上一篇回顾:
1.数据页由七部分组成,包括File Header(描述页的信息)、Page Header(描述数据的信息)、Infimum + Supremum(页中的虚拟数据最大值和最小值)、User Records(用户真实数据储存的部分)、Free Space(真实数据增加划分的部分空间)、Page Directory(页中记录相对位置,槽储存的位置)、File Trailer(检验16kb大小的数据页是否完整)。
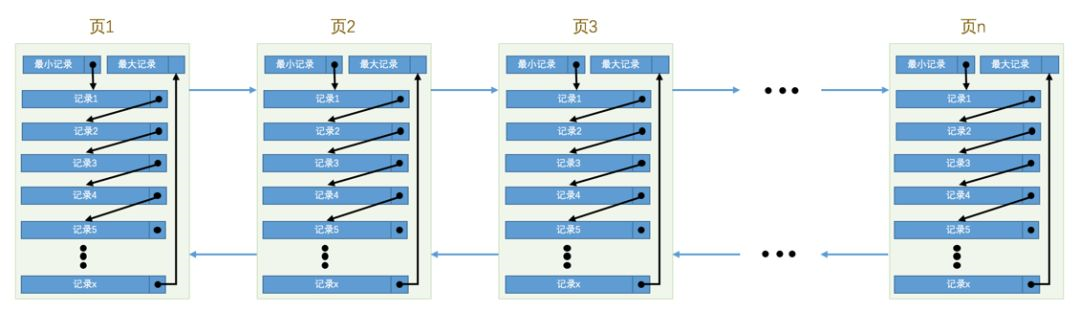
2.每一个页中的数据都是单向链表,由数据的记录头信息next_record进行维护,记录的是相对于本数据下一条数据的距离字节数。内存中的页是双向链表的数据结构,由页信息的本页号码,上一页号码,下一页号码进行维护。
3.页中的数据都会进行分组,虚拟最小数据是一组,最大数据组最多存在8条数据,满额是二分成普通分组数据。每个分组的最后一条数据相对于页的偏移量就是槽的数据。本页中数据的查找采用的就是二分法,通过槽确定数据所在的分组,然后在进行搜索。
没有索引的查找:
在一个页中:
如果数据在一个页中,采用的是以主键为条件,那么我们就可以采用二分法的方式进行寻找,我们通过上一篇文章可以知道的是每一个页中的数据都会进行分组,然后在页信息的Page Diractory部分进行储存槽的信息,通过槽定位到数据所在的分组,然后在开始进行数据的搜索。
如果我们采用的不是主键作为搜索的条件,那么我们通过二分法寻找的方法必然是行不通的了,这时候我们只能很苦逼的一条一条数据慢慢的检索。
在很多数据页中:
如果我们要在很多数据页中进行没有索引的数据寻找那就更是不幸运了,只有一条数据的挨着进行搜索,假如我们数据库里有上亿的数据那么就是很苦逼而且不现实的一种方式。
