什么是iframe?
<iframe> 标签是一个内联框架,即用来在当前 HTML 页面中嵌入另一个文档的,且所有主流浏览器都支持iframe标签。
简单说,就是在一个页面内,又嵌入了一个页面,看似是一个页面,但是在selenium中,无法对iframe内元素进行直接定位
示例:
打印出网易云音乐-云音乐热歌榜中前10首歌曲名
我们先定位出排行榜中前10首歌曲的元素
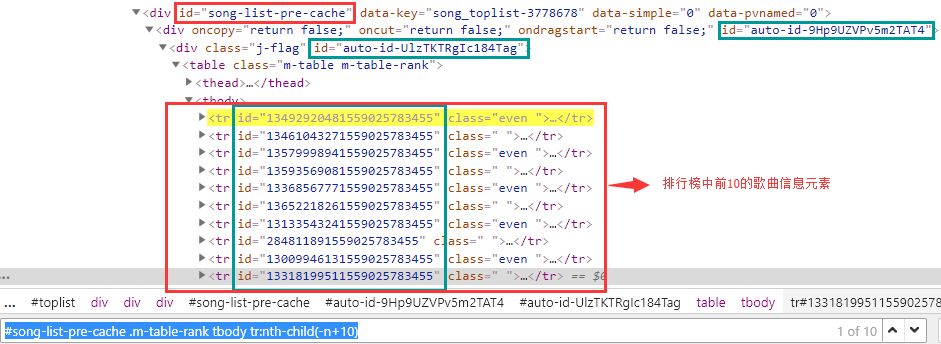
简单说一下,为什么使用红色框内的 id 信息
-
定位元素,一般我们会直接先定位到某一首歌曲信息,此时我们发现该歌曲的 id 属性值为一长串数字,此时我们有必要怀疑,该数值是随机生成的
-
验证:复制该元素的 id 属性值,刷新界面,重新查看该元素的 id 属性值,是否与刚刚复制下来的内容一致,如不一致,则验证了第 1 条的假设
-
验证第 1 条之后,此时我们需要做的就是往上层找,看看是否存在我们能直接定位到元素的属性值
-
父元素的 class 属性值,可以直接准确定位,则该元素可用
-
再往上找,蓝色框内的 id 属性值可以看出,均存在乱序内容,我们第一反应就应该为 该属性值 不可用
-
再往上找到 id = song-list-pre-cache 的属性值,可以看出是有序的,可直接定位
-
此时,第 4 条与第 6 条均可实现精准定位,作者这里是习惯性的使用了 id 属性
查找到元素后,我们直接撸代码,打印出歌曲信息即可
from selenium import webdriver driver = webdriver.Chrome() driver.implicitly_wait(10) # 抓取排行榜信息 driver.get('https://music.163.com/#/discover/toplist?id=3778678') div = driver.find_elements_by_css_selector('#song-list-pre-cache .m-table-rank tbody tr:nth-child(-n+10) b') # 使用for循环,获取到每首歌曲的元素,并打印出该元素的 text 属性值 for one in div: print(one.get_attribute('title')) driver.quit()
输出结果:
# 在漫长的隐式等待(10s)中,输出结果为空,并没有报错,这是为什么呢?
知识点
-
find_elements :注意 s ,复数;返回的为列表形式,如果为查找到元素,则返回空列表,无报错信息
-
find_element : 定位某一元素,如果指定的时间内,未找到该元素,则会抛出错误
修改一下我们的代码:
from selenium import webdriver driver = webdriver.Chrome() driver.implicitly_wait(10) # 抓取排行榜信息 driver.get('https://music.163.com/#/discover/toplist?id=3778678') songList = driver.find_element_by_id('song-list-pre-cache') div = songList.find_elements_by_css_selector('.m-table-rank tbody tr:nth-child(-n+10) b') # 使用for循环,获取到每首歌曲的元素,并打印出该元素的 text 属性值 for one in div: print(one.get_attribute('title'))
driver.quit()
看一看我们的输出结果:

阿西吧,果然报错了,错在第8行:songList = driver.find_element_by_id('song-list-pre-cache');但是我们明明可以在浏览器中定位到该元素啊?
定位iframe
定位没有问题,那么我们就需要考虑是不是 iframe 在搞鬼!
重新查看一下我们的元素信息

从红色的框框内,我们看到了 id="song-list-pre-cache" 的 父元素 和 子元素,我们往前找,蓝色框内,存在了一个 #g_iframe 的父元素
点击蓝色区域,让我们看一下 iframe

我们可以确定了,排行榜的歌曲信息,是写在一个 iframe 框架内,那我们该如何操作 iframe 中的元素呢?
切换iframe
-
通过 id 切换,且 id 唯一
-
-
driver.switch_to.frame('g_iframe')
-
-
通过 name 切换,且 name 唯一
-
driver.switch_to.frame('contentFrame')
-
-
若无 id 和 name ,则需要先定位到 iframe ,然后再切换
-
iframe = driver.find_elements_by_tag_name('iframe')[0] -
driver.switch_to.frame(iframe)
-
切回主文档
我们切入到 iframe 框架内进行操作后,需要再次回到主文档区域进行操作,就必须要切回主文档
-
driver.switch_to_default_content()
多嵌套iframe
既然主文档可以嵌套 iframe ,那么 iframe 同样可以嵌套 iframe ,那么存在这种多重嵌套我们要怎么处理呢?
<html> <iframe id="frame1"> <iframe id="frame2" / > </iframe> </html>
如果我们需要操作 iframe2 中的元素,我们需要切换 2 次
- 先从主文档切换至 iframe1
-
driver.switch_to.frame('iframe1')
-
- 再从 iframe1 切换至 iframe2
-
driver.switch_to.frame('iframe2')
-
我们切到 iframe2 中操作完之后,需要回到 iframe1 中进行操作,selenium 提供了一个更好的方式,避免了从 iframe2 切到主文档 再切到 iframe1 的复杂
-
从 iframe2 切回至 iframe1
-
driver.switch_to.parent_frame()
-
让我们来完成之前的需求:
from selenium import webdriver driver = webdriver.Chrome() driver.implicitly_wait(10) # 抓取排行榜信息 driver.get('https://music.163.com/#/discover/toplist?id=3778678') # 定位到 iframe 的元素 iframe = driver.find_elements_by_tag_name('iframe')[0] # 切到 iframe 框架内 driver.switch_to.frame(iframe) songList = driver.find_element_by_id('song-list-pre-cache') div = songList.find_elements_by_css_selector('.m-table-rank tbody tr:nth-child(-n+10) b') # 使用for循环,获取到每首歌曲的元素,并打印出该元素的 text 属性值 for one in div: print(one.get_attribute('title')) # 切到 iframe 的上一层,即为主文档 driver.switch_to.parent_frame() # 打印主文档的一段内容 meta = driver.find_element_by_css_selector('meta[name="description"]') print('\n'+meta.get_attribute('content')) driver.quit()
输出结果如下:
心如止水
多想在平庸的生活拥抱你
归去来兮
晚安
我曾
四块五
出山
Monsters
那个女孩
像鱼
网易云音乐是一款专注于发现与分享的音乐产品,依托专业音乐人、DJ、好友推荐及社交功能,为用户打造全新的音乐生活。
参考文档:
selenium切换到iframe:https://www.cnblogs.com/xiaoxiaolvdou/p/9316805.html