1. abs()、all()函数
print(abs(-1))#abs 取绝对值 print(all([1,2,3,'1'])) #判断是否为真 print(all([1,2,3,''])) print(all(''))#如果可迭代的"列表"为空,则返回True

2.any() 只要有一个为真,则这个迭代对象为真
print(any([0,''])) print(any([0,'',1]))
3.bin() 转换为 二进制数
print(bin(13))#结果:0b1101 其中0b表示二进制

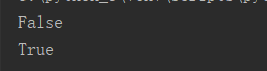
4.bool() 为False的有: 空,None,0 其余都为 True
print(bool('')) print(bool(None)) print(bool(0))

5.bytes 函数返回一个新的 bytes 对象,该对象是一个 0 <= x < 256 区间内的整数不可变序列。它是 bytearray 的不可变版本。
语法
以下是 bytes 的语法:
class bytes([source[, encoding[, errors]]])
参数
- 如果 source 为整数,则返回一个长度为 source 的初始化数组;
- 如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
- 如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
- 如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
- 如果没有输入任何参数,默认就是初始化数组为0个元素。
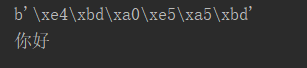
name = '你好' print(bytes(name,encoding='utf-8')) print(bytes(name,encoding='utf-8').decode(encoding='utf-8')) #用什么编码 一定就要用什么解码
6.divmod() 函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。
print(divmod(10,3)) #用来做分页功能 结果:(3, 1) 表示分3页,最后剩下的还要加1页, 运算是:10 除以 3 ,第一个结果取 商 第二个结果取 余数 print(divmod(10,2))#结果:(5, 0) 表示分5页即可

7.express()函数 1.把字符串中的表达式进行运算2.把字符串中的数据结构提取出来
express = '1+2*(3/3-1)-2' #结果为-1.0 print(eval(express)) #1.把字符串中的表达式进行运算2.把字符串中的数据结构提取出来

8.(1)max方法比较的方式是 先从第一个元素按位置进行比较,这样就会从数字开始比较,从而得到正确的年龄和用户姓名的值
(2)max()内置函数不同类型之间不能进行比较
# max() 取最大值 min()取最小值 l =[1,3,100,-1,2] print(max(l)) print(min(l))

(4)默认比较的是 字典的key
age_dic = {'1号_age':10,'2号_age':58,'3号_age':90}
print('====>',max(zip(age_dic.values(),age_dic.keys()))) #先利用拉链zip()方法将可迭代对象转换成(values,keys)的元组形式,
#然后再利用max()方法进行比较,max方法比较的方式是 先从第一个元素按位置进行比较,这样就会从数字开始比较,从而得到正确的年龄和用户姓名的值
#max()内置函数不同类型之间不能进行比较
#默认比较的是 字典的key
print(max(age_dic)) #执行结果:3号_age

(5)比较复杂一点的数据进行比较
people =[ { 'name':'alex','age':1000}, {'name':'peiqi','age':10000}, {'name':'yuanhao','age':9000}, {'name':'linhaifeng','age':18} ] print(max(people,key=lambda dic:dic['age'])) #分解该过程如下: ret=[] for item in people: ret.append(item['age']) print(ret) print(max(ret))

9.zip()内置函数
print(list(zip(('a','b','c'),(1,2,3)))) print(list(zip(('a','b','c'),(1,2,3,4)))) print(list(zip(('a','b','c','d'),(1,2,3)))) p = {'name':'alex','age':18,'gender':'none'}#字典 print(list(zip(p.keys(),p.values())))

10.chr()函数 功能:获取数字在ASCII 码中的字符串值 chr() 用一个整数作参数,返回一个对应的字符。ord()函数与chr()函数相反;ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。
#chr()函数 功能:获取数字在ASCII 码中的字符串值 chr() 用一个整数作参数,返回一个对应的字符。 print(chr(100)) #ord()函数与chr()函数相反;ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数, # 返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。 print(ord('d'))

11.pow()函数 方法返回 xy(x的y次方) 的值。
print(pow(3,3))#3**3 3的三次方 print(pow(3,3,2))##3**3%2 ,3的三次方 之后除以2 取余数

12.reversed() 元素反转
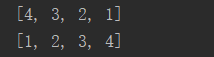
#reversed() 元素反转 l = [1,2,3,4] print(list(reversed(l))) print(l)
13.set()函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等
#round() 四舍五入
#round() 四舍五入 print(round(5.5)) #set()函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等 x = set('runoob') y = set('google') print(x&y) #交集 print(x|y)#并集 print(x-y)#差集 print(y-x)#差集 print(x,y)#原始去重功能
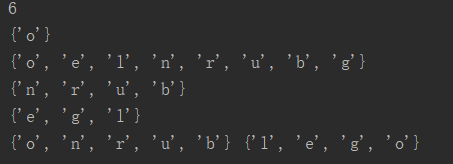
14.sorted() 功能:从小到大排序
#sorted() 功能:从小到大排序 l = [3,4,1,2,5,8,4] l1 = [3,4,1,2,5,8,'s',4] #排序本质就是在比较大小,不同类型之间不可以比较大小 print(sorted(l)) # print(sorted(l1))#报错 # sorted() 按照年龄进行从小到大排序 people =[ { 'name':'alex','age':1000}, {'name':'peiqi','age':10000}, {'name':'yuanhao','age':9000}, {'name':'linhaifeng','age':18} ] print(sorted(people,key=lambda dic:dic['age']))

15.str() 转换成字符串
# str() 转换成字符串 print(str('1')) print(type(str({'a':1}))) #转换为字符串类型,并打印类型 dic_str = str({'a': 1}) print(type(eval(dic_str)))#字符串最终转换为字典并打印类型
16.type()函数,判断数据类型
msg = '123' if type(msg) is str: msg = int(msg) res =msg +1 print(res)

17._import_()当导入的包名格式为字符串时使用它来导入
import test #--->导入包名,但是无法导入格式为字符串格式的包名这时候需要用_import_() test.say_hi() #如果需要导入的包名是字符串格式,则需要使用_import_() module_name = 'test' m = __import__(module_name) m.say_hi()
