一、故障转移
redis集群实现了高可用,当集群内少量节点出现故障时,通过故障转移可以保证集群正常对外提供服务。
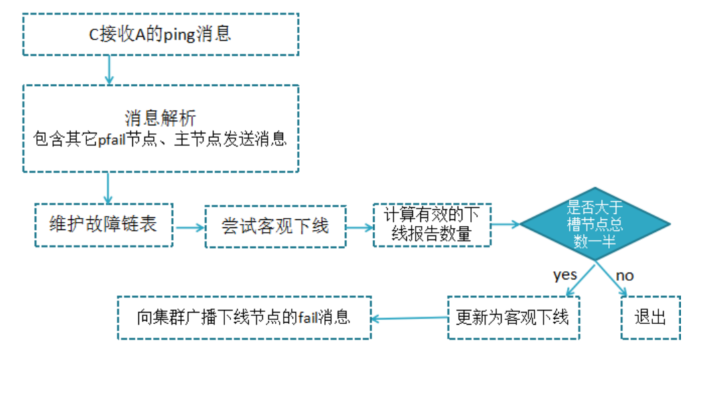
当集群里某个节点出现了问题,redis集群内的节点通过ping pong消息发现节点是否健康,是否有故障,其实主要环节也包括了 主观下线和客观下线;
主观下线:指某个节点认为另一个节点不可用,即下线状态,当然这个状态不是最终的故障判定,只能代表这个节点自身的意见,也有可能存在误判;

下线流程:
A,节点a发送ping消息给节点b ,如果通信正常将接收到pong消息,节点a更新最近一次与节点b的通信时间;
B,如果节点a与节点b通信出现问题则断开连接,下次会进行重连,如果一直通信失败,则它们的最后通信时间将无法更新;
节点a内的定时任务检测到与节点b最后通信时间超过cluster_note-timeout时,更新本地对节点b的状态为主观下线(pfail)
客观下线:指真正的下线,集群内多个节点都认为该节点不可用,达成共识,将它下线,如果下线的节点为主节点,还要对它进行故障转移
假如节点a标记节点b为主观下线,一段时间后节点a通过消息把节点b的状态发到其它节点,当节点c接受到消息并解析出消息体时,会发现节点b的pfail状态时,会触发客观下线流程;
当下线为主节点时,此时redis集群为统计持有槽的主节点投票数是否达到一半,当下线报告统计数大于一半时,被标记为客观下线状态。
故障恢复:
故障主节点下线后,如果下线节点的是主节点,则需要在它的从节点中选一个替换它,保证集群的高可用;转移过程如下:
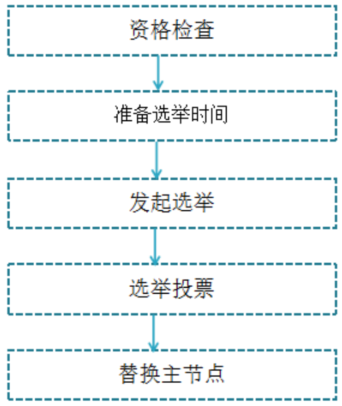
1,资格检查:检查该从节点是否有资格替换故障主节点,如果此从节点与主节点断开过通信,那么当前从节点不具体故障转移;
2,准备选举时间:当从节点符合故障转移资格后,更新触发故障选举时间,只有到达该时间后才能执行后续流程;
3,发起选举:当到达故障选举时间时,进行选举;
4,选举投票:只有持有槽的主节点才有票,会处理故障选举消息,投票过程其实是一个领导者选举(选举从节点为领导者)的过程,每个主节点只能投一张票给从节点,当从节点收集到足够的选票(大于N/2+1)后,触发替换主节点操作,撤销原故障主节点的槽,委派给自己,并广播自己的委派消息,通知集群内所有节点。
(1)选举过程是集群中所有master参与,如果半数以上master节点与master节点通信超过(cluster-node-timeout),认为当前master节点挂掉.
(2):什么时候整个集群不可用(cluster_state:fail),当集群不可用时,所有对集群的操作做都不可用,收到((error) CLUSTERDOWN The cluster is down)错误
a:如果集群任意master挂掉,且当前master没有slave.集群进入fail状态,也可以理解成进群的slot映射[0-16383]不完整时进入fail状态.
b:如果集群中超过半数以上master挂掉,无论是否有slave,集群进入fail状态.
测试:
6个节点:7000,7001,7002,7003,7004,7005
登录任意个节点查看主从关系:./redis-cli -a 123456 -p 7000 -h 192.168.184.133
首先介绍cluster nodes命令的输出含义:
- 节点ID
- IP:端口
- 标志: master, slave, myself, fail, …
- 如果是个从节点, 这里是它的主节点的NODE ID
- 集群最近一次向节点发送 PING 命令之后, 过去了多长时间还没接到回复。.
- 节点最近一次返回 PONG 回复的时间。
- 节点的配置纪元(configuration epoch):详细信息请参考 Redis 集群规范 。
- 本节点的网络连接情况:例如 connected 。
- 节点目前包含的槽:例如 127.0.0.1:7001 目前包含号码为 5960 至 10921 的哈希槽。
登录之后输入:cluster nodes,查看节点关系如图

