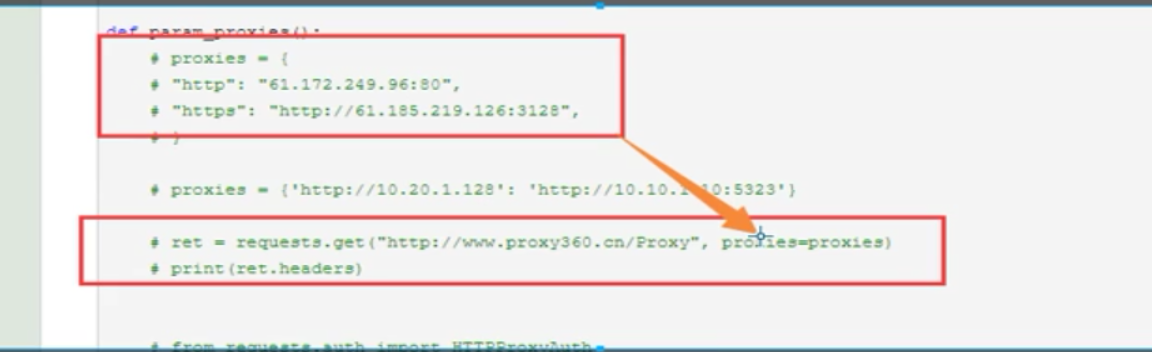
proxies:代理
cert,verify:与证书相关,比较少见
1.验证码问题(与人工智能相关):
- pil模块可以搞定简单的模块,简单的70-80%通过率,
- 买第三方服务