前言
其实直到这个单元结束,对JML的理解也不是很深,对JML最直观的看法就是对着JML规格写代码很舒服,还有JML真的不怎么好写。
当然,针对这三次作业来谈,其实并不是很理解JML在这次作业中占据的主导地位,更像是给了我一份用JML语言写的代码功能说明书,然后由我自己来决定使用怎样的数据结构和算法来提升代码的性能。
所以,到了后来第三次作业,虽然初衷是考察对JML的理解和掌握,但实际上重心已经跑偏到对算法的挖掘和改造了,当然,我这个不知道怎么想的没有管算法的笨蛋随便实现了规格的功能就没有再管,结果直接导致强测爆0,又一次重现了上单元作业的悲剧(捂脸)——到了最后就疯狂掉链子。实际上,当网站开始强测的时候,我就开始重构代码了(再次捂脸)。只能说,人是真的菜。
好了,接下来按照博客作业的要求对本单元做一次总结。
JML语言的理论基础及应用工具链
JML理论基础
JML(Java Modeling Language,Java建模语言),在Java代码种增加了一些符号,这些符号用来标志一个方法是干什么的,但是不关心它的具体实现。通过使用JML,在实现代码前,我们可以描述一个方法的预期功能,而尽可能地忽略实现,从而把过程性思考一直延迟到方法设计的层面。
如果仅仅是描述方法的功能,那么自然语言一样可以做到,但是,使用JML语言的好处是,相比于容易产生歧义的自然语言,以前置条件、副作用、异常行为、作用域、后置条件等为标准规格的JML规格语言能减少歧义的产生。
关于JML规格的举例
/*@ public normal_behavior(注:一般行为)
@ requires class != null;(注:前置条件)
@ assignable \nothing;(注副作用)
@ ensures \result = (class == nowclass)(注:后置条件、\result-返回值)
@ also
@ public exceptional_behavior(注:异常行为)
@ signals (ClassNotValid e) class == null;(注:抛出异常)
*/
当然,是语言就会有问题,但是,严格的JML语言避免了本身的歧义,一旦出现问题,就很容易能找到是JML规格的描述问题还是代码的实现问题。对客服而言,能提早发现客户代码对类地错误使用,还能给客户提供和代码完全一致地JML规格文档;而对于程序员,能够准确地知道代码需要实现的功能,高效地寻找和修正程序的bug(对比代码和规格便知),还能在代码升级时降低引入bug地可能。
注:以上内容部分参考 :寿智振 ,《应用建模语言 JML 改进 Java 程序》,https://wenku.baidu.com/view/af526b94fc4ffe473368abc0.html。