索引的实现:
1:首先我们先创建一个今天需要使用到的表格:

2:我们进行数据的插入:

3:我们用简化的图示展示一下这些数据储存的状态信息:
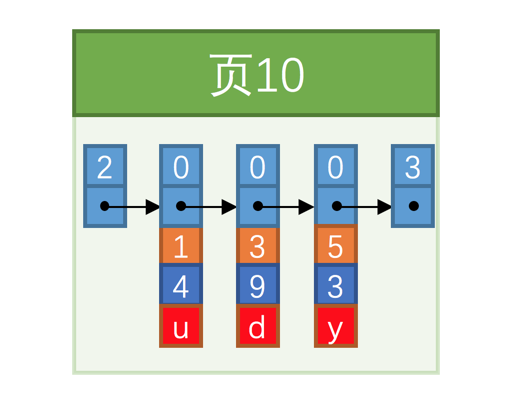
我们在上一篇文章中提到过一个问题,那就是数据的有序性。我们可以从上图看出一点端倪,那就是所有的数据都是以主键的大小值进行排列的。
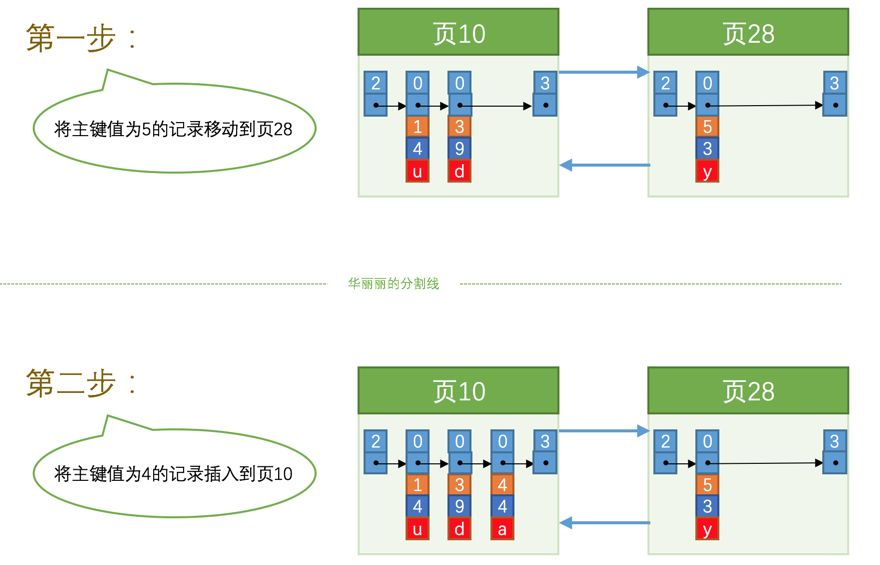
4:假设我们一页只能储存下三条数据,这是假设,一页可以储存很多条数据,但是我们在这里为了方便演示就假设只能储存三条数据,然后我们在新加入一数据:

我们可以看到的是我们新插入的数据分了新的一页,但是很奇怪的一点就是上一个页的号码是10,为什么下一页就是28了?所以我们必须要清楚一点,页号码是不连续的,我们页的双向链表才是维护页秩序的连接,在前面我们也提到过这个问题,使用的是File Header进行储存页码,上一页码,下一页码。我们在前面提到过一个问题那就是数据具有一定的顺序,需要根据主键的大小进行排序,所以应该如下图所示:
5:我们现在搞清楚了数据的排布,那我们在连续插入多条数据在直观的看一下数据:
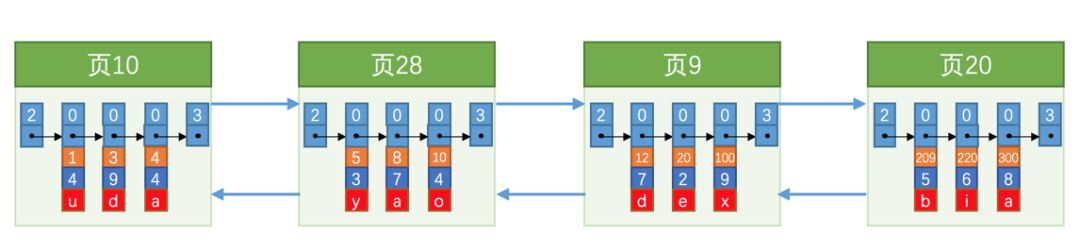
是不是发现了问题,我们如果数据库里还有很多这样的数据,就算是每一页都是有槽的存在,可以帮助我们快速在同一页中定位到数据所在。那么,如果不在一页我们是不是只有按照页的双向链表进行遍历?答案很显然不是,所以我们需要对每个页创建新的东西。
6:目录项:
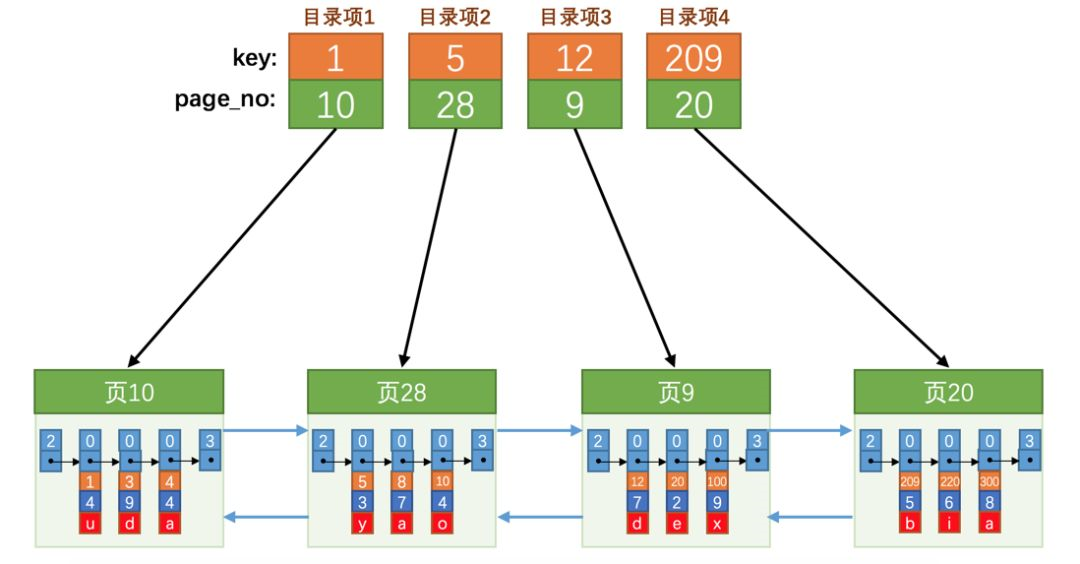
