记录一下Java API 连接hadoop操作hdfs的实现流程(使用连接池管理)。
以前做过这方面的开发,本来以为不会有什么问题,但是做的还是坑坑巴巴,内心有些懊恼,记录下这烦人的过程,警示自己切莫眼高手低!
一:引入相关jar包如下
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.8.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.8.2</version> </dependency> <!-- commons-pool2 连接池用 --> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> <version>2.6.0</version> </dependency>
二:连接池开发的基本流程
2.1项目基本环境是SpringBoot大集成···
2.2hadoop相关包结构如下(自己感觉这结构划分的也是凸显了low逼水平【手动笑哭】)

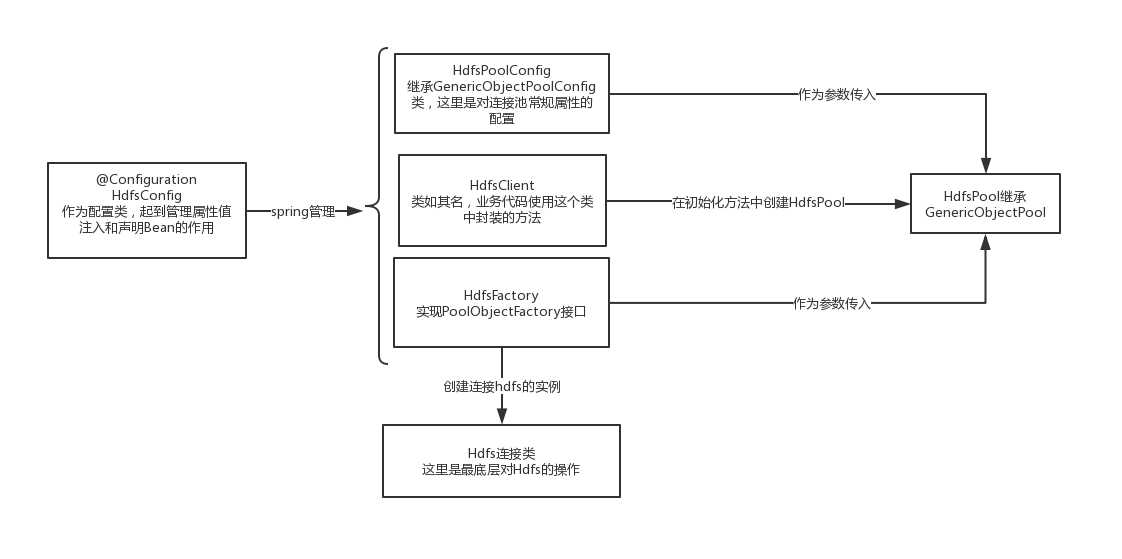
2.2 画个图表达下开发思路
三、上代码
import com.cmcc.datacenter.hdfs.client.HdfsClient; import com.cmcc.datacenter.hdfs.client.HdfsFactory; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class HdfsConfig { @Value("${hadoop.hdfs.ip}") private String hdfsServerIp; @Value("${hadoop.hdfs.port}") private String hdfsServerPort; @Value("${hadoop.hdfs.pool.maxTotal}") private int maxTotal; @Value("${hadoop.hdfs.pool.maxIdle}") private int maxIdle; @Value("${hadoop.hdfs.pool.minIdle}") private int minIdle; @Value("${hadoop.hdfs.pool.maxWaitMillis}") private int maxWaitMillis; @Value("${hadoop.hdfs.pool.testWhileIdle}") private boolean testWhileIdle; @Value("${hadoop.hdfs.pool.minEvictableIdleTimeMillis}") private long minEvictableIdleTimeMillis = 60000; @Value("${hadoop.hdfs.pool.timeBetweenEvictionRunsMillis}") private long timeBetweenEvictionRunsMillis = 30000; @Value("${hadoop.hdfs.pool.numTestsPerEvictionRun}") private int numTestsPerEvictionRun = -1; @Bean(initMethod = "init", destroyMethod = "stop") public HdfsClient HdfsClient(){ HdfsClient client = new HdfsClient(); return client; } /** * TestWhileConfig - 在空闲时检查有效性, 默认false * MinEvictableIdleTimeMillis - 逐出连接的最小空闲时间 * TimeBetweenEvictionRunsMillis - 逐出扫描的时间间隔(毫秒) 如果为负数则不运行逐出线程,默认-1 * NumTestsPerEvictionRun - 每次逐出检查时 逐出的最大数目 * */ @Bean public HdfsPoolConfig HdfsPoolConfig(){ HdfsPoolConfig hdfsPoolConfig = new HdfsPoolConfig(); hdfsPoolConfig.setTestWhileIdle(testWhileIdle); hdfsPoolConfig.setMinEvictableIdleTimeMillis(minEvictableIdleTimeMillis); hdfsPoolConfig.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis); hdfsPoolConfig.setNumTestsPerEvictionRun(numTestsPerEvictionRun); hdfsPoolConfig.setMaxTotal(maxTotal); hdfsPoolConfig.setMaxIdle(maxIdle); hdfsPoolConfig.setMinIdle(minIdle); hdfsPoolConfig.setMaxWaitMillis(maxWaitMillis); return hdfsPoolConfig; } @Bean public HdfsFactory HdfsFactory(){ return new HdfsFactory("hdfs://" + hdfsServerIp + ":" + hdfsServerPort); } }
import org.apache.commons.pool2.impl.GenericObjectPoolConfig; public class HdfsPoolConfig extends GenericObjectPoolConfig { public HdfsPoolConfig(){} /** * TestWhileConfig - 在空闲时检查有效性, 默认false * MinEvictableIdleTimeMillis - 逐出连接的最小空闲时间 * TimeBetweenEvictionRunsMillis - 逐出扫描的时间间隔(毫秒) 如果为负数则不运行逐出线程,默认-1 * NumTestsPerEvictionRun - 每次逐出检查时 逐出的最大数目 * */ public HdfsPoolConfig(boolean testWhileIdle, long minEvictableIdleTimeMillis, long timeBetweenEvictionRunsMillis, int numTestsPerEvictionRun){ this.setTestWhileIdle(testWhileIdle); this.setMinEvictableIdleTimeMillis(minEvictableIdleTimeMillis); this.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis); this.setNumTestsPerEvictionRun(numTestsPerEvictionRun); } }