JML工具链
- JML具有标准的格式,因此可以对其进行语法和格式上的检查,一般可以采用Openjml等工具进行JML规格的静态检查。
- 而使用JMLUnitNG/IMLunit之类的工具,可以在设计测试方法,检查JML规格和相应的代码实现情况。
JMLUnitNG实现简单的测试
测试代码:
// demo/Demo.java package demo; public class Demo { /*@ public normal_behaviour @ ensures \result == (lhs != rhs); */ public static boolean notequal(int lhs, int rhs) { return rhs != lhs; } public static void main(String[] args) { notequal(-1,0); } }
输出结果:
[TestNG] Running:
Command line suite
Passed: racEnabled()
Passed: constructor Demo()
Passed: static main(null)
Passed: static main({})
Passed: static notequal(-2147483648, -2147483648)
Passed: static notequal(0, -2147483648)
Passed: static notequal(2147483647, -2147483648)
Passed: static notequal(-2147483648, 0)
Passed: static notequal(0, 0)
Passed: static notequal(2147483647, 0)
Passed: static notequal(-2147483648, 2147483647)
Passed: static notequal(0, 2147483647)
Passed: static notequal(2147483647, 2147483647)
===============================================
Command line suite
Total tests run: 13, Failures: 0, Skips: 0
===============================================
分析和假想:
首先感谢大佬在讨论区的分享,我折腾了三个小时总算搞出来一个勉强看过去的测试样例,虽然这个样例是仿照大佬分享的简单例子。
虽然这个完全实现了简单的规格,也就是边界测试没有Failures,但是我最初写的测试例子还包括异常抛出,但是由于没有时间了,只能草草完成了这么一个简单的例子,更深入的分析也没有做(沮丧)。
梳理几次作业架构的设计
第一次作业:
类图:
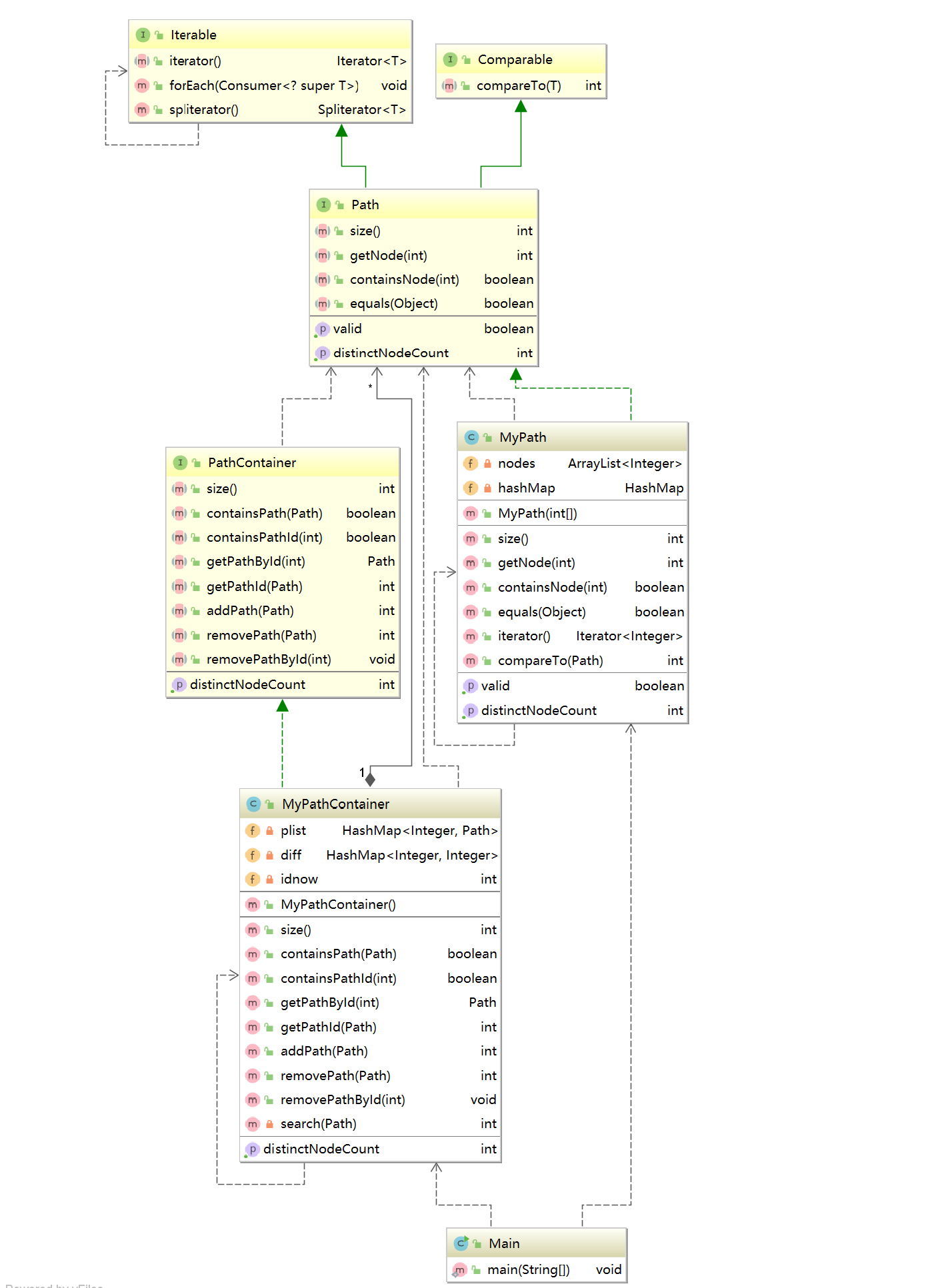
分析:
第一次作业其实没有什么好分析,从图中可以看出,我在MyPath类中采用了HashMap类,为了方便统计一个路径中不同节点的个数,其次实现了Compareto和Iterator接口,实现了比较和迭代器,迭代器允许遍历访问MyPath类中指定的数据元素而没有暴露出数据实现本身。而在MyPathContainer中完全采用了HashMap存储路径信息,但是因为没有重写hashcode的产生方法,在比较路径相等时调用了Path的迭代器进行了挨个节点比较,这里的效率比较低。
第二次作业:
类图:
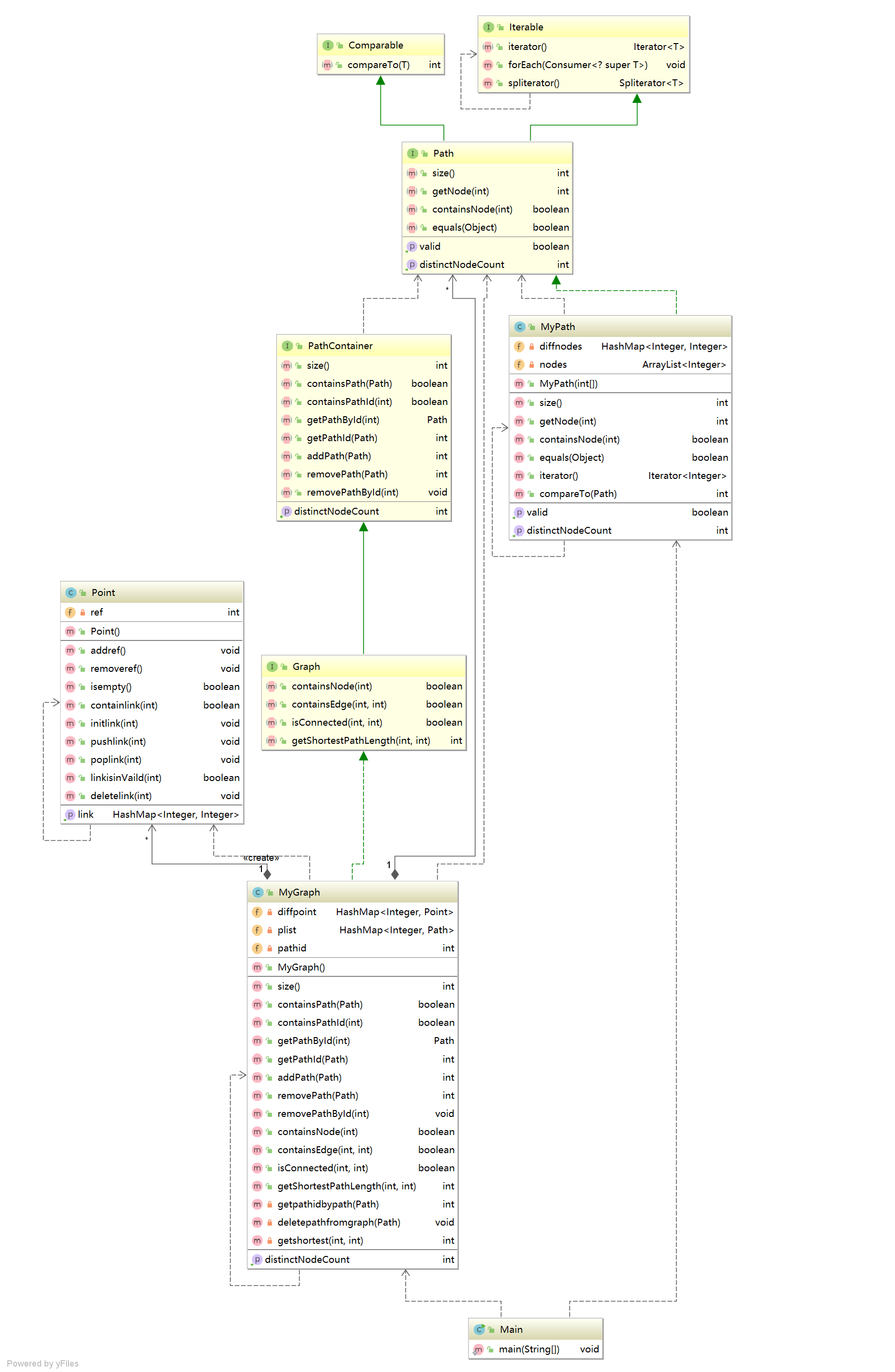
分析:
第二次作业相当于在第一次作业规格的基础上增加了四个查询方法,基本上是在第一次代码上做了一些修改完成的。在数据结构上,仅从规格说明的角度看,增加了图的结构。因此,作为一个邻接链表的忠实爱好者,我义无反顾地实现了一个Point类,用来存储点的数据结构,而diffpoint的Hash value也变成了Point类,以此完成了一个邻接链表。Point内部属性非常简单,ref表示该点被引用次数,link表示该点与其他点连接的情况,而在Graph类中除了在添加Path的时候需要修改原本在地磁作业实现的add类方法外,还需要实现一个deleteformgraph的规格外方法来从图中删除路径,同时还有一个getshortest方法内置了bfs(广度搜索遍历)来支持规格中的getShortestPathLength方法。
BFS代码如下:
private int getshortest(int fromnode,int tonode) { if (fromnode == tonode) { return 0; } HashMap<Integer,Integer> sign = new HashMap<>(); ArrayList<Integer> nodelist = new ArrayList<>(); int length = 0; Iterator iterator = diffpoint.get(fromnode). getLink().entrySet().iterator(); int limit = 0; while (iterator.hasNext()) { HashMap.Entry entry = (HashMap.Entry) iterator.next(); int key = Integer.class.cast(entry.getKey()); nodelist.add(key); sign.put(key,key); } length = 1; limit = nodelist.size() - 1; if (sign.containsKey(tonode)) { return length; } int pointer = 0; for (;pointer < nodelist.size();pointer += 1) { iterator = diffpoint.get(nodelist.get(pointer)) .getLink().entrySet().iterator(); while (iterator.hasNext()) { HashMap.Entry entry = (HashMap.Entry) iterator.next(); int key = Integer.class.cast(entry.getKey()); if (!sign.containsKey(key)) { nodelist.add(key); sign.put(key,key); } } if (sign.containsKey(tonode)) { return length + 1; } if (pointer == limit) { limit = nodelist.size() - 1; length += 1; } } return -1; }
第三次作业:
类图:
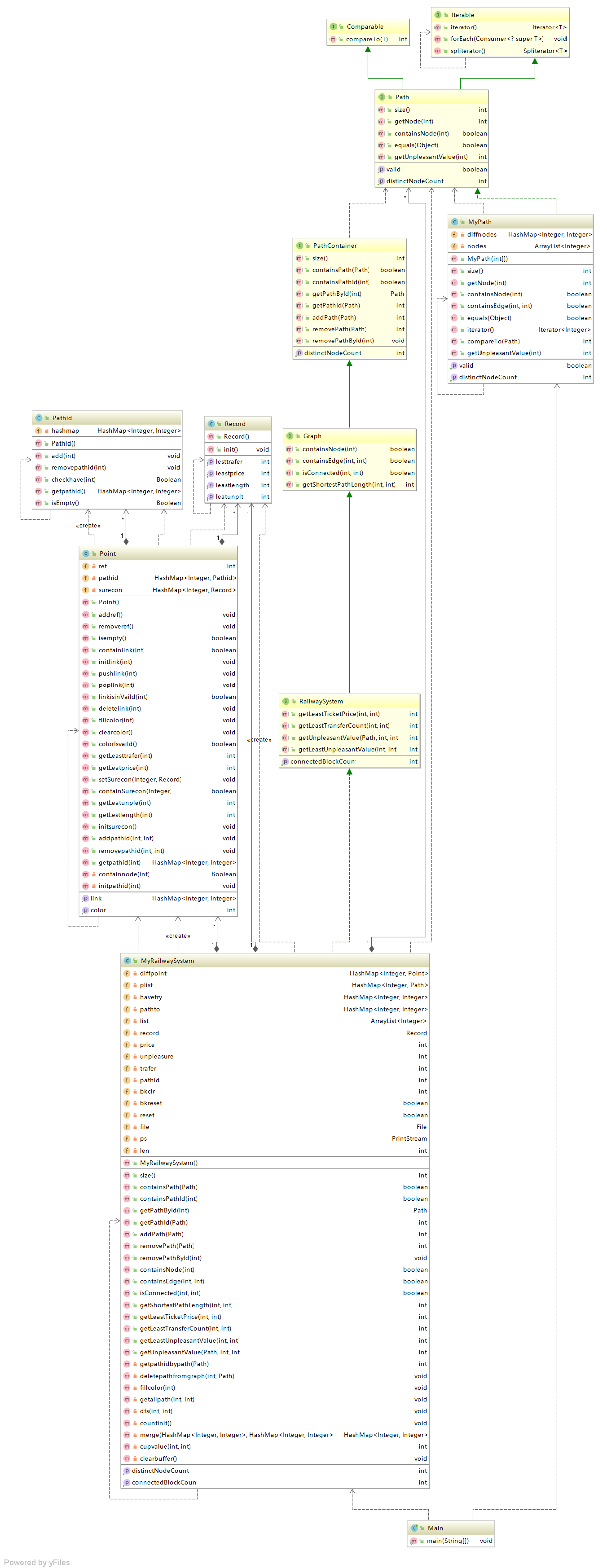
分析:
第三次作业无论是从算法还是从架构的设计上都可以说是彻彻底底的失败。
因为,地铁类是在第二次作业的基础上拓展的规格,因此,在架构的实现上我沿用了之前的实现方式,即继续采用邻接表。这里就不得不提到从第二次作业就开始的算法偏重讨论。从第二作业开始,因为查询图是件麻烦事,所以大部分同学都比较支持进行全面的图的计算,然后查询时为O(1)的算法偏重,但是由于第二次作业使用了邻接表,那么florid算法的实现就比较难受,因此我在第三次魔改了深度遍历搜索,或者说完全放弃了算法的性能,采用了全部遍历两点之间所有的路径,然后计算不满意度、最小换乘等问题,这直接导致我强测爆炸。
而对架构的伤害,因为思路采用了和第二次一样的暴力求解,就迫使我对Point类进行大量的增添,其中最重要的一块就是边和路径id的统一,这也迫使我增加了pathid和record两个类。
虽然原本的架构基本没有重构,但在原本哪个已经落伍于全新版本的架构上继续增加的冗余部分进一步导致了架构的劣化,也就是说,如果在这次作业基础上继续增加新的功能的话,我的架构会更加难看。其次,为了便于使用Point类内的属性,我直接返回了Point类的私有对象,又是一大败笔。
重构作业:
类图:
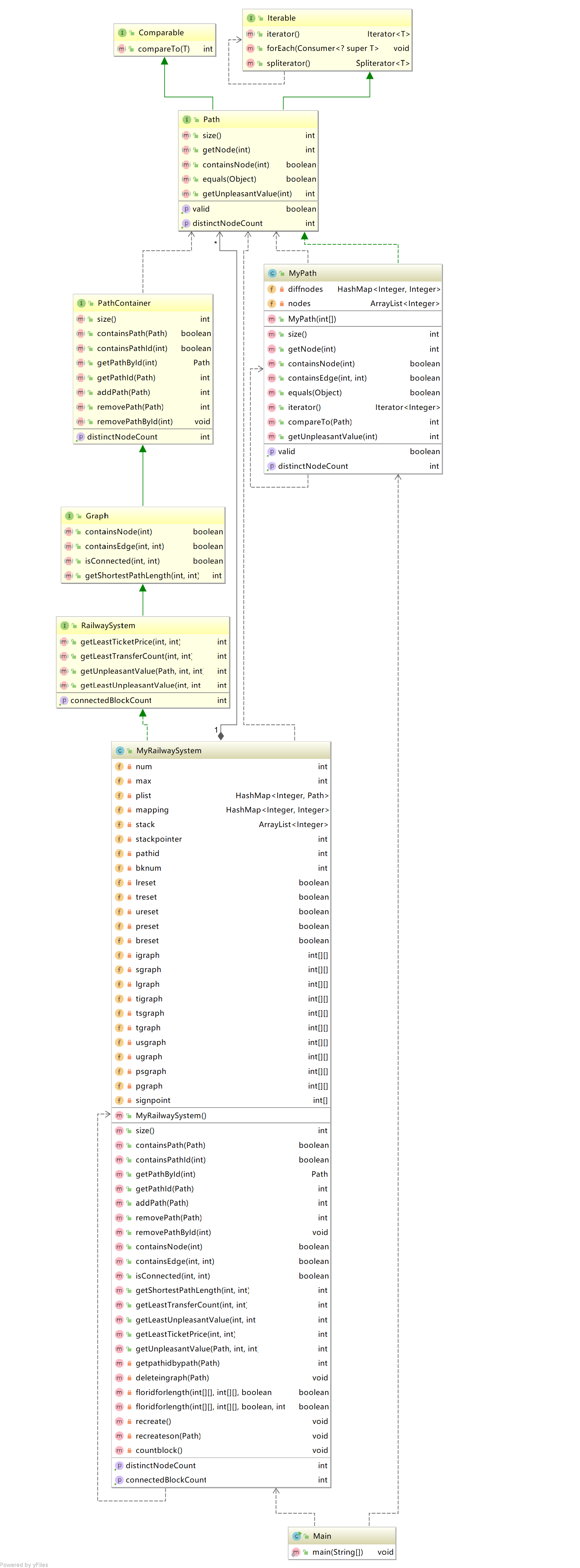
分析:
我基本上在重构的时候完全重写了第二次和第三次作业(捂脸),重构的思路其实建立在florid算法的基础上。因此采用了大量的二位静态数组作为存储相关数据的邻接矩阵。架构上其实没有什么值得一谈的东西,相比起之前的邻接表的做法,这种做法更加暴力,增加功能的话增加相应的二维数组对就行了,一个用来存储当前图对应的数据,另一个用来存储经过florid算法后得到的内容,所以表示同一功能的二维数组基本上是成对出现的。而在这个基础把不满意度、换乘、最小票价问题都利用相应的算法转化为一般的florid模式,大大减少了代码量。除此以外,florid也设计成了一个具体的功能方法,有助于代码的简化。
florid方法代码:
private boolean floridforlength(int[][] src,int[][] dst ,boolean reset,int rin) { if (!reset) { return false; } for (int i = 0; i < num; i += 1) { for (int j = 0; j < num; j += 1) { dst[i][j] = src[i][j]; } } for (int k = 0; k < num; k += 1) { for (int i = 0; i < num; i += 1) { for (int j = 0; j < num; j += 1) { int temp; if (i == j || dst[i][k] == max || dst[k][j] == max) { temp = max; } else { temp = dst[i][k] + dst[k][j] + rin; } if (dst[i][j] > temp) { dst[i][j] = temp; } } } } return false; }
代码实现bug及修复情况
算法bug:
这个严格意义上说并不算bug,只是这次造成的后果比较严重所以拿出来谈一下。
根据我这次教训,我觉得这种bug,完全可以在设计前能找到,但是自己不一定能找到,因为当局者迷。而这种Bug出自我对问题的难度和问题的侧重点认识不足的情况。以这次为例,我在最初设计算法的时候,只考虑了怎么解决换乘的问题,而没有解决算法的性能问题,这使得算法最终成形的时候几乎没有性能这一概念。因此,我开始写算法题了(捂脸),让自己适应去思考怎么做才能更优化。
其它bug:
除了上面的算法问题外,其它几乎没有什么毛病,包括我智障地调用了错误的方法啥的都不值得讨论。但有一点值得讨论一下,那就是Java的对象引用。
我对对象的引用就看成了C的指针,实际上用起来差别不是很大,但是在实际使用的时候会犯一些不是很容易发现的小错误。
private void countinit() { havetry.clear(); list.clear(); record = new Record(); price = 0; trafer = 0; unpleasure = 0; }
上面是我写的一个初始化方法,该方法每次都会在某些方法使用前调用,可以看到我这里写了一句
record = new Record();
而我之前是这么写的
record = record.init();
而其调用的init方法如下
public void init() { lesttrafer = -1; leastprice = -1; leatunplt = -1; leastlength = -1; }
以上使用看起来没问题,实际上问题很大。因为我是对一个record对象调用init()方法,而这个record对象会被我put进某些HashMap对象中,那么当我再次调用countinit()方法后,已经被put进去的数据会被初始化,然后同化为下一次计算的结果。
我觉得这应该是对引用的滥用导致的,以及我应该给每个类写一个clone方法提醒自己浅拷贝和深拷贝的区别。
规格撰写和理解上的心得体会
首先,我认为这三次课下作业对规格的撰写没有涉及,其次,两次课上对规格撰写和修改的练习,也仅仅停留在对JML规格语法的实践和练习上。
我认为,JML规格,或者说一般意义上的规格,是为了软件开发和团队合作而生的。
其在团队合作的作用应该是减少不同人代码开发的耦合度,同时划分明确的分工。
在软件开发的层面上,更多地侧重于把软件功能层次化,细分化。
规格,侧重于功能而非实现,也就是先给出了一个具体地框架,我认为可以理解为给出了一个黑箱,规格一开始要说明这个黑箱能干什么;然后,规格会进一步拆解这个黑箱,去说明更多的小黑箱能干什么;最终规格会缩小到方法地层面上,说明一个方法黑箱应具有怎么样地输入和输出。
对于规格地实现,我的理解是,只需要理解规格给出的功能性说明,而不需要在意规格给出的可能的代码逻辑。举个最简单的例子,第一次作业中Path的数据规格给了一个int[]的类型,实际上这只是说明存在这样的数据结构,而非一定要实现这样的数组,实际上,真正这么搞的同学估计没有几个。
我觉得规格使用相当有必要,而且在完成规格后再实现代码会具有更高的效率。目前为止,我所接触的代码都是很小的,几乎不成功能,但是我觉得如果我想完成一个软件,那么我不仅会写设计文档,还会在完成设计文档后,写详细的规格说明书,最后再开始实现代码。