1,前面两篇博文实现了邻接矩阵和邻接链表法实现图的数据结构,什么情况下选择合适的图的类型?从时间复杂度角度来对比下;
2,时间复杂度的对比分析:
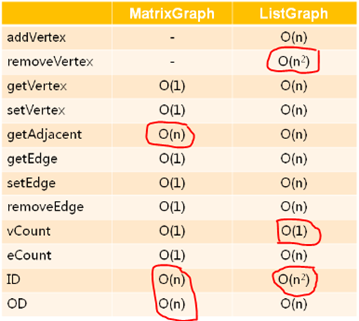
1,邻接矩阵法操作性能更好、效率更高,更在意性能,则选择邻接矩阵法;
2,链表矩阵法在空间使用率上更好,当环境资源紧张、内存比较小,选择邻接链表法;
3,小结论:
1,MatrixGraph 适用于内存资源富足的场合(性能较好);
2,ListGraph 适用于内存资源受限的场合(节省空间);
4,图的遍历:
1,从图中的某一个顶点出发,沿着一些边访问图中的其它顶点,使得每个顶点最多被访问一次;
2,注意:从某个顶点出发进行遍历,不一定能够访问到图中的所有顶点;
1,当始发顶点没有任何邻接顶点时;
5,图的遍历方式:
1,广度优先(Breadth First Search):
1,以二叉树层次遍历的思想对图进行遍历;
2,深度优先(Depth First Search):
1,以二叉树先序遍历的思想对图进行遍历;
6,广度优先(BFS):
1,树的广度优先算法需要原材料:队列;
7,广度优先算法:
1,原料:class LinkQueue<T>;
2,步骤:
1,将起始顶点压入队列中;
2,队头顶点 V 弹出,判断是否已经标记(标记:转 2,未标记:转 3);
1,每个顶点只能访问一次,如果发现队头顶点已经打上标记,则已经访问过了,直接扔掉;
3,标记顶点,并将顶点 V 的邻接顶点压入队列中;
1,没有访问过的顶点的操作;
4,判断队列是否为空(非空:转 2,空:结束);
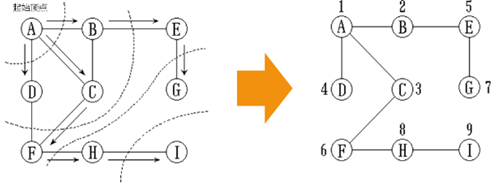
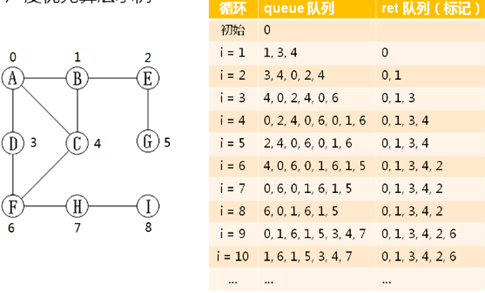
8,广度优先算法示例:
9,广度优先算法流程图:
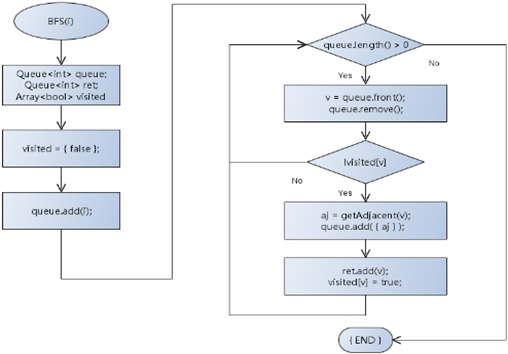
1,比树多了个标记数组,因为树结点的孩子不可能是此结点的父亲或祖先,但是图却可以是,所以要标记数组;
10,广度优先算法实现:
1 /* 广度优先算法,参数 i 为起始的顶点编号,图中的这个编号才具有唯一辨识性;以层次的方式对定点进行访问 ; 广度优先和深度优先唯一不同在于栈或队列的使用,使用队列存储邻接顶点则为广度优先,使用栈存储邻接顶点则为深度优先 ; 为了保持接口的一致性,仿照树里面层次遍历的操作设置函数接口 */ 2 SharedPointer< Array<int> > BFS(int i) 3 { 4 DynamicArray<int>* ret = NULL; // 存储返回的顶点编号,要反应访问顶点编号的先后次序 5 6 if( (0 <= i) && (i < vCount()) ) 7 { 8 LinkQueue<int> q; // 存放图的将要可能被遍历结点 9 LinkQueue<int> r; // 存放图的遍历后的结点 10 DynamicArray<bool> visited(vCount()); //存储是否顶点是否被遍历的标记 11 12 /* 初始的标记数组值设置 */ 13 for(int i=0; i<visited.length(); i++) 14 { 15 visited[i] = false; 16 } 17 18 q.add(i); // 向将要被可能访问结点的队列中加入元素 19 20 /* 遍历循环开始 */ 21 while( q.length() > 0 ) 22 { 23 int v = q.front(); // 得到队列头部的顶点值 24 q.remove(); // 拿出这个顶点 25 26 