一、SMO(序列最小最优化)优化两个变量
以非线性支持向量机的对偶问题为例,使用SMO算法求解该对偶问题的最优参数α* 。
非线性支持向量机的对偶问题如下:

对偶问题转换:(如何转换请看这篇博客)

存在最优解(w*,b* ,ξ*, α* ,μ*)使得w*,b* ,ξ* 是原始问题的最优解且 α* 是对偶问题的最优解的充要条件是(w*,b* ,ξ*, α* ,μ*)满足KKT条件。
KKT条件如下:

上述的KKT条件太过分散,很难看出关联,所以先对KKT条件进行化简:
首先令g(xi) =w·xi+b ,
当αi = 0时,ui=C(C不等于0),由A和C知yi(w·xi+b)-1+ ξi >=0。因为ui不等于0,由B知ξi=0,所以yi(w·xi+b)-1>=0即yi(w·xi+b) >= 1即 yig(xi) >= 1。
当0 < αi < C 时, ui = C - αi > 0,由A和C知yi(w·xi+b)-1+ ξi =0。因为ui不等于0,由B知ξi=0,所以yi(w·xi+b)-1 =0即yi(w·xi+b) = 1即 yig(xi) = 1。
当 αi = C时,难受想哭,没想出来,直接上结论, yig(xi) <= 1。
化简后的KKT条件如下:
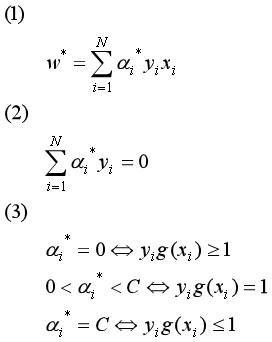
直接求出最优的参数α(α1,α2, …, αN)是很难的,SMO算法的思想是每次只优化α的两个分量,最终使得α的所有分量都满足KKT条件。
SMO算法从这里开始
1.1 SMO优化选中的两个变量
现在开始讲如何优化参数α中被选中的两个分量,首先列出对偶问题及其KKT条件。
对偶问题:
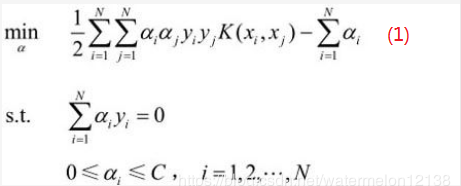
KKT条件:
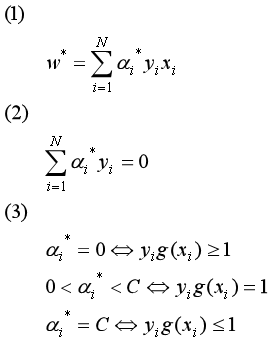
初始化α(α1,α2, …, αN) = (0,0,…,0),假设SMO算法选中的两个分量是α1和α2,如何来选这两个分量后一节会讲,将α1,α2原来的值称为α1old和α2old,那么现在要来求新的值α1new和α2new ,相当于更新优化了α1和α2。其它分量(α3,α4, …, αN)相当于是固定的(已知的),那么(1)式转换成只含变量α1和α2的(2)式如下:

其中Kij = K(xi, xj),表示核函数,ζ为常数。
###################################
(#号之内的内容是个小插曲,可以暂时跳过,后面回过头再来看)
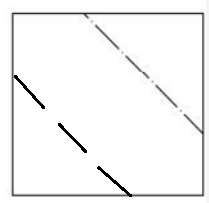
先来确定一下α1或α2的取值范围,这确定α2的取值范围,因为0<=α1<=C,0<=α2<=C,α1y1 + α2y2 = ζ,所以α1和α2肯定位于[0, C]的矩形框内且位于直线α1y1 + α2y2 = ζ上。
当y1和y2异号时,α1y1 + α2y2 = ζ 等价于 α1 - α2 = |ζ|,假设ζ >0 可得下图:

Line1的两个端点坐标分别是(0, ζ)和(C-ζ,C),α1 - α2 = -ζ,所以两个端点坐标等价于(0, α2 - α1 )和(C - α2 + α1,C )。
Line2的两个端点坐标分别是(ζ,0)和(C,C-ζ),α1 - α2 = ζ,所以两个端点坐标等价于(α1 - α2,0)和(C ,C + α2 - α1 )。
坐标转换后得如下图:

α2的取值范围要么是Line1上的[ α2 - α1,C],要么是Line2上的[0,C + α2 - α1],现在想将α2的取值范围变成 L<=α2<=H这种形式,那么怎么来做呢?
令L = max( 0,α2 - α1),H= min(C,C + α2 - α1),当L=0时,说明α2 - α1 < 0,所以 C + α2 - α1 < C,所以H = C + α2 - α1,则L<=α2<=H表示 α2位于Line2上,它的取值范围是 0<=α2<=C + α2 - α1;当L=α2 - α1时,说明α2 - α1 > 0,所以 C + α2 - α1 > C,所以H = C,则L<=α2<=H表示 α2位于Line1上,它的取值范围是 α2 - α1<=α2<=C。
所以当y1和y2异号时,L = max( 0,α2 - α1),H= min(C,C + α2 - α1),用 L<=α2<=H 就能表示α2的取值范围。
同理当y1和y2同号时,α2位于下图中的某条直线上,这里不再赘述,直接上结论。L= max(0, α2 + α1 - C),H = (C,α2 + α1),用 L<=α2<=H 就能表示α2的取值范围。
###################################
记g(xi) =w·xi+b,由KKT条件(1)可得:
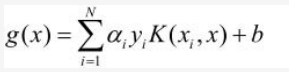
记Ei = g(xi) - yi,表示预测值与真实值之差,如下:
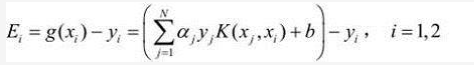
记vi 如下:
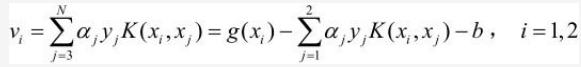
通过vi只含 α1 , α2两个变量的式(2)变成式(3)如下:
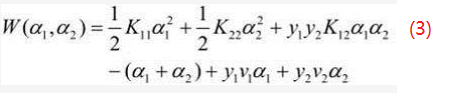
因为α1y1 + α2y2 = ζ,yi2 = 1,所以α1 = (ζ - α2y2)y1,将该式带入式(3)中就得到了只含α2一个变量的式(4),如下:
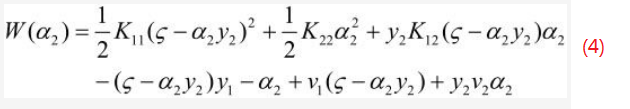
然后式(4)对α2求导并令其等于0就可以解出α2new,unc :

