本单元的三次作业与JML有关,都是依据课程组下发的JML规格实现相应的类及方法。
一、JML语言的理论基础及应用工具链
1.1 JML语言的理论基础
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。JML是一种行为接口规格语言(Behavior Interface Specification Language),基于Larch方法构建,可用于指定Java模块的行为。它结合了Eiffel的契约式设计方法和Larch接口规范语言家族的基于模型的规范方法,以及一些细化演算的元素。由Gary T. Leavens和Yoonsik Cheon撰写的《Design by Contract with JML》(采用JML的契约式设计)中,解释了JML作为java契约式设计(DBC)语言的最基本用法。
一般而言,JML语言有两种主要的用法:
(1)开展规格化设计。这样交给代码实现人员的将不是可能带有内在模糊性的自然语言描述,而是逻辑严格的规格。
(2)针对已有的代码实现,书写其对应的规格,从而提高代码的可维护性。这在遗留代码的维护方面具有特别重要的意义。
1.2 JML语言的应用工具链
在官网的download界面,介绍了JML语言相应的工具。网址为http://www.eecs.ucf.edu/~leavens/JML//download.shtml。
OpenJML:
对于Java 1.5以上的版本,建议首先考虑OpenJML。根据其在官网上的介绍,OpenJML项目的目标是为JML和当前的Java实现一个完整的工具,便于实践者和学生使用该工具去指定和验证Java程序。此外,该项目寻求在实际的、与工业相关的环境中推进软件验证的理论和经验。OpenJML支持静态和执行时检查,并且整合了应用广泛的SMT Solver。
AspectJML:能够为Java和AspectJ程序指定并执行运行时断言检查。
jml4c:基于Eclipse Java编译器构建的JML编译器。它将JML规范的一个重要子集转换为运行时检查。
Sireum/Kiasan for Java:是一个基于JML契约的Java程序单元自动验证和测试用例生成工具集。
JMLEclipse:是在Eclipse的JDT编译器基础设施之上开发的JML工具套件的预alpha版本。
