分布式架构 Redis优化及高可用
优化说明:
Redis底层通讯协议对管道提供了支持,通过管道可以一次性发送多条命令,执行完后一次性将结果取回
Redis管道API命令中未体现、但支持管道
优化方案
- 1.精简键名和检键值
- 2.合理设计存储数据结构和数据关系,减少数据冗余
- 3.使用mset来赋值、高于set效率,类似 lpush、zadd等批量
- 4.如果条件允许,尽量使用LUA脚本来辅助获取和操作数据(LUA脚本所有指令一次性完成,效率高),如条件删除
- 5.hash结构来存储对象,占用少内存(zipmap存储数据值)
- 6.设置maxmemory 最大物理内存,使用了配置物理内存后开始拒接后续请求
- 7.数据采用RDB方式进行数据持久化备份,建议只在Slave上进行RDB持久化,而且较长的时间备份一次就好,(如20分钟保存一次 避免AOF带来继续IO操作,也避免了AOF
Rewrite最后将rewrite过程中产生的新数据写到新文件造成的阻塞,当然极端情况如果M/S同时挂了,可能会损失20分钟的数据) - 8.考虑在一台服务器启动多个Redis实例、充分利用CPU调度资源(但会带来严重的IO竞争,设置错开重写AOF)
高可用说明:
Redis单节点存在宕机的风险,为了解决这种风险,需要针对其进行高可用方案,
为了达到高效状态使其单台宕机情况下,业务正常运转
高可用方案如下
- 1.Redis复制
- 2.Redis集群 (version >=3.0)
复制描述
Redis支持复制功能,实现当一台服务器数据更新后,自动将新数据同步到另一台服务器,可以做Master主节点用于读写、Slave从节点用于读
复制的优势
- 1.实现读写分离
- 2.利于主服务器崩溃后数据恢复
复制开启过程:
从数据库redis.conf需开启“saveof 主服务器ip 主服务器端口” (saveof 127.0.0.1 6379)
通过info replication : 查看复制节点信息
slave-read-only 设置redis只读
slave-serve-stale-data 设置yes,用于响应主从同步期间,新的请求结果
repl-ping-slave-period 设置从节点向主节点报告心跳,默认10s
repl-timeout 设置主动超时时间
复制特性
- 如1主1丛部署结构 期间master出现问题,slave节点可以动态指向新的主节点服务器
从服务器运行 slaveof 可支持运行期间修改slave节点同步信息,(如 saveof 127.0.0.1 6390 ,从节点断掉和6379主从关系转向指定新的服务器) - 如1主1丛部署结构 期间master宕机,从服务器可以升级为主服务器
从服务器运行 slaveof no one,自动升级为主服务器
监控工具(哨兵)
实现原理:当主服务器宕机后,多个从服务中投票选举1个用于充当主服务器,选举轮次可能存在失败,多次选举最终达到成功状态
用途:监控主从服务器运行是否正常,当主服务器出现异常,自动将从服务器升级为主数据库
开启:
建立setinal.conf文件,设置要监控的服务器清单
setinal monitor redis主名称 地址 端口 1(选举参数)
/usr/local/bin/redis-setinal setinal.conf
Redis拆分数据过程
当一台Redis服务器存储的数据量过大,首先会采用垂直数据拆分,举例如下:
RedisA 存在(用户、产品、订单)数据,拆分成,RedisA、RedisB、RedisC分别存放 用户、产品、订单数据
针对RedisA、RedisB、RedisC还可以进行父子Master-Slave方式进行扩展
假如其配置是32G,按照5K条数据1M,保守估计可存储2-3亿数据
复制会存在问题及处理
复制中Redis每个数据库节点都拥有完整的数据,复制的总数据量受限于内存最小的数据库节点
由于复制数据量过大, 已经超过了复制的数据库内存最小的数据库节点的物理内存,复制过程就失败了
Redis集群
官网提供集群架构如下
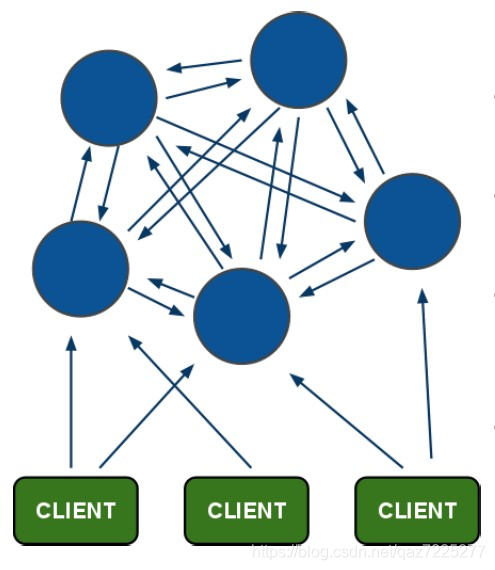
如图所示,体现以下方面
- 所有的Redis节点互联,内部使用二进制协议优化传输速度和宽带
- 节点的Fail是通过集群中超过半数的节点监测失效时才生效
- 客户端与Redis节点直连,不需要中间Proxy代理,客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
- 集群把所有物理节点映射到(0-16383)插槽上,集群负责维护 (节点-插槽-值)关系
集群描述
针对以上单个复制集存在问题,此时可多个复制集进行集群,形成水平扩展,每个复制集只存储整个复制集一分部数据
Redis分片:将数据拆分到多个Redis实例过程,这样每个Redis只包含实例的一部分完整数据
针对Redis3.0之前的版本,依靠客户端分片来完成集群,之后Redis支持集群模式,还提供网络分区后的访问性和支撑对主数据库的故障恢复
使用集群后,只能使用默认的0号数据库
分片方式如下
- 跟业务有关系:按照范围分片:如 时间、数据条数、编码等
- 跟业务无关系:一致性hash
分片的缺点
- 数据备份麻烦、聚集需要多个实例和主机持久化文件
- 不好扩容
- 不支持涉及多建操作,如果操作指令分在不同节点存在问题
- 故障恢复处理比较棘手
Redis3.0 集群优势
- 将数据自动切分到多个节点的能力
- 当集群中的一部分节点失效或者无法进行通讯时, 仍然可以继续处理命令请求的能力
总结:
Redis建议使用hash结构存储数据、数据传输、同步更高效、高可用方案优先级别如下:
1.单节点 父子级复制
2.多节点,垂直数据拆分并父子级复制,加上哨兵监控
3.分布式集群
作者简介:张程 技术研究
更多文章请关注微信公众号:zachary分解狮 (frankly0423)
