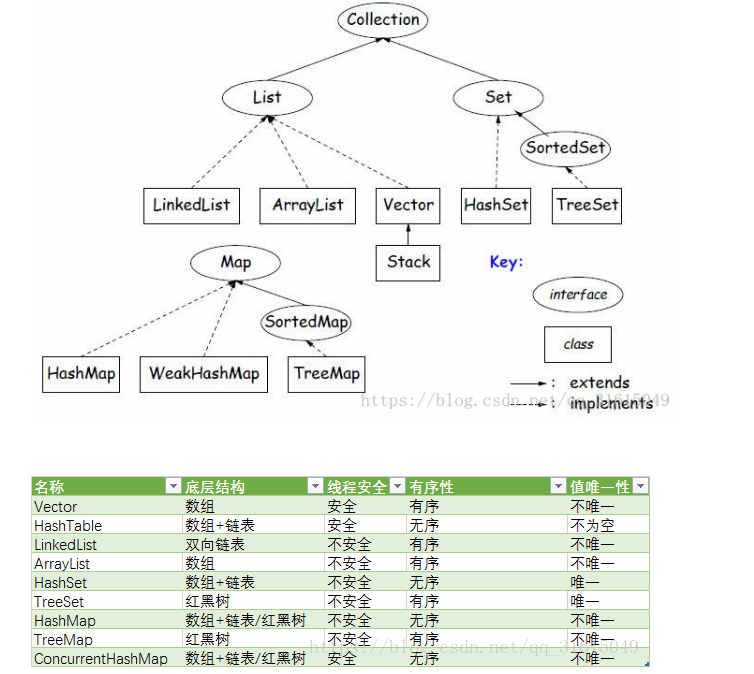
java中有几种常用的数据结构,主要分为Collection和map两个主要接口(接口只提供方法,并不提供实现),而程序中最终使用的数据结构是继承自这些接口的数据结构类。
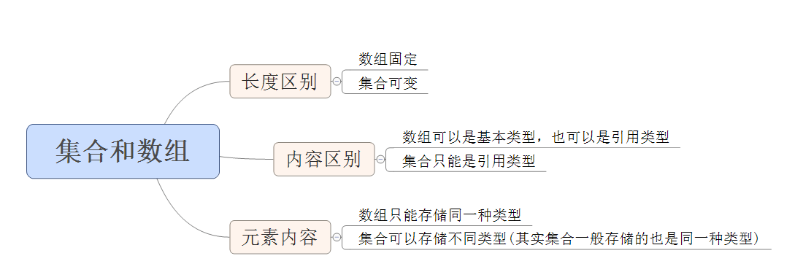
一、集合和数组的区别
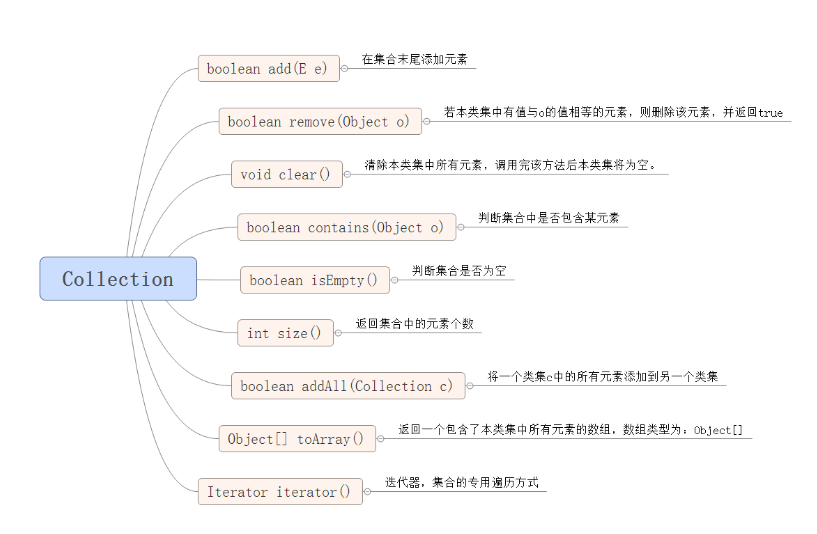
二、Collection集合和Map集合

三、Collection接口
1、定义
public interface Collection<E> extends Iterable<E> {}
它是一个接口,是高度抽象出来的集合,它包含了集合的基本操作:添加、删除、清空、遍历(读取)、是否为空、获取大小、是否保护某元素等等。
Collection接口的所有子类(直接子类和间接子类)都必须实现2种构造函数:不带参数的构造函数 和 参数为Collection的构造函数。带参数的构造函数,可以用来转换Collection的类型。
2、Collection集合的API
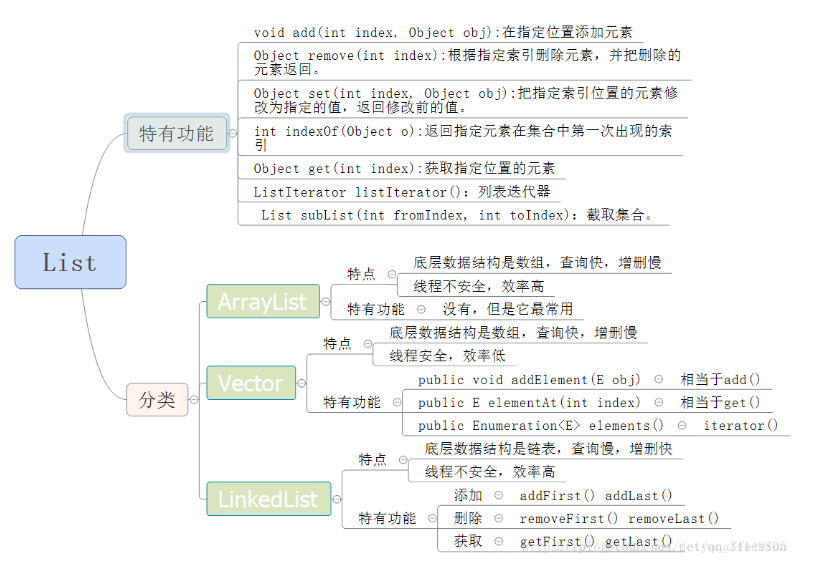
四、List
1、定义:
List是一个继承于Collection的接口,即List是集合中的一种。List是有序的队列,List中的每一个元素都有一个索引;第一个元素的索引值是0,往后的元素的索引值依次+1。和Set不同,List中允许有重复的元素。
public interface List<E> extends Collection<E> {}
2、List接口的实现类
(1)ArrayList:底层数据结构是数组,查询快,增删慢,线程不安全,效率高,可以存储重复元素
(2)LinkedList 底层数据结构是链表,查询慢,增删快,线程不安全,效率高,可以存储重复元素
(3)Vector:底层数据结构是数组,查询快,增删慢,线程安全,效率低,可以存储重复元素
3、List接口的方法:既然List是继承于Collection接口,它自然就包含了Collection中的全部函数接口;由于List是有序队列,它也额外的有自己的API接口。
Arraylist:
优点:ArrayList是实现了基于动态数组的数据结构,因为地址连续,一旦数据存储好了,查询操作效率会比较高(在内存里是连着放的)。
缺点:因为地址连续, ArrayList要移动数据,所以插入和删除操作效率比较低。
LinkedList:
优点:LinkedList基于链表的数据结构,地址是任意的,所以在开辟内存空间的时候不需要等一个连续的地址,对于新增和删除操作add和remove,LinedList比较占优势。LinkedList 适用于要头尾操作或插入指定位置的场景
缺点:因为LinkedList要移动指针,所以查询操作性能比较低。
适用场景分析:
当需要对数据进行对此访问的情况下选用ArrayList,当需要对数据进行多次增加删除修改时采用LinkedList。
五、Set集合
1、定义:Set是一个继承于Collection的接口,即Set也是集合中的一种。Set是没有重复元素的集合。
public interface Set<E> extends Collection<E> {}
2、Set的API和Collection完全一样。