Master:7000,7001,7002,Slave:7003,7004,7005
主从关系为如图:

主从对应关系为:M7000-S7003,M7001-S7004,M7002-S7005
恰好7000是主节点,然后我们可以通过向端口号为7002 的主节点发送 DEBUG SEGFAULT 命令, 让这个主节点崩溃:
![]()
Redis 使用的是异步复制, 在执行故障转移期间, 集群可能会丢失写命令。但是在实际上, 丢失命令的情况并不常见, 因为 Redis 几乎是同时执行将命令回复发送给客户端, 以及将命令复制给从节点这两个操作, 所以实际上造成命令丢失的时间窗口是非常小的。不过, 尽管出现的几率不高, 但丢失命令的情况还是有可能会出现的, 所以我们对 Redis 集群不能提供强一致性的这一描述仍然是正确的。现在, 让我们使用 cluster nodes 命令,查看集群在执行故障转移操作之后, 主从节点的布局情况:
可以看出7003拥有了7000的哈希槽,成为了主节点,集群处于正常状态

重新启动7000,之后会变成从挂在7003上

把S7000,M7003都停止,在测试集群可用性

可以看到哈希槽不完整了,集群不能进行操作了。
重新启动所有节点,停止两个主节点

登录M7001查看节点状态

看到M7002,M7003,状态为fail?主观下线,集群中主节点剩余1个懵逼了,没办法选举了。
二、手动故障转移
有的时候在主节点没有任何问题的情况下强制手动故障转移也是很有必要的,比如想要升级主节点的Redis进程,我们可以通过故障转移将其转为slave再进行升级操作来避免对集群的可用性造成很大的影响。
Redis集群使用 CLUSTER FAILOVER命令来进行故障转移,不过要被转移的主节点的从节点上执行该命令 手动故障转移比主节点失败自动故障转移更加安全,因为手动故障转移时客户端的切换是在确保新的主节点完全复制了失败的旧的主节点数据的前提下下发生的,所以避免了数据的丢失。
Redis集群提供了手动故障转移功能,指定从节点发起转移,主从节点角色进行互换,过程如下:
1. 从节点通知主节点停止处理所有客户端请求。
2. 主节点发送对应从节点延迟复制的数据。
3. 从节点接收复制延迟的数据,直到主从复制偏移量一致。
4. 从节点立刻发起投票选举,选举成功后断开复制变为新的主节点,之后向集群广播。
5. 原主节点接收消息后更新自身配置变为从节点,解除所有客户端请求阻塞,重定向到新的主节点。
6. 原主节点变为从节点后,向新的主节点发起全量复制请求(Redis4.0版本这一过程会有改善)。
主从关系为:

此时7000为从,7003为主,切换他们两个的关系
登录从节点执行:
可以看到7000,7003关系已经切换了关系
7000从服务日志:
5216:S 13 Apr 00:23:33.894 # Manual failover user request accepted.
5216:S 13 Apr 00:23:33.950 # Received replication offset for paused master manual failover: 20623
5216:S 13 Apr 00:23:33.950 # All master replication stream processed, manual failover can start.
5216:S 13 Apr 00:23:33.950 # Start of election delayed for 0 milliseconds (rank #0, offset 20623).
5216:S 13 Apr 00:23:34.051 # Starting a failover election for epoch 8.
5216:S 13 Apr 00:23:34.067 # Failover election won: I'm the new master.
5216:S 13 Apr 00:23:34.067 # configEpoch set to 8 after successful failover
5216:M 13 Apr 00:23:34.067 # Connection with master lost.
5216:M 13 Apr 00:23:34.067 * Caching the disconnected master state.
5216:M 13 Apr 00:23:34.067 * Discarding previously cached master state.
5216:M 13 Apr 00:23:34.758 * Slave 127.0.0.1:7003 asks for synchronization
5216:M 13 Apr 00:23:34.758 * Full resync requested by slave 127.0.0.1:7003
5216:M 13 Apr 00:23:34.758 * Starting BGSAVE for SYNC with target: disk
5216:M 13 Apr 00:23:34.759 * Background saving started by pid 5886
5886:C 13 Apr 00:23:34.860 * DB saved on disk
5886:C 13 Apr 00:23:34.860 * RDB: 6 MB of memory used by copy-on-write
5216:M 13 Apr 00:23:34.960 * Background saving terminated with success
5216:M 13 Apr 00:23:34.960 * Synchronization with slave 127.0.0.1:7003 succeeded
7003主服务日志:
5420:M 13 Apr 00:23:33.895 # Manual failover requested by slave 4ab88c98aa195010cd0071917dfebd6f71b4ec88.
5420:M 13 Apr 00:23:34.066 # Failover auth granted to 4ab88c98aa195010cd0071917dfebd6f71b4ec88 for epoch 8
5420:M 13 Apr 00:23:34.068 # Connection with slave 127.0.0.1:7000 lost.
5420:M 13 Apr 00:23:34.069 # Configuration change detected. Reconfiguring myself as a replica of 4ab88c98aa195010cd0071917dfebd6f71b4ec88
5420:S 13 Apr 00:23:34.757 * Connecting to MASTER 127.0.0.1:7000
5420:S 13 Apr 00:23:34.757 * MASTER <-> SLAVE sync started
5420:S 13 Apr 00:23:34.757 * Non blocking connect for SYNC fired the event.
5420:S 13 Apr 00:23:34.758 * Master replied to PING, replication can continue...
5420:S 13 Apr 00:23:34.758 * Partial resynchronization not possible (no cached master)
5420:S 13 Apr 00:23:34.761 * Full resync from master: e7cf4ecfdcba75625f9925c789082121ef95a4ff:20624
5420:S 13 Apr 00:23:34.960 * MASTER <-> SLAVE sync: receiving 94 bytes from master
5420:S 13 Apr 00:23:34.961 * MASTER <-> SLAVE sync: Flushing old data
5420:S 13 Apr 00:23:34.961 * MASTER <-> SLAVE sync: Loading DB in memory
5420:S 13 Apr 00:23:34.961 * MASTER <-> SLAVE sync: Finished with success
Redis集群还提供了强制故障转移的方法:
1. cluster failover force - 用于主节点宕机且无法自动完成故障转移的情况。
2. cluster failover takeover - 用于集群内一半以上主节点故障的场景,从节点无法收到半数以上主节点投票,无法完成选举过程(慎用)。
三、添加一个新节点
添加新的节点的基本过程就是添加一个空的节点然后移动一些数据给它,有两种情况,添加一个主节点和添加一个从节点(添加从节点时需要将这个新的节点设置为集群中某个节点的复制)
针对这两种情况,本节都会介绍,先从添加主节点开始.
两种情况第一步都是要添加 一个空的节点.
启动新的7006节点,使用的配置文件和以前的一样,只要把端口号改一下即可,过程如下:
include /usr/local/cluster-test/redis-3.2.9/redis.conf
port 7006
pidfile /usr/local/cluster-test/other/redis_7006.pid
logfile /usr/local/cluster-test/other/7006.logdb
dbfilename dump_7006.rdb
dir /usr/local/cluster-test/other
cluster-enabled yes
cluster-config-file nodes_7006.conf
cluster-node-timeout 5000
appendonly no
配置好redis7006.conf,启动7006redis服务。
接下来使用redis-trib 来添加这个节点到现有的集群中去.
/redis-trib.rb add-node 127.0.0.1:7006 127.0.0.1:7003
可以看到.使用addnode命令来添加节点,第一个参数是新节点的地址,第二个参数是任意一个已经存在的节点的IP和端口. 我们可以看到新的节点已经添加到集群中:

新节点现在已经连接上了集群, 成为集群的一份子, 并且可以对客户端的命令请求进行转向了, 但是和其他主节点相比, 新节点还有两点区别:
- 新节点没有包含任何数据, 因为它没有包含任何哈希槽.
- 尽管新节点没有包含任何哈希槽, 但它仍然是一个主节点, 所以在集群需要将某个从节点升级为新的主节点时, 这个新节点不会被选中。
接下来, 只要使用 redis-trib 程序, 将集群中的某些哈希桶移动到新节点里面, 新节点就会成为真正的主节点了。
我们手动对集群进行重新分片迁移数据,需要重新分片命令 reshard
./redis-trib.rb reshard 127.0.0.1:7005这个命令是用来迁移slot节点的,后面的127.0.0.1:7005是表示是哪个集群,端口填[7000-7006]都可以,执行结果如下
[root@localhost src]# ./redis-trib.rb reshard 127.0.0.1:7005
>>> Performing Cluster Check (using node 127.0.0.1:7005)
S: f2051513233ec90ab2a43b524be96c5bd76d5343 127.0.0.1:7005
slots: (0 slots) slave
replicates 2c6ac31724d44419059b210d3a6f8cfff5d2be2b
M: 1050255c230dc7e3019aedd827bc6ce8f0342ce2 127.0.0.1:7001
slots:5461-10922 (5462 slots) master
1 additional replica(s)
M: 2c6ac31724d44419059b210d3a6f8cfff5d2be2b 127.0.0.1:7002
slots:10923-16383 (5461 slots) master
1 additional replica(s)
S: ce79838eecf8fe7d950e859b5f466ab314b5c8c3 127.0.0.1:7003
slots: (0 slots) slave
replicates 4ab88c98aa195010cd0071917dfebd6f71b4ec88
S: 1c6f9f89a7fcb003909d1792d5209137314cc08c 127.0.0.1:7004
slots: (0 slots) slave
replicates 1050255c230dc7e3019aedd827bc6ce8f0342ce2
M: 4ab88c98aa195010cd0071917dfebd6f71b4ec88 127.0.0.1:7000
slots:0-5460 (5461 slots) master
1 additional replica(s)
M: a4a0949421f1a34cf0eea51f1d719600c3b72a04 127.0.0.1:7006
slots: (0 slots) master
0 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 4096
What is the receiving node ID? a4a0949421f1a34cf0eea51f1d719600c3b72a04
它提示我们需要迁移多少slot到7006上,我们平分16384个哈希槽给4个节点:16384/4 = 4096,我们需要移动4096个槽点到7006上。
How many slots do you want to move (from 1 to 16384)? 4096
What is the receiving node ID? a4a0949421f1a34cf0eea51f1d719600c3b72a04
你想移动多少slots ,哪个id节点,填写新增加的7006节点
接下来会显示:
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:all
redis-trib 会向你询问重新分片的源节点(source node),即,要从特点的哪个节点中取出 4096 个哈希槽,还是从全部节点提取4096个哈希槽, 并将这些槽移动到7006节点上面。
如果我们不打算从特定的节点上取出指定数量的哈希槽,那么可以向redis-trib输入 all,这样的话, 集群中的所有主节点都会成为源节点,redis-trib从各个源节点中各取出一部分哈希槽,凑够4096个,然后移动到7006节点上:
然后开始从别的主节点迁移哈希槽,并且确认。
...
...
Moving slot 1353 from 4ab88c98aa195010cd0071917dfebd6f71b4ec88
Moving slot 1354 from 4ab88c98aa195010cd0071917dfebd6f71b4ec88
Moving slot 1355 from 4ab88c98aa195010cd0071917dfebd6f71b4ec88
Moving slot 1356 from 4ab88c98aa195010cd0071917dfebd6f71b4ec88
Moving slot 1357 from 4ab88c98aa195010cd0071917dfebd6f71b4ec88
Moving slot 1358 from 4ab88c98aa195010cd0071917dfebd6f71b4ec88
Moving slot 1359 from 4ab88c98aa195010cd0071917dfebd6f71b4ec88
Moving slot 1360 from 4ab88c98aa195010cd0071917dfebd6f71b4ec88
Moving slot 1361 from 4ab88c98aa195010cd0071917dfebd6f71b4ec88
Moving slot 1362 from 4ab88c98aa195010cd0071917dfebd6f71b4ec88
Moving slot 1363 from 4ab88c98aa195010cd0071917dfebd6f71b4ec88
Moving slot 1364 from 4ab88c98aa195010cd0071917dfebd6f71b4ec88
Do you want to proceed with the proposed reshard plan (yes/no)?yes