我们可以看到的是我们是不是创建了四个新的东西,这是啥?这就是目录项,一个页对应一个目录项,目录项里面储存的是页码+当前页主键最小的值。到这里是不是就有想法了?这玩意儿和我们自己的数据是不是着实很像。还记得我们在前面提过在数据的记录头信息的record_type这个属性么,0表示普通数据,1表示非叶子节点数据,2表示虚拟最小数据,3表示虚拟最大数据。所以,我们自己的数据和这个目录项数据的区分就是靠着这个属性区分的。除了这个我们的目录项是没有数据库自动添加的三个列的。所以,我们这时候是需要给这些目录项分配一个页,让他们进行储存:
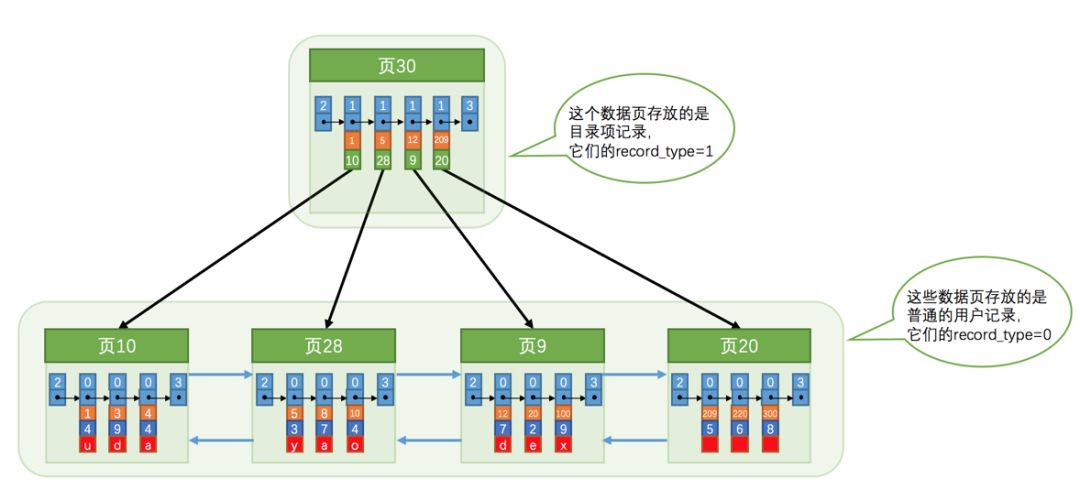
7:到了这里的时候我们大概就能很清楚索引的结构了吧,那么问题又来了,我们的目录项页多了以后怎么办?那还能怎么办,继续再建造上一层目录项页呗。使用当前目录项的页码和当前页最小目录项的主键。
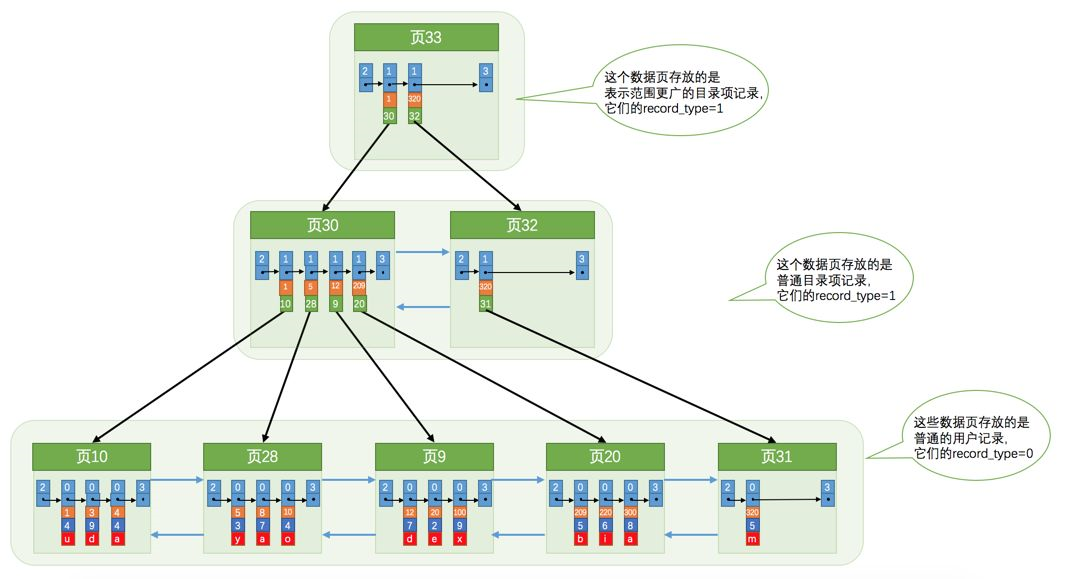
8:索引的查找就是通过一层一层的定位来实现的,最上层的页我们称之为根节点,中间的我们称之为内节点,最底层的我们称之为叶子节点。我们就是通过页中的槽二分法快速的定位数据所在页或者组中,我们在进行遍历查找。最后说一点这玩意儿就是我们说的B+树,也没多大点东西。
总结:
上面我们讲的就是Innodb储存引擎为每个表都会创建的用主键进行构造的聚簇索引,聚簇索引就是所有数据都在叶子节点的索引。
二级索引:
讲完聚簇索引我们就来讲一下什么叫二级索引,二级索引顾名思义就是我们自己创建的索引。有时候我们的业务所需要,我们要根据某个或者是某些字段进行查找,排序,分组等,这时候我们为了加快速度,那么最好的方案就是创建这些列的索引:

我们首先看叶子节点,它的构成就是通过的我们需要使用的列+主键列构成,我们以需要使用的列作为排序的依据。然后我们再看目录项,是用我们需要使用的列+页码组成。以此类推,我们可以得出的结论就是:
1.二级索引和聚簇索引的区别就是叶子节点不包括完整的数据
2.二级索引储存的只是我们需要使用到的列和主键,如果要其它列的数据怎么办?回表:就是通过二级索引获取到的主键然后到聚簇索引里面去进行查找。
联合索引:
上面我们看了一下聚簇索引和二级索引,接下来我们再看一下什么叫联合索引,其实我们可以看出来就是联合指的就是多列进行组合:我们用c2和c3创建
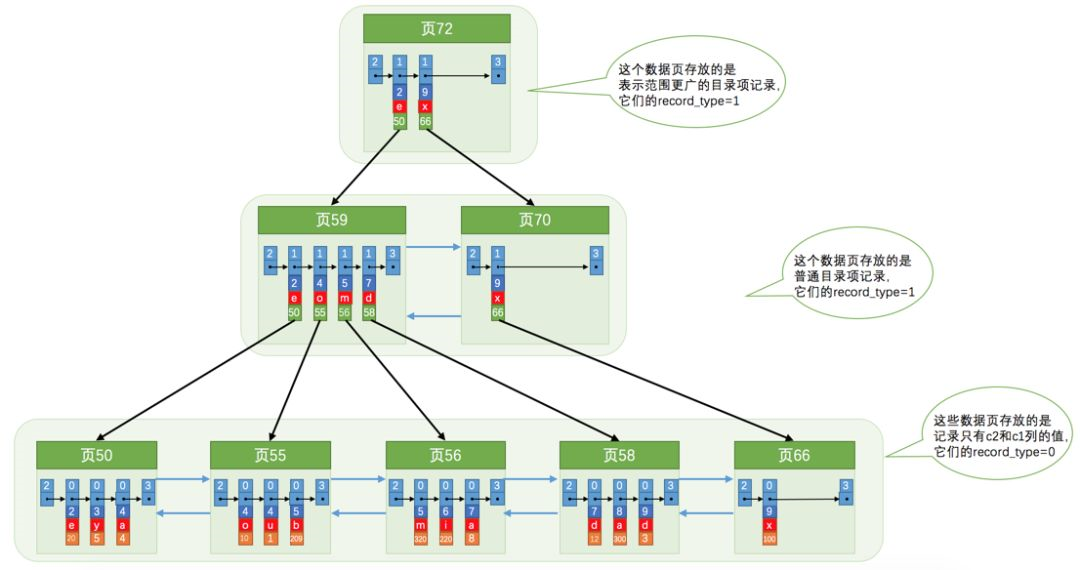
我们可以看到的是联合索引就是用多个字段进行创建索引,然后根据对应列顺序进行排序。比如上图我们使用的就是c2和c3两个列,所以我们就是现根据c2进行排序,如果c2相同的情况下我们再根据c3进行排序。在这里提前说一个注意点:联合索引的使用务必要从最左边也就是最先开始排序的列开始使用。下一篇文章我们再详细讲。
Myisam储存引擎的索引:
我们本来主要使用的储存引擎就是Innodb,但是本着知识的完整性,我们介绍一下myisam储存引擎的索引,其实一句话就说清楚了。myisam的索引的叶子节点是没有保存真实数据的,只保存了主键的值。够清楚了吧,这货就是一个二级索引而已。
索引的创建和删除语法:
1:在建表的时候创建索引:index和key二选其一即可
create tabel 表名(列信息) index|key 索引名(创建索引使用的列)
2:在修改表结构的时候我们创建索引:
alter table 表名 add key|index 索引名(索引使用的列)
3:修改表结构删除索引:
alter table 表名 drop key|index 索引名;