JMLUnitNG:是一个用于jml注释的Java代码的自动化单元测试生成工具,包括使用Java 1.5+特性(如泛型、枚举类型和增强的for循环)的代码。与最初的JMLUnit一样,它使用JML断言作为测试预言。它改进了原来的JMLUnit,允许为被测试类的每个方法参数轻松定制数据,以及使用Java反射自动生成非基本类型的测试数据。
JMLOK:使用随机测试来根据JML规范检查Java代码,并为它发现的不一致问题提出可能的原因。
二、部署SMT Solver及验证
我在Idea上集成了OpenJML插件,并从官网上下载了相关Solvers,在Idea中选择使用的Solver。由于cvc4-1.6运行报错,z3-4.3.2和win10不兼容,我选择了z3-4.7.1。
我从MyPath类中选择了三个简单的方法,并自己写了一个有溢出可能的compare方法如下:
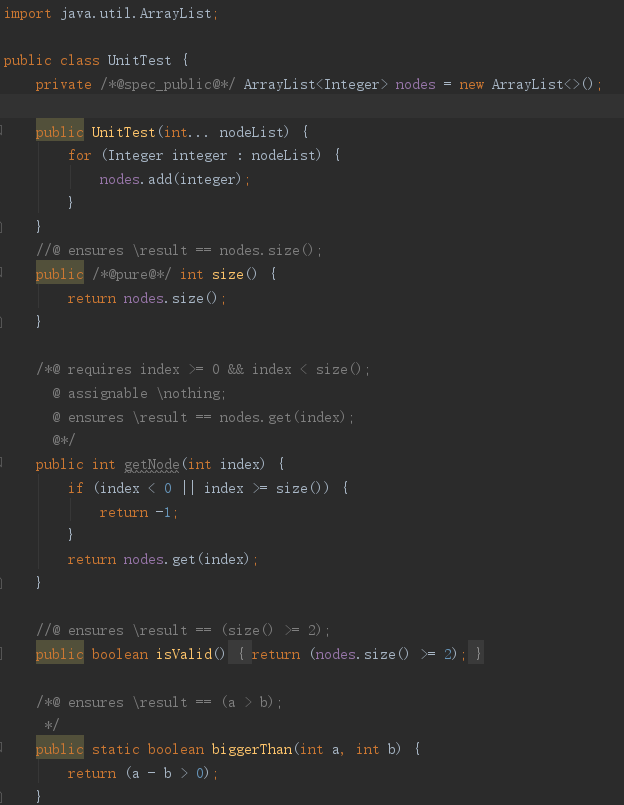
对其进行检查,结果如下:
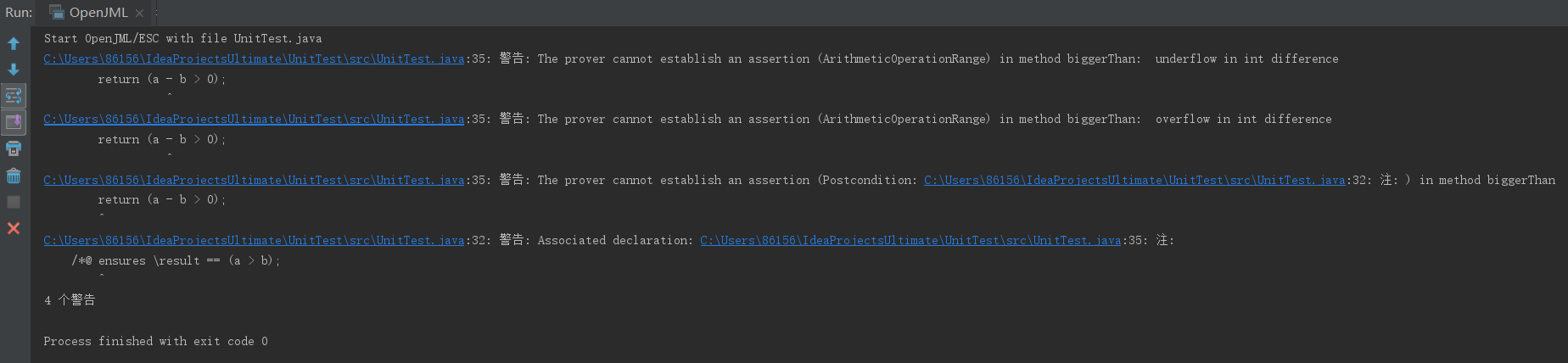
检验出了溢出的危险。
三、部署JMLUnitNG并生成测试用例
在官网上下载了JMLUnitNG的jar包,但由于我所使用的环境为jdk 11,在运行时会报错NoSuchFieldError的错误。重新安装了jdk 8并且配置了环境变量后才能够正确运行。参考了诸多网上的博客,总结步骤如下:
1. 进入OpenJML文件夹下。
2. 建立一个新文件夹unitTest,将需要检测的UnitTest.java放在文件夹unitTest下。
3. 生成测试文件:java -jar jmlunitng.jar unitTest/UnitTest.java
4. 编译测试文件:javac -cp jmlunitng.jar unitTest/UnitTest_JML_Test.java
5. 编译源文件:javac -cp jmlunitng.jar unitTest/UnitTest.java
6. 测试:java -cp jmlunitng.jar unitTest/UnitTest_JML_Test
这里使用二中的UnitTest类进行测试,测试结果如下:

报错的两个点在构造函数的传参上,没有考虑到传入参数为null或者为{}的情况。从生成的测试样例中,也能够看JMLUnitNG注重对边缘极端数据的覆盖。