确认之后,redis-trib就开始执行分片操作,将哈希槽一个一个从源主节点移动到7006目标主节点。
重新分片结束后我们可以check以下节点的分配情况。
[root@localhost src]# ./redis-trib.rb check 127.0.0.1:7000
>>> Performing Cluster Check (using node 127.0.0.1:7000)
M: a8eee95a413111a5827793cb420711573fb04108 127.0.0.1:7000
slots:1365-5460 (4096 slots) master
1 additional replica(s)
M: 30be654f93d2ada781e544f0657e58514e4f5aca 127.0.0.1:7006
slots:0-1364,5461-6826,10923-12287 (4096 slots) master
0 additional replica(s)
S: d423ddd4e062f9087f8601c476495bd2d68a689a 127.0.0.1:7004
slots: (0 slots) slave
replicates 07a1b0791de5de3fa0dac55b17cac8ae016f7af8
S: 4a7d97883bdca79346aeb1684bf41c48ad21e22f 127.0.0.1:7003
slots: (0 slots) slave
replicates a8eee95a413111a5827793cb420711573fb04108
S: c95476559267ba6b164fc22815ce062f485962c8 127.0.0.1:7005
slots: (0 slots) slave
replicates 43c19173e00e32d2c86723de1a39e19d8ee47189
M: 07a1b0791de5de3fa0dac55b17cac8ae016f7af8 127.0.0.1:7001
slots:6827-10922 (4096 slots) master
1 additional replica(s)
M: 43c19173e00e32d2c86723de1a39e19d8ee47189 127.0.0.1:7002
slots:12288-16383 (4096 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
可以看到7006的的hash slots不是连续的,从其他三个主节点上移动过来的。
四、添加一个从节点
有两种方法添加从节点,可以像添加主节点一样使用redis-trib 命令,也可以像下面的例子一样使用 –slave选项:
./redis-trib.rb add-node --slave 127.0.0.1:7006 127.0.0.1:7000此处的命令和添加一个主节点命令类似,此处并没有指定添加的这个从节点的主节点,这种情况下系统会在其他的复制集中的主节点中随机选取一个作为这个从节点的主节点。
你可以通过下面的命令指定主节点:
./redis-trib.rb add-node --slave --master-id 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e 127.0.0.1:7006 127.0.0.1:7000也可以使用CLUSTER REPLICATE 命令添加.这个命令也可以改变一个从节点的主节点。
例如,要给主节点 127.0.0.1:7005添加一个从节点,该节点哈希槽的范围1423-16383, 节点 ID 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e,我们需要链接新的节点(已经是空的主节点)并执行命令:
redis 127.0.0.1:7006> cluster replicate 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e我们新的从节点有了一些哈希槽,其他的节点也知道(过几秒后会更新他们自己的配置),可以使用如下命令确认:
$ redis-cli -p 7000 cluster nodes | grep slave | grep 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e
f093c80dde814da99c5cf72a7dd01590792b783b 127.0.0.1:7006 slave 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e 0 1385543617702 3 connected
2938205e12de373867bf38f1ca29d31d0ddb3e46 127.0.0.1:7002 slave 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e 0 1385543617198 3 connected节点 3c3a0c… 有两个从节点, 7002 (已经存在的) 和 7006 (新添加的).
五、移除一个节点
只要使用 del-node 命令即可:
./redis-trib del-node 127.0.0.1:7000 `<node-id>`第一个参数是任意一个节点的地址,第二个节点是你想要移除的节点地址。
使用同样的方法移除主节点,不过在移除主节点前,需要确保这个主节点是空的. 如果不是空的,需要将这个节点的数据重新分片到其他主节点上.
替代移除主节点的方法是手动执行故障恢复,被移除的主节点会作为一个从节点存在,不过这种情况下不会减少集群节点的数量,也需要重新分片数据.
六、从节点的迁移
在Redis集群中会存在改变一个从节点的主节点的情况,需要执行如下命令 :
CLUSTER REPLICATE <master-node-id>在特定的场景下,不需要系统管理员的协助下,自动将一个从节点从当前的主节点切换到另一个主节 的自动重新配置的过程叫做复制迁移(从节点迁移),从节点的迁移能够提高整个Redis集群的可用性.
你可以阅读(Redis集群规范)/topics/cluster-spec了解细节.
简短的概况一下从节点迁移
- 集群会在有从节点数量最多的主节点上进行从节点的迁移.
- 要在一个主节点上添加多个从节点.
- 参数来控制从节点迁移 replica-migration-barrier:你可以仔细阅读redis.conf 。
参考: