本次抓包原因:
公司统一采用阿里云k8s和slb服务;node开发的kuaizimu在调用saas服务的时候,无法调用到saas的api接口,发现超时问题严重。问到其他团队调用saas服务的同事(公司的zishuo项目组和dupa项目组),均表示能正常访问saas服务,并无出现超时现象。
也就是说:saas服务一直能够稳健提供服务,网络也没有出问题。
排查了很久,开发和运维都咬定不是自己的问题;
开发说:我线下开发环境可以访问,到了线上就不行;无能为力。并表示代码从始至终为获取到saas的api接口数据
运维说:其他人的服务是正常的,就只有你的代码不能连接,肯定是你代码的问题,重新检查。
saas开发团队的同事提议:采用tcpdump抓包,看看中间的网络链路到哪里出了问题?运维同事表示赞同。于是开启tcpdump抓包的历程。
环境介绍:
公司统一采用阿里云k8s和slb向外提供服务;node和saas的服务都部署在k8s集群环境中。node端(kuaizimu-admin-gray.bhbapp.cn)访问saas服务(vpc-saas-pay-gray.bhbapp.cn)超时
node的ip为172.25.3.10
saas 的ip为172.25.3.192
公网SLB的ip为
内网SLB的ip为10.19.3.186
具体拓扑图如下: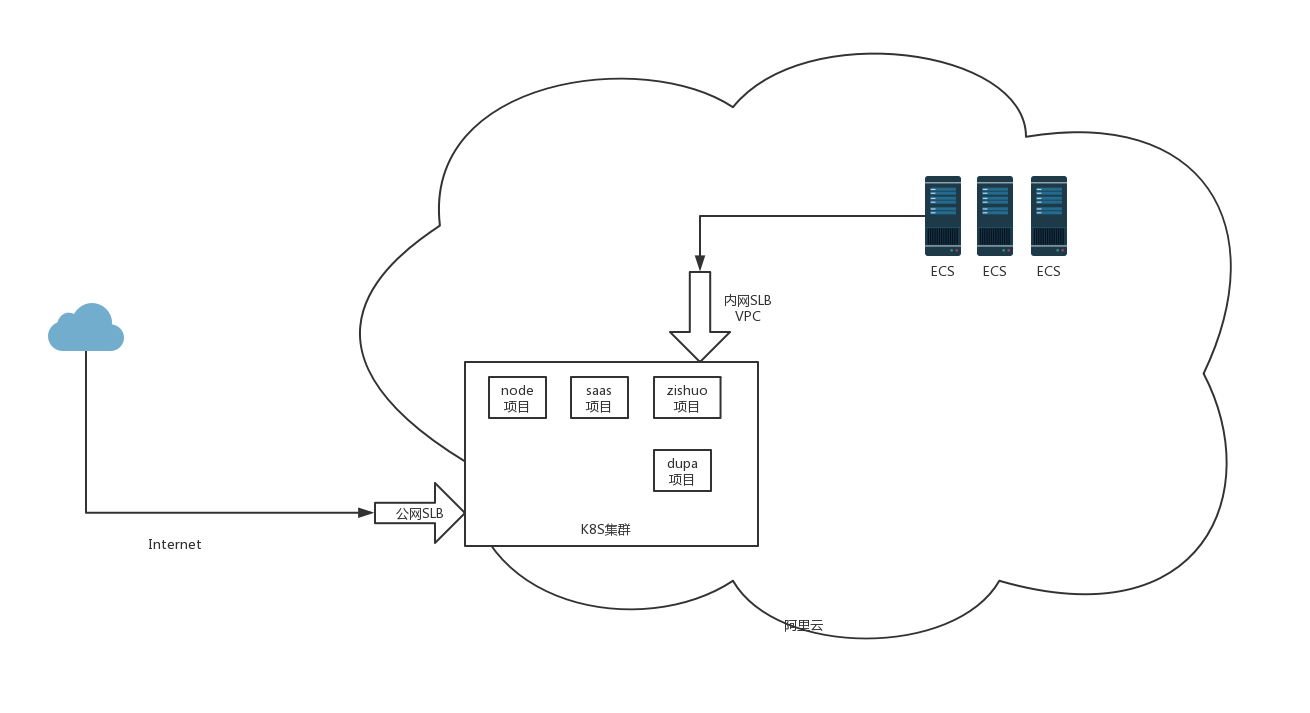
在node项目中安装tcpdump软件,对其进行抓包;获取到的数据如下:
安装wireshark,对抓取到的数据进行分析:如图
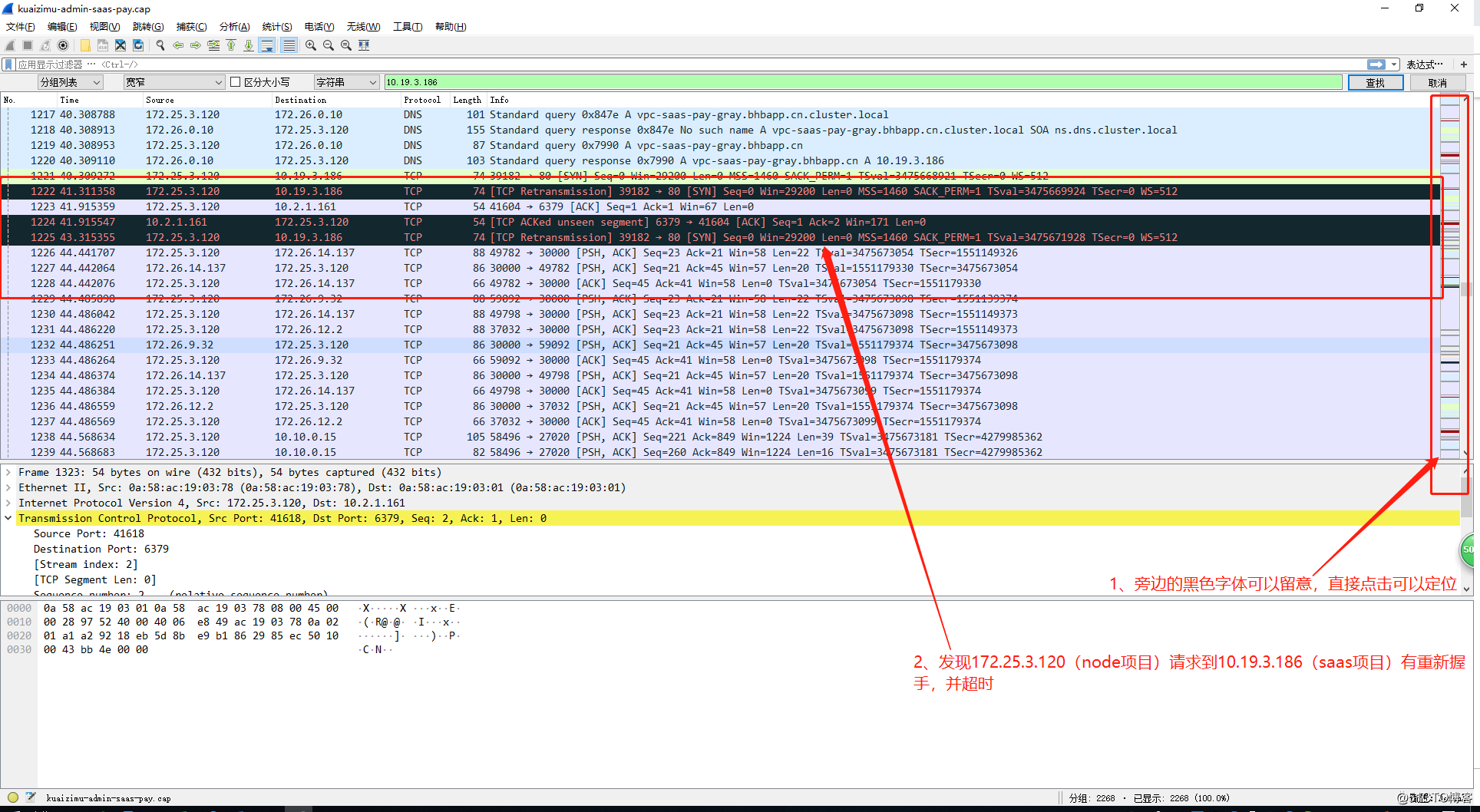
第一次抓包的时候发现node端在发起请求的时候有Retransmission重新发送的现象,怀疑是对端拒绝了这个请求。经过查证,对端的ip10.19.3.186为SLB的地址。
saas觉得证据仍旧不够,不太具备说服力,于是进行第二次抓包,同样是在node端进行抓包分析。发现这种现象重复发生,并且只要node端发出请求都会有相同的包被拒绝;开始怀疑是node端请求在经过slb的时候被拒绝,而saas一直没收到过node端请求。
抓包到这里引发了两个猜想:
一:是slb出了问题?还是k8s不支持这种slb的解析方式?总之slb和k8s肯定有一方出现问题。
二:为什么node端的域名解析会经过slb呢?按道理来说k8s本身就剧本解析能力不需经过k8s集群外面的slb
为了验证猜想:开始了两步工作:
1、 提交1个SLB工单,看看是不是阿里云的slb出现问题,想查询slb的访问日志
2、 提交1个k8s工单,看看有没有更好的解析方式
果然,阿里云工作人员回答说:k8s集群内容器之间的服务调用,可以直接走k8s集群内网解析,不需要经过外部的slb。在容器内尝试连接容器的servicename,方案可行。
这里就可能是node端连接的域名出现问题,询问zishuo项目和dupa项目的同事,发现他们访问的域名果然和node端不一致;分别为公网域名和k8s内网域名。验证了之前的猜想。
解决了问题,并解答出之前的访问超时的原因:
k8s集群内容器之间的服务调用,域名统一使用 "项目名.命名空间.svc.cluster.local" ;这个仅在k8s集群内解析。
外网之间调用k8s服务,直接使用公网的域名即可
注:
k8s集群内的容器之间的服务调用 不能走ECS的vpc网络,这种情况集群会把slb的ip当着是service的ip就进行转发。
总结:
node端修改了连接地址之后,恢复正常访问。建议:以后容器之间的调用地址直接使用k8s内网域名即可。