// Set的API abstract boolean add(E object) abstract boolean addAll(Collection<? extends E> collection) abstract void clear() abstract boolean contains(Object object) abstract boolean containsAll(Collection<?> collection) abstract boolean equals(Object object) abstract int hashCode() abstract boolean isEmpty() abstract Iterator<E> iterator() abstract boolean remove(Object object) abstract boolean removeAll(Collection<?> collection) abstract boolean retainAll(Collection<?> collection) abstract int size() abstract <T> T[] toArray(T[] array) abstract Object[] toArray()
3、实现子类
(1)HashSet : 底层数据结构采用哈希表实现,元素无序且唯一,线程不安全,效率高,可以存储null元素,元素的唯一性是靠所存储元素类型是否重写hashCode()和equals()方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性。
a、实现唯一性:
存储元素首先会使用hash()算法函数生成一个int类型hashCode散列值,然后已经的所存储的元素的hashCode值比较,如果hashCode不相等,则所存储的两个对象一定不相等,此时存储当前的新的hashCode值处的元素对象;如果hashCode相等,存储元素的对象还是不一定相等,此时会调用equals()方法判断两个对象的内容是否相等,如果内容相等,那么就是同一个对象,无需存储;如果比较的内容不相等,那么就是不同的对象,就该存储了,此时就要采用哈希的解决地址冲突算法,在当前hashCode值处类似一个新的链表, 在同一个hashCode值的后面存储存储不同的对象,这样就保证了元素的唯一性。
b、实现不重复
HashSet也一样他是使用了一种标识来确定元素的不重复,HashSet用一种算法来保证HashSet中的元素是不重复的, HashSet采用哈希算法,底层用数组存储数据。默认初始化容量16,加载因子0.75。
Object类中的hashCode()的方法是所有子类都会继承这个方法,这个方法会用Hash算法算出一个Hash(哈希)码值返回,HashSet会用Hash码值去和数组长度取模, 模(这个模就是对象要存放在数组中的位置)相同时才会判断数组中的元素和要加入的对象的内容是否相同,如果不同才会添加进去。

覆盖hashCode()方法的原则:
1、一定要让那些我们认为相同的对象返回相同的hashCode值
2、尽量让那些我们认为不同的对象返回不同的hashCode值,否则,就会增加冲突的概率。
3、尽量的让hashCode值散列开(两值用异或运算可使结果的范围更广)
c、HashSet的实现