四、作业架构设计及迭代
4.1 第一次作业
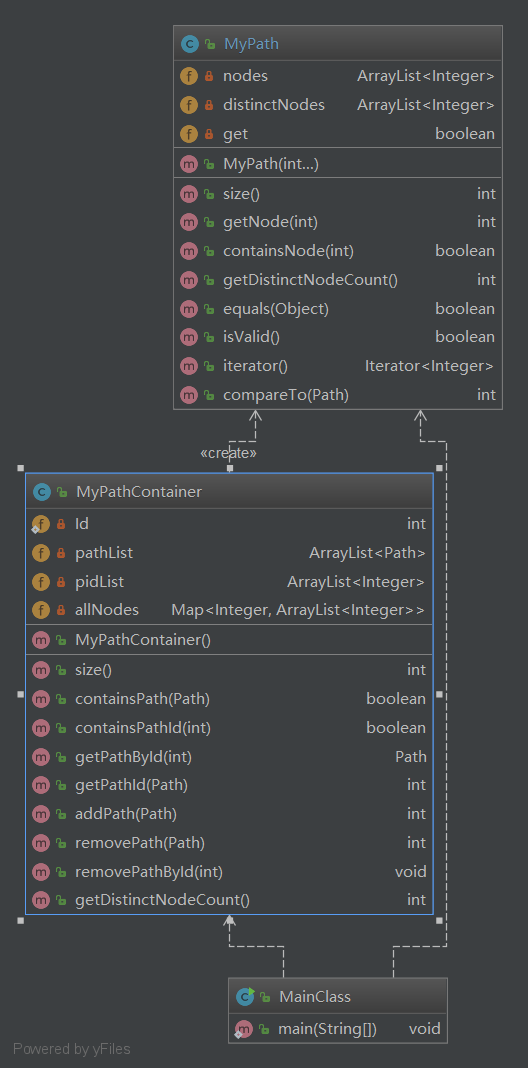
这次作业中,pathList和pidList我都是用ArrayList来存,事实上对其直接遍历也只有线性复杂度,卡时间的大头在于指令DistinctNodeCount。为此我用allNodes这样一个HashMap来保存不同的节点及其所在的路径Id,每次添加或者删除路径时,对其进行维护,若删除路径后节点对应的路径序列为空,则删除这一节点;若路径中的节点没在allNodes.keys()中,则进行添加。每次统计时只需要返回allNodes.size()即可。顺利过关。
4.2 第二次作业
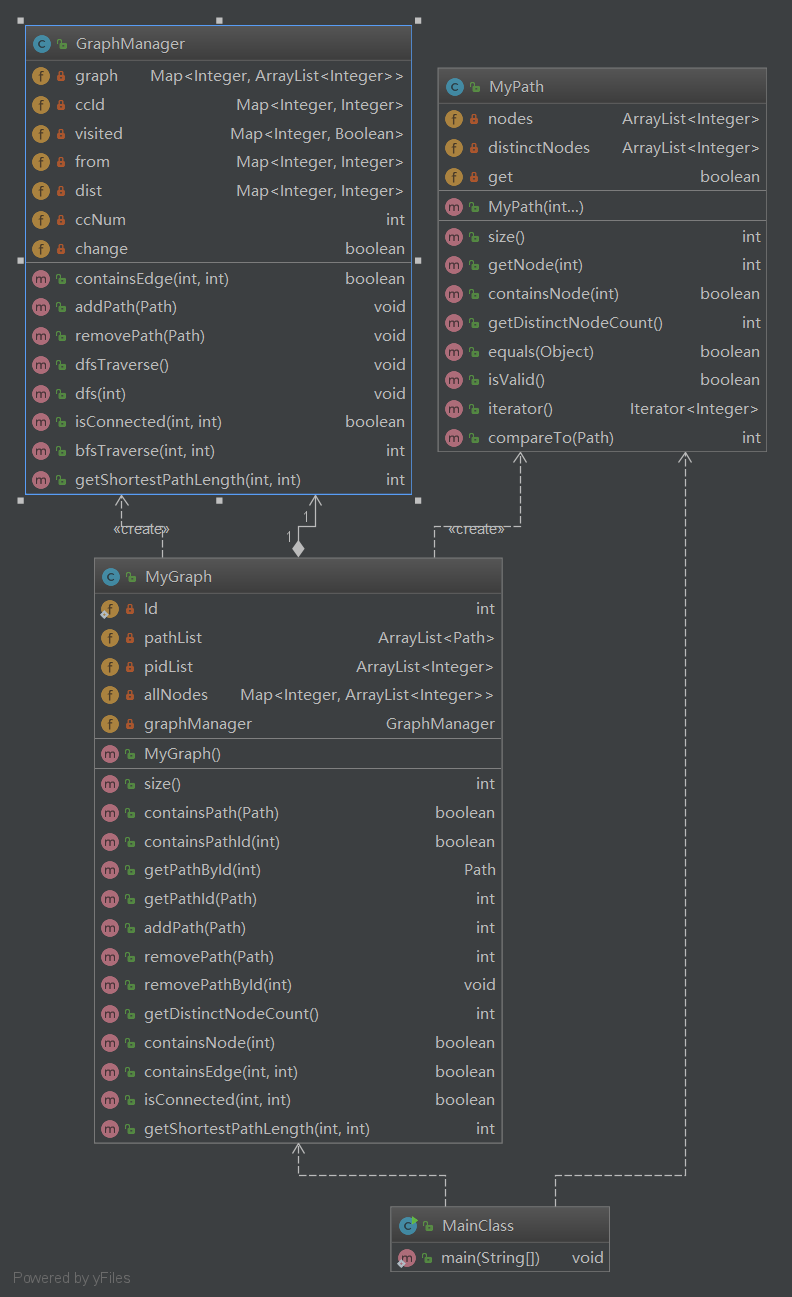
本次作业中,相比于上一次作业,增加了一个GraphManager类,专门负责图的构建和相应的方法实现。并实例化该类作为MyGraph类的成员。MyGraph类在PathContainer的基础上,有新增的方法,涉及图的构建、增加或者删边以及查询等方法均调用GraphManager类中的相应方法进行。通过这样的设计,将容器类和图的管理分开,使得功能划分更为清晰,更容易管理。
本次新增了两个主要方法为查询两个节点是否连通以及两个节点最短距离。查询两个节点是否连通,用深度优先搜索就可以得到所有的连通分量,并记录每个节点所在的连通分量编号。经过一次彻底的搜索后,由于图的结构变更指令较少,接下来只需要查找两个节点对应的连通分量编号是否相同即可。对于两个节点最短距离,由于每条边的权为1,广度优先无需缓存就可以轻松通过。
4.3 第三次作业
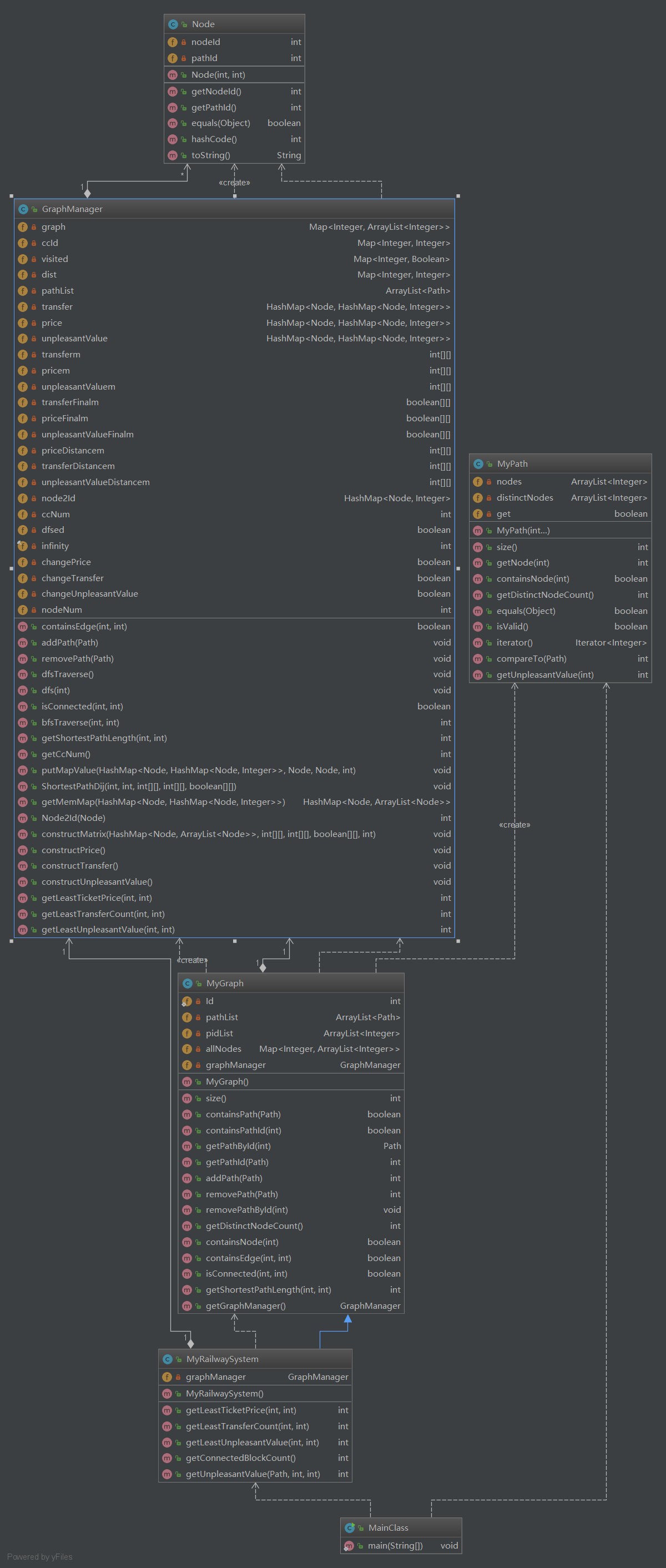
本次作业相比于上一次,只增加了一个Node类用于拆点的记录。增加了MyRailwaySystem类,继承了MyGraph类,并且实现了四个主要方法:最低票价、最少换乘次数、最小不满意度以及连通分量个数。对于连通分量个数,只要在进行DFS后就可以得到。其余的三个方法均可以转化为带权图的最短路径。我采用了讨论区的拆点方案,即将每个点拆成入口、出口以及站台。拆点会大大增加图的节点数以及边数。这次作业我在HashMap上吃了一个大亏,开始时我不想做节点编号到图中编号的映射,直接用了二维HashMap当做邻接矩阵处理。后来发现当路径数量较多时,建一次图需要5-6秒时间。我开始怀疑HashMap遍历的效率,于是测试了一下二维数组和二维HashMap的遍历效率,发现数组只需要不到1ms完成的任务,HashMap用了35ms,差距太大。于是不得已做了映射并重写了之前的代码。
在缓存处理上,我直接在distance(距离矩阵)和isFinal(标记矩阵)上进行。在进行Dijkstra算法时,需要将中间结果进行保存。算法如下:
1 public void ShortestPathDij(int start, int end, int[][] graph 2 , int[][] distance, boolean[][] isFinal) {
//若start行没有搜索过,则对其进行初始化 3 if (!isFinal[start][start]) { 4 for (int i = 0; i < nodeNum; i++) { 5 distance[start][i] = graph[start][i]; 6 isFinal[start][i] = false; 7 } 8 } 9 int count = 0; 10 distance[start][start] = 0; 11 isFinal[start][start] = true;
//统计start行已经得到最短路径的个数count 12 for (int i = 0; i < nodeNum; i++) { 13 if (isFinal[start][i]) { 14 count++; 15 } 16 }
//还需要计算最短路径的节点个数为nodeNum - count 17 for (int i = 0; i < nodeNum - count; i++) { 18 int min = infinity; 19 int v = start; 20 for (int w = 0; w < nodeNum; w++) { 21 if (!isFinal[start][w]) { 22 if (distance[start][w] < min) { 23 v = w; 24 min = distance[start][w]; 25 } 26 } 27 } 28 isFinal[start][v] = true; 29 for (int w = 0; w < nodeNum; w++) { 30 if (!isFinal[start][w] && (min + graph[v][w] 31 < distance[start][w])) { 32 distance[start][w] = min + graph[v][w]; 33 } 34 }
//在更新完与end节点有关的点的distance后,退出。 35 if (v == end) { 36 break; 37 } 38 } 39 }
在对Dijkstra算法进行这样的修改后,就能够起到缓存的作用。我在本地也进行了测试,若没有缓存处理,对于50条PATH_ADD以及6000条LEAST指令,需要20-25s,但在进行缓存处理后,只需要10s左右。
五、代码实现的bug及修复情况
第一次作业在compareTo方法上栽了,参照String类的compareTo()来实现,直接返回了两个不一样node的差值,忽略了减法溢出的问题。分数扣得蛮心疼的,至于bug修复,直接改成Integer.compare()或者自己直接写比较返回1或者-1就可以了。
第二次作业中,我加强了对边缘数据的测试,并且基于networkx库用Python写了一个对比的程序,与自己写的Java程序进行对拍,最终没有出现bug。
第三次作业中,在进行缓存处理时,为了避免出错,我写了一个耗时很长但能保证正确性的程序,与缓存版本进行对拍,也保证了正确性,没有出现bug。
六、规格撰写和理解的心得体会
本单元对规格的学习让我了解了契约式设计的重要性,通过规格的撰写,能够明确各类及方法需要实现怎样的功能,一方面使得代码实现人员能够根据规格完成代码,另一方面能够提高代码的可维护性,使得维护人员能够迅速理解各个方法的功能。通过OpenJML等工具能够静态检查代码的实现是否满足相应的规格,并且可以根据规格构造测试样例,从而保证代码实现的正确性。这样的思路对于我来说,真的是醍醐灌顶,打开了新世界的大门。然而在实际应用时,还是遇到了不少困难。由于规格是对功能的高度抽象,同时为了正确性需要严密的逻辑。一个方法规格中如果有较多的中间过程,就容易使人困惑。第三次作业的RailwaySystem类中的方法规格,着实让人看得头晕眼花,LeastTicketPrice方法那好几行的规格,远远不如这个词容易理解。但严密的逻辑和高度抽象对于正确性的保证却又是至关重要的。