1. 上下文无关文法及分析
上下文无关文法的规则是递归的。
识别这些结构的算法使用递归调用或显示管理的分析栈。经常使用的基本结构是一类树(分析树或语法树)。
算法大致可分为两种:自顶向下和由底向上
1.1 分析过程
分析函数将扫描程序生成的记号序列作为输入,并生成语法树作为输出:

- 编译器中更多是多遍,后面的遍将语法树作为他们的输入。
- 语法树的结构很大程度依赖语言特定的语法结构。
- 错位处理,恢复继续分析。
1.2 上下文无关文法
同正则表达式类似,文法规则是定义在一个字母表或符号集之上。
1.2.1 上下文无关文法规则
文法规则:
exp → exp op exp | (exp) | number op → + | - | *
第1个规则定义了一个表达式结构(用名字e x p)由带有一个算符和另一个表达式的表达式,或一个位于括号之中的表达式,或一个数组成。第2个规则定义一个算符(利用名字o p)由符号+、-或*构成。
还有其他各种变形形式:
1.
![]()
2.

3.
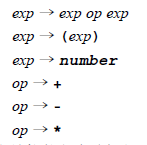
4.
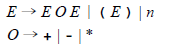
1.2.2 推导及由文法定义的语言
文法规则通过推导确定记号符号的正规串。推导 是在文法规则的右边进行选择的一个结构名字替换序列。推导以一个结构名字开始并以记号符号串结束。在推导的每一个步骤中,使用来自文法规则的选择每一次生成一个替换。
例:由文法规则进行推导


推导的结果集合记为:
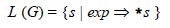
其中G代表表达式文法,s 代表记号符号的任意数组串(有时称为句子 ),而符号Þ*表示由如前所述的替换序列组成的推导(星号用作指示步骤的序列,这与在正则表达式中指示重复很相像)。由于它们通过推导“产生” L (G)中的串,文法规则因此有时也称作产生式 。
终结符,通俗的说就是不能单独出现在推导式左边的符号,也就是说终结符不能再进行推导。
不是终结符的都是非终结符。非终结符可理解为一个可拆分元素,而终结符是不可拆分的最
小元素。如:有α → β ,则α 必然是个非终结符。一般书上把非终结符用大写字母表示,而
终结符用小写字母表示。识别符号就是开始符。由文法产生语言句子的基本思想是:从识别符
号开始,把当前产生的符号串中的非终结符号替换为相应规则右部的符号串,直到最终全由终
结符号组成。这种替换过程称为推导或产生句子的过程,每一步成为直接推导或直接产生。 例如: 有文法G2[S]为: S->Ap S->Bq A->a A->cA B->b B->dB 则表示:S 为开始符,S,A,B 为非终结符,而p,q,a,b,c,d 为终结符
1.3 分析树与抽象语法树
1.3.1 分析树
与推导相对应的分析树是一个作了标记的树,其内部的结点由非终结符标出,树叶节点由终结符标出,每个子节点都表示推导的一个步骤中的相关非终结符的替换。
例:
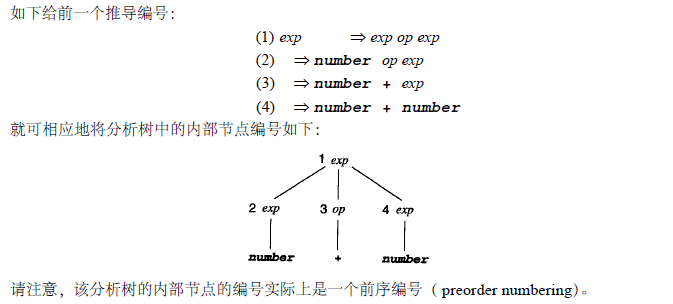
一般而言,分析树可与许多推导相对应。
最左推导
是指它的每一步中最左的非终结符都要被替换的推导。与其相关的分析树的内部节点的前序编号相对应。
最右推导
则是指它的每一步中最右的非终结符都要被替换的推导。最右推导则和后序编号相对应。
1.3.2 抽象语法树
分析树包含了比纯粹生成可执行代码所需更多的信息。抽象语法树去除了得到记号序列的分析过程,但包含了转换所需的所有信息,是真正的源代码记号序列的抽象表示。
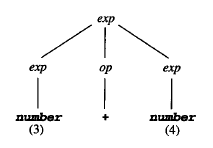
分析树
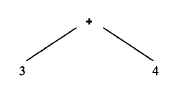
抽象语法树