连接查询
--创建学生表
create table students (
id int unsigned not null auto_increment primary key,
name varchar(20) default '',
age tinyint unsigned default 0,
high decimal(5,2),
gender enum('男', '女','保密') default '保密',
cls_id int unsigned default 0,
is_delete bit default 0
);
--创建班级表
create table classes(
id int unsigned auto_increment primary key not null,
name varchar(20) not null
);
--往students表里插入数据
insert into students values
(0,'黄蓉',108,160.00,2,1,0),
(0,'凤姐',44,150.00,3,2,1),
(0,'王祖贤',52,170.00,2,1,1),
(0,'和珅',55,166.00,2,2,0),
(0,'刘亦菲',29,162.00,3,3,0),
(0,'金星',45,180.00,2,4,0),
(0,'静香',18,170.00,1,4,0),
(0,'郭静',22,167.00,2,5,0),
(0,'周杰伦儿',34,null,1,1,0),
(0,'小明',18,180.00,2,1,0),
(0,'小月月',19,180.00,2,2,0),
(0,'彭于晏',28,185.00,1,1,0),
(0,'刘德华',58,175.00,1,2,0),
(0,'程坤',44,181.00,1,2,0),
(0,'周杰',33,178.00,1,1,0),
(0,'钱小豪',56,178.00,1,1,0),
(0,'谢霆锋',38,175.00,1,1,0);
--向classes表里插入数据
insert into classes values (0, '云维_01班'),(0, '云维_02班');
连接查询(内关联)
-- inner join ... on
-- 两个表连接查询
select * from students inner join classes;会出现重复显示
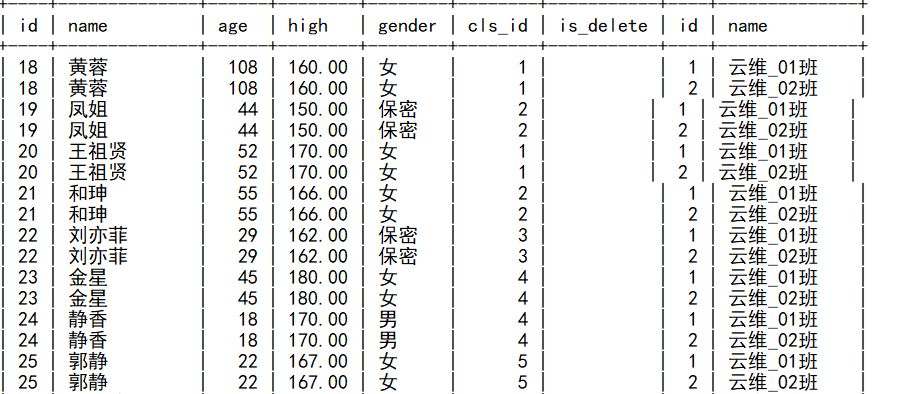
-- 查询能够对应班级的学生以及班级信息
select * from students inner join classes on students.cls_id=classes.id;

-- 按照要求显示姓名,班级
select students.name, classes.name from students inner join classes on students.cls_id=classes.id;

-- 给数据表起别名
select s.name, c.name from students as s inner join classes as c on s.cls_id=c.id;
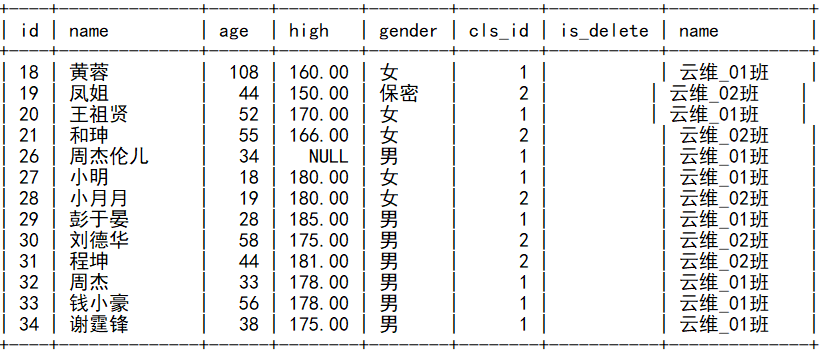
-- 查询 有能够对应班级的学生以及班级信息,显示学生的所有信息,只显示班级名称
select students.*, classes.name from students inner join classes on students.cls_id=classes.id;
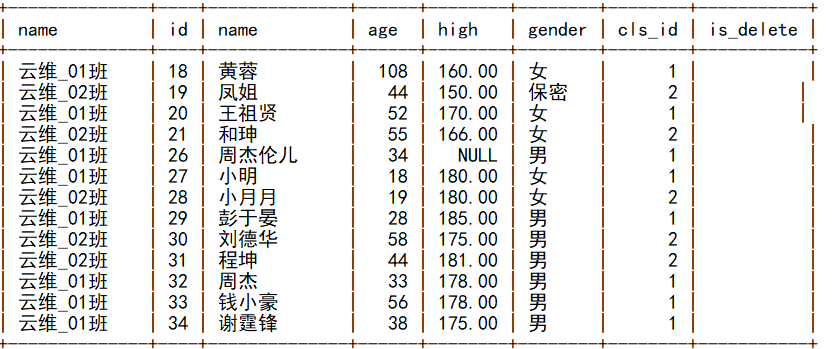
-- 在以上查询中将班级姓名显示在第一列
select classes.name,students.* from students inner join classes on students.cls_id=classes.id;
-- 查询有能够对应班级的学生以及班级信息,按照班级进行排序
select classes.id, students.* from students inner join classes on students.cls_id=classes.id order by classes.id;
-- 当是同一个班级的时候,按照学生的id从小到大
select classes.id, students.* from students inner join classes on students.cls_id=classes.id order by classes.id, students.id;
--连接查询(左关联,右关联)
--左关联,以左边表为基准,条件对应不上的显示null
select * from students left join classes on students.cls_id=classes.id;
--右关联,以后边为基准,条件对应不上的显示null
select * from classes left join students on students.cls_id=classes.id;

自关联
--创建表格
create table areas(aid int primary key auto_increment,name varchar(15),pid int);
--在表格中插入( 数据不一定真实只作为实验)
--省份
insert into areas(aid,name,pid) values(1,'北京市',null);
insert into areas(aid,name,pid) values(0,'天津市',null);
insert into areas(aid,name,pid) values(0,'河北省',null);
insert into areas(aid,name,pid) values(0,'内蒙古',null);
insert into areas(aid,name,pid) values(0,'山西省',null);
--地级市
insert into areas(aid,name,pid) values(0,'海淀区',1);
insert into areas(aid,name,pid) values(0,'滨海区',1);
insert into areas(aid,name,pid) values(0,'沧州市',3);
insert into areas(aid,name,pid) values(0,'大同市',4);
insert into areas(aid,name,pid) values(0,'巴彦淖尔',4);
insert into areas(aid,name,pid) values(0,'朝阳区',1);
insert into areas(aid,name,pid) values(0,'张家口',2);
insert into areas(aid,name,pid) values(0,'石家庄',2);
insert into areas(aid,name,pid) values(0,'太原市',2);
--县级市
insert into areas(aid,name,pid) values(0,'西二旗',5);
insert into areas(aid,name,pid) values(0,'大港',6);
insert into areas(aid,name,pid) values(0,'任丘市',7);
insert into areas(aid,name,pid) values(0,'清徐',8);
insert into areas(aid,name,pid) values(0,'中关村',5);
insert into areas(aid,name,pid) values(0,'汉沽',6);
insert into areas(aid,name,pid) values(0,'河间市',7);
insert into areas(aid,name,pid) values(0,'阳曲',8);
- - 查询出河北京所有区
select * from areas as p inner join areas as z on p.aid=z.pid where p.name='北京市';

select * from areas as p inner join areas as z on p.aid=z.pid where p.name='河北省';

-- 子查询
-- 标量子查询
-- 查询出北京市所有区的信息
select * from areas where pid=(select aid from areas where name='北京市');

select * from areas where pid in (select aid from areas where name='北京市');

数据库的备份与恢复(shell下运行)
#备份testdb数据库
mysqldump -uroot -proot --databases testdb > testdb.sql
#备份所有数据库
mysqldump -uroot -proot --all-databases > all_databases.sql
#备份testdb数据库下的students表
mysqldump -uroot -proot testdb students > students.sql
#还原数据(sql命令行下)
source testdb.sql
视图
对于复杂的查询,在多个地方被使用,如果需求发生了改变,需要更改sql语句,则需要在多个地方进行修改,维护起来非常麻烦
假如因为某种需求,需要将user拆房表usera和表userb,该两张表的结构如下:
测试表:usera有id,name,age字段
测试表:userb有id,name,sex字段
这时如果php端使用sql语句:select * from user;那就会提示该表不存在,这时该如何解决呢。解决方案:创建视图。以下sql语句创建视图:
create view user as select a.name,a.age,b.sex from usera as a, userb as b where a.name=b.name;
视图本质就是对查询的封装
定义视图,建议以v_开头
create view 视图名称 as select语句;
查看视图:查看表会将所有的视图也列出来
show tables;
删除视图
drop view 视图名称;
例:
drop view v_stu_score_course;
使用:视图的用途就是查询
select * from v_stu_score_course;
例:
学生表
select * from students;

班级表
select * from classes;

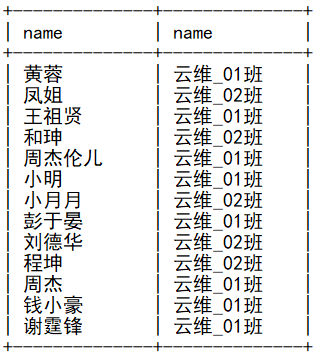
create view v_students as select classes.name as 'c_name', students.name as 'student' from students inner join classes on students.cls_id=classes.id order by classes.id;
事务
为什么要有事务
事务具有ACID特性:原子性(A,atomicity)、一致性(C,consistency)、隔离性(I,isolation)、持久性(D,durabulity)。
事务广泛的运用于订单系统、银行系统等多种场景
例如:甲 用户和 乙 用户是银行的储户,现在 甲 要给 乙 转账500元,那么需要做以下几件事:
检查甲 的账户余额>500元;
甲 账户中扣除500元;
乙 账户中增加500元;
上述3个步骤的操作必须打包在一个事物中,任何一个步骤失败,则必须回滚所有步骤
可以用start transaction语句开始一个事物,然后要么使用commit提交将修改的数据持久保存,要么使用rollback撤销所有修改,事物sql的样本如下:
原子性:事务内的所有操作要么都执行,要么都不执行,它是一个不可分割的工作单位。
一致性:数据库总是从一个一致性的状态转换到另一个一致性的状态(在前面的例子当中,一致性确保了,即使在执行第三、四条语句之间系统崩溃,支票账户也不会损失200美元,因为事物最终没有被提交,所以事物中所做的修改也不会保存到数据库中)
隔离性:一个事物所做的修改在最终提交之前,对其他事物是不可见的(在前面的例子中,当执行完第三条语句、第四条语句还未开始时,此时有另外一个账户汇总程序开始运行,则其看到的支票账户的余额并没有被减去200美元。)
持久性:事务完成后,该事务内涉及的数据必须持久性的写入磁盘保证其持久性。当然,这是从事务的角度来考虑的的持久性,从操作系统故障或硬件故障来说,这是不一定的。
事务命令
要求:表的引擎类型必须是innodb类型才可以使用事务,这是mysql表的默认引擎
查看表的创建语句,可以看到engine=innodb
show create table students;
修改数据的命令会触发事务,包括insert、update、delete
开启事务,命令如下:
开启事务后执行修改命令,变更会维护到本地缓存中,而不维护到物理表中
begin; transaction 也可以开启事务
提交事务,命令如下
将缓存中的数据变更维护到物理表中
commit;
回滚事务,命令如下:
放弃缓存中变更的数据
rollback;
索引
当数据库中数据量很大时,查找数据会变得很慢
优化方案:索引
索引就像书的目录,加快查找的速度,但是索引加的太多会浪费资源,索引也是数据,会影响增删改的速度,所以使用索引看情况而定,主键上有索引的功能,不需要在建索引
语法
- -查看索引
show index from 表名;
- -创建索引
- -方式一:建表时创建索引
create table create_index(id int primary key,name varchar(10) unique,age int,age int,key (age));
- -方式二:对于已经存在的表,添加索引
如果指定字段是字符串,需要指定长度,建议长度与定义字段时的长度一致
字段类型如果不是字符串,可以不填写长度部分
create index 索引名称 on 表名(字段名称(长度))
例:
create index age_index on create_index(age);
--删除索引:
drop index 索引名称 on 表名;
--测试时间
show profiles;#查看sql执行时间
show variables; 查看数据库参数

set profiling=1; #打开sql语句执行时间 零时修改,重启数据库失效
set profiling=0; #关闭sql语句执行时间
外键foreign key
- 如果一个实体的某个字段指向另一个实体的主键,就称为外键。被指向的实体,称之为主实体(主表),也叫父实体(父表)。负责指向的实体,称之为从实体(从表),也叫子实体(子表)
- 对关系字段进行约束,当为从表中的关系字段填写值时,会到关联的主表中查询此值是否存在,如果存在则填写成功,如果不存在则填写失败并报错
语法
查看外键
show create table 表名
添加外键
添加外键时要先确保students表中cls_id的数据和classes的id数据的一致性,不能出现没有的选项
alter table students add constraint f foreign key (cls_id) references classes(id);

通过添加和删除可以发现外键的约束
alter table students add constraint f foreign key (cls_id) references classes(id) on delete cascade;


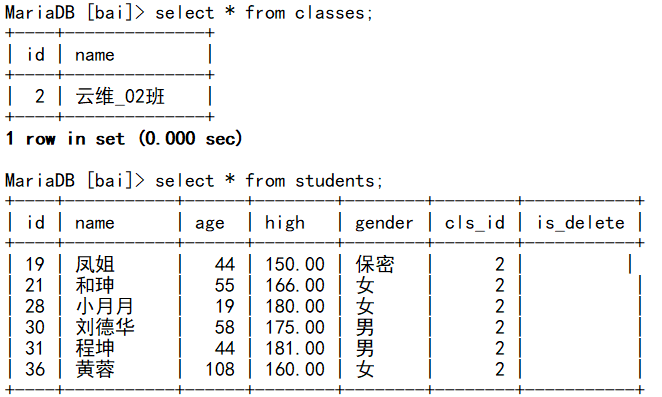
cascade 表示集连,可以通过集连关系删除关联的数据,通过上述实验也不难看出
删除外键
--删除外键
show create table 表名
alter table students drop foreign key 外键名字;