package com.cmcc.datacenter.hdfs.client; import com.cmcc.datacenter.hdfs.config.HdfsPoolConfig; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Autowired; import java.util.List; public class HdfsClient { private Logger logger = LoggerFactory.getLogger(this.getClass()); private HdfsPool hdfsPool; @Autowired private HdfsPoolConfig hdfsPoolConfig; @Autowired private HdfsFactory hdfsFactory; public void init(){ hdfsPool = new HdfsPool(hdfsFactory,hdfsPoolConfig); } public void stop(){ hdfsPool.close(); } public long getPathSize(String path) throws Exception { Hdfs hdfs = null; try { hdfs = hdfsPool.borrowObject(); return hdfs.getContentSummary(path).getLength(); } catch (Exception e) { logger.error("[HDFS]获取路径大小失败", e); throw e; } finally { if (null != hdfs) { hdfsPool.returnObject(hdfs); } } } public List<String> getBasePath(){ Hdfs hdfs = null; try { hdfs = hdfsPool.borrowObject(); return hdfs.listFileName(); } catch (Exception e) { e.printStackTrace(); return null; }finally { if (null != hdfs) { hdfsPool.returnObject(hdfs); } } } }
import org.apache.commons.pool2.PooledObject; import org.apache.commons.pool2.PooledObjectFactory; import org.apache.commons.pool2.impl.DefaultPooledObject; import java.io.IOException; public class HdfsFactory implements PooledObjectFactory<Hdfs> { private final String url; public HdfsFactory(String url){ this.url = url; } @Override public PooledObject<Hdfs> makeObject() throws Exception { Hdfs hdfs = new Hdfs(url); hdfs.open(); return new DefaultPooledObject<Hdfs>(hdfs); } @Override public void destroyObject(PooledObject<Hdfs> pooledObject) throws Exception { Hdfs hdfs = pooledObject.getObject(); hdfs.close(); } @Override public boolean validateObject(PooledObject<Hdfs> pooledObject) { Hdfs hdfs = pooledObject.getObject(); try { return hdfs.isConnected(); } catch (IOException e) { e.printStackTrace(); return false; } } @Override public void activateObject(PooledObject<Hdfs> pooledObject) throws Exception { } @Override public void passivateObject(PooledObject<Hdfs> pooledObject) throws Exception { } }
package com.cmcc.datacenter.hdfs.client; import org.apache.commons.pool2.PooledObjectFactory; import org.apache.commons.pool2.impl.AbandonedConfig; import org.apache.commons.pool2.impl.GenericObjectPool; import org.apache.commons.pool2.impl.GenericObjectPoolConfig; public class HdfsPool extends GenericObjectPool<Hdfs> { public HdfsPool(PooledObjectFactory<Hdfs> factory) { super(factory); } public HdfsPool(PooledObjectFactory<Hdfs> factory, GenericObjectPoolConfig<Hdfs> config) { super(factory, config); } public HdfsPool(PooledObjectFactory<Hdfs> factory, GenericObjectPoolConfig<Hdfs> config, AbandonedConfig abandonedConfig) { super(factory, config, abandonedConfig); } }
import com.cmcc.datacenter.hdfs.config.HdfsConfig; import com.google.common.collect.Lists; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.ContentSummary; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Autowired; import java.io.IOException; import java.util.List; public class Hdfs { private Logger logger = LoggerFactory.getLogger(this.getClass()); private FileSystem fs; private String coreResource; private String hdfsResource; private final String url; private static final String NAME = "fs.hdfs.impl"; public Hdfs(String url) { this.url = url; } public void open() { try { Configuration conf = new Configuration(); conf.set("fs.defaultFS", url); System.out.println("url is "+url); fs = FileSystem.get(conf); logger.info("[Hadoop]创建实例成功"); } catch (Exception e) { logger.error("[Hadoop]创建实例失败", e); } } public void close() { try { if (null != fs) { fs.close(); logger.info("[Hadoop]关闭实例成功"); } } catch(Exception e) { logger.error("[Hadoop]关闭实例失败", e); } } public boolean isConnected() throws IOException { return fs.exists(new Path("/")); } public boolean exists(String path) throws IOException { Path hdfsPath = new Path(path); return fs.exists(hdfsPath); } public FileStatus getFileStatus(String path) throws IOException { Path hdfsPath = new Path(path); return fs.getFileStatus(hdfsPath); } public ContentSummary getContentSummary(String path) throws IOException { ContentSummary contentSummary = null; Path hdfsPath = new Path(path); if (fs.exists(hdfsPath)) { contentSummary = fs.getContentSummary(hdfsPath); } return contentSummary; } public List<String> listFileName() throws IOException { List<String> res = Lists.newArrayList(); FileStatus[] fileStatuses = fs.listStatus(new Path("/")); for (FileStatus fileStatus : fileStatuses){ res.add(fileStatus.getPath() +":类型--"+ (fileStatus.isDirectory()? "文件夹":"文件")); } return res; } }
四、总结:
一共六个类,理清思路看是很easy的。
这里就是spring对类的管理和commons-pool2对连接类的管理混着用了,所以显得有点乱。
1.@Configuration注解加到Hdfsconfig类上,作为一个配置类,作用类似于spring-xml文件中的<beans></beans>标签,springboot会扫描并注入它名下管理的类,其中
@Bean(initMethod = "init", destroyMethod = "stop") 标签表示spring在初始化这个类时调用他的init方法,销毁时调用他的stop方法。
2.HdfsClient 是业务方法调用的类,spring在初始化这个类时,调用它的init方法,这个方法会创建HdfsPool(即Hdfs的连接池)。其他方法是对Hdfs中方法的二次封装,即先使用连接池获取实例,再调用实例方法。
3.HdfsPoolConfig继承commons-pool2包中的GenericObjectConfig,受spring管理,作为线程池的配置类,创建HdfsPool时作为参数传入。
4.HdfsFactory继承commons-pool2包中的GenericObjectFactory,受spring管理,作为创建连接实例的工厂类,创建HdfsPool时作为参数传入。实际上连接池就是通过它获取的连接实例。
5.HdfsPool继承commons-pool2包中的GenericObjectPool,是连接池。
6.Hdfs,是底层的连接实例,所有增删改查的方法都要在这里实现,只不过获取/销毁连接交给池管理。
声明:这里用spring管理一些类是应为项目本身用的springboot,spring管理方便,并不是强制使用,愿意完全可以自己new。
五、不得不说的一些不是坑的坑。
1.我真的不记得windows上用Java API连接远程的hadoop还要有一些神操作。
报错如下:java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset
解决如下:
1. 将已下载的 hadoop-2.9.0.tar 这个压缩文件解压,放到你想要的位置(本机任意位置);
2. 下载 windows 环境下所需的其他文件(hadoop2.9.0对应的hadoop.dll,winutils.exe 等),这步真是关键,吐槽某SDN想钱想疯了啊,霸占百度前10页,各种下载各种C币,各种要钱。
不多说了,附上github地址:github地址
3. 拿到上面下载的windows所需文件,执行以下步骤:
3.1:将文件解压到你解压的 hadoop-2.9.0.tar 的bin目录下(没有的放进去,有的不要替换,以免花式作死,想学习尝试的除外)
3.2:将hadoop.dll复制到C:\Window\System32下
3.3:添加环境变量HADOOP_HOME,指向hadoop目录
3.4:将%HADOOP_HOME%\bin加入到path里面,不管用的话将%HADOOP_HOME%\sbin也加进去。
3.5:重启 IDE(你的编辑工具,例如eclipse,intellij idea)