if( !visited[v] ) // 判断是否被遍历过 27 { 28 SharedPointer< Array<int> > aj = getAdgacent(v); // 拿到 v 顶点的邻接顶点并放到数组中 29 30 /* 将邻接顶点放到队列中 */ 31 for(int j=0; j<aj->length(); j++) 32 { 33 q.add((*aj)[j]); // 将邻接顶点放到队列中 34 } 35 36 r.add(v); // 将顶点放到访问队列中去 37 38 visited[v] = true; // 将访问标记设为访问 39 } 40 } 41 42 ret = toArray(r); // 将队列转换为数组 43 } 44 else 45 { 46 THROW_EXCEPTION(InvalidParameterException, "Index i is invalid ..."); 47 } 48 49 return ret; 50 }
11,广度优先算法实现的测试代码:
1 #include <iostream> 2 #include "MatrixGraph.h" 3 4 using namespace std; 5 using namespace DTLib; 6 7 int main() 8 { 9 MatrixGraph<9, char, int> g; 10 const char* VD = "ABEDCGFHI"; 11 12 for(int i=0; i<9; i++) 13 { 14 g.setVertex(i, VD[i]); // 设置顶点相关的值为字符串 VD 中的内容 15 } 16 17 g.setEdge(0, 1, 0); // 无向图、特殊的有向图,所以每个点之间的邻接矩阵对称, 这里权值为 0,只关心是否连接,不关心权值 18 g.setEdge(1, 0, 0); 19 g.setEdge(0, 3, 0); 20 g.setEdge(3, 0, 0); 21 g.setEdge(0, 4, 0); 22 g.setEdge(4, 0, 0); 23 g.setEdge(1, 2, 0); 24 g.setEdge(2, 1, 0); 25 g.setEdge(1, 4, 0); 26 g.setEdge(4, 1, 0); 27 g.setEdge(2, 5, 0); 28 g.setEdge(5, 2, 0); 29 g.setEdge(3, 6, 0); 30 g.setEdge(6, 3, 0); 31 g.setEdge(4, 6, 0); 32 g.setEdge(6, 4, 0); 33 g.setEdge(6, 7, 0); 34 g.setEdge(7, 6, 0); 35 g.setEdge(7, 8, 0); 36 g.setEdge(8, 7, 0); 37 38 SharedPointer< Array<int> > sa = g.BFS(0); 39 40 for(int i=0; i<sa->length(); i++) 41 { 42 cout << (*sa)[i] << " "; 43 } 44 45 return 0; 46 }
12,标号是图中唯一可以表示顶点的标志,要利用好;
13,父类中实现其他时,可以调用子类中对纯虚函数的实现,因为当子类创建对象后,父类中的所有函数都被继承到了子类当中;
14,小结:
1,MatrixGraph 适用于资源富足的场合;
2,ListGraph 适用于资源受限的场合;
1,时间复杂度高;
3,广度优先按照“层次的方式”对定点进行访问;
1,同树的层次遍历;
4,广度优先算法的核心是队列的使用;
1,邻接顶点的队列压入;