HashSet 的实现比较简单,相关HashSet的操作,基本上都是直接调用底层HashMap的相关方法来完成,我们应该为保存到HashSet中的对象覆盖hashCode()和equals(),因为再将对象加入到HashSet中时:
首先调用hashCode方法计算出对象的hash值,接着根据此hash值调用HashMap中的hash方法,得到的值& (length-1)得到该对象在hashMap的transient Entry[] table中的保存位置的索引,接着找到数组中该索引位置保存的对象,并调用equals方法比较这两个对象是否相等,如果相等则不添加;
注意:所以要存入HashSet的集合对象中的自定义类必须覆盖hashCode(),equals()两个方法,才能保证集合中元素不重复。在覆盖equals()和hashCode()方法时, 要使相同对象的hashCode()方法返回相同值,覆盖equals()方法再判断其内容。为了保证效率,所以在覆盖hashCode()方法时,也要尽量使不同对象尽量返回不同的Hash码值。
(2)、LinkedHashSet底层数据结构采用链表和哈希表共同实现,链表保证了元素的顺序与存储顺序一致,哈希表保证了元素的唯一性。线程不安全,效率高。
(3)、TreeSet底层数据结构采用二叉树来实现,元素唯一且已经排好序;唯一性同样需要重写hashCode和equals()方法,二叉树结构保证了元素的有序性。根据构造方法不同,分为自然排序(无参构造)和比较器排序(有参构造)。
自然排序要求元素必须实现Compareable接口,并重写里面的compareTo()方法,元素通过比较返回的int值来判断排序序列,返回0说明两个对象相同,不需要存储;
比较器排需要在TreeSet初始化是时候传入一个实现Comparator接口的比较器对象,或者采用匿名内部类的方式new一个Comparator对象,重写里面的compare()方法;
比较:
1、TreeSet 是二叉树(红黑树的树据结构)实现的,Treeset中的数据是自动排好序的,不允许放入null值;
2、HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束 ;
3、HashSet要求放入的对象必须实现HashCode()方法,放入的对象,是以hashcode码作为标识的,而具有相同内容的String对象,hashcode是一样,所以放入的内容不能重复。但是同一个类的对象可以放入不同的实例;
适用场景分析:HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。为快速查找而设计的Set,我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
六、List和Set的比较
(1)、List,Set都是继承自Collection接口;
(2)、List特点:元素有放入顺序,元素可重复 ;Set特点:元素无放入顺序,元素不可重复,重复元素会覆盖掉;
(3)、Set:检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变。
原文:https://blog.csdn.net/feiyanaffection/article/details/81394745
http://www.cnblogs.com/skywang12345/p/3308513.html