索引
稀疏存储,每隔一定字节的数据建立一条索引(这样的目的是为了减少索引文件的大小)。
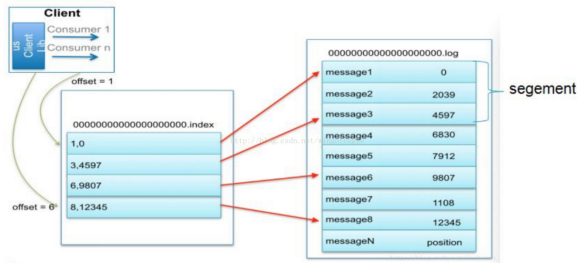
下图为一个partition的索引示意图:
注:
- 现在对6.和8建立了索引,如果要查找7,则会先查找到8然后,再找到8后的一个索引6,然后两个索引之间做二分法,找到7的位置2
- 每一个log文件中又分为多个segment
通过调用kafka自带的工具,可以看到日志下的数据信息
> bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /root/kafka/kafka-logs/streams-plaintext-input-0/00000000000000000000.log --print-data-log --verify-index-only
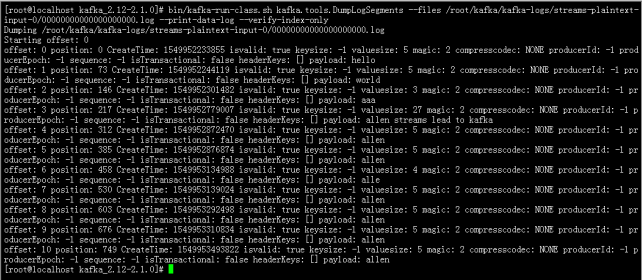
kafka日志分为index与log,两个成对出现;index文件存储元数据(用来描述数据的数据,这也可能是为什么index文件这么大的原因了),log存储消息。索引文件元数据指向对应log文件中message的迁移地址;例如2,128指log文件的第2条数据,偏移地址为128;而物理地址(在index文件中指定)+ 偏移地址可以定位到消息。
因为每条消息都被append到该partition中,是顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)。