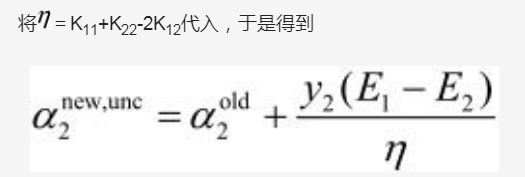
之所以称它为α2new,unc ,是因为α2new,unc不一定符合α2的取值范围,如何来求α2的取值范围请看上文用#号括起来的内容,将α2new,unc转换成最终的α2new,具体操作过程如下:
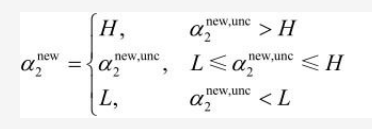
上式就确保了α2更新后的值α2new 符合α2的取值范围。
因为α1和α2满足以下约束:
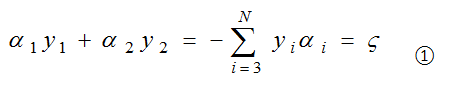
更新优化α1和α2后得到α1new和α2new ,因为(α3,α4,…,αN)没有变动,所以α1new和α2new 依然满足上述约束:
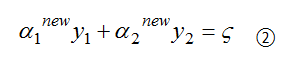
上面两个约束相减,可得:
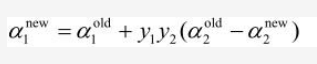
到此为止被选中的α1和α2优化结束。
1.2 SMO计算阈值bnew和差值Ei
因为α1和α2已经优化结束,当然要更新α1和α2对应的E1和E2,求bnew就是为了求E1和E2。
当0<α1new <C时,由KKT条件(3)可得:y1g(x1)=1,也就是g(x1)=y1,即
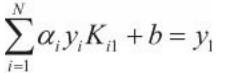
于是:
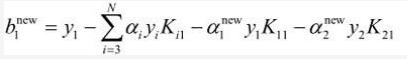
E1 = g(x1) - y1,即:
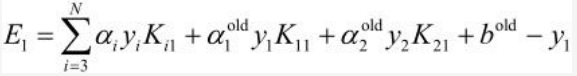
b1new等式的前两项可以写为:
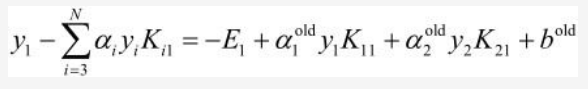
所以b1new最终等于:
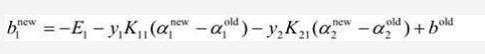
同理如果0<α2new <C,则:
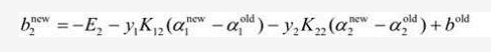
更新b的规则如下:
如果0<α1new <C,则bnew = b1new;如果0<α2new <C,则bnew = b2new;如果都不满足则bnew = (b1new + b2new)/2
其实更新b不是最终目的,我们的最终目的是更新Ei:
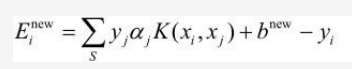
其中S是所有支持向量xj的集合。
二、SMO算法变量的选择
2.1 第一个变量的选择
SMO算法称选择第一个变量为外层循环,这个变量需要选择在训练集中违反KKT条件最严重的样本点。对于每个样本点,要满足的KKT条件我们在上面已经讲到了:
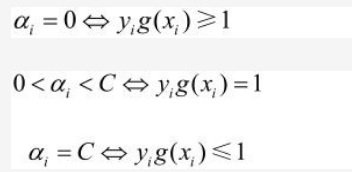
一般来说,我们首先选择违反0<αi<C⇒ yig(xi)=1这个条件的最严重的点,比如0<αi<C对应的点是(xi, yi),yig(xi)远远大于1或远远小于1,所以点(xi, yi)就是违反0<αi<C⇒ yig(xi)=1这个条件的最严重的点。如果0<αi<C对应的点都满足KKT条件,再选择违反αi=0⇒yig(xi)≥1 和 αi=C⇒yig(xi)≤1的点。
2.2 第二个变量的选择
SMO算法称选择第二个变量为内层循环,假设我们在外层循环已经找到了α1, 第二个变量α2的选择标准是让|E1−E2|有足够大的变化。由于α1定了的时候,E1也确定了,所以要想|E1−E2|最大,只需要在E1为正时,选择最小的Ei作为E2, 在E1为负时,选择最大的Ei作为E2,可以将所有的Ei保存下来加快迭代。
如果内存循环找到的点不能让目标函数有足够的下降, 可以采用遍历支持向量点来作为α2,直到目标函数有足够的下降, 如果所有的支持向量作α2都不能让目标函数有足够的下降,可以跳出循环,重新选择α1。(支持向量点是位于分界间隔上的点或位于间隔之内的点或分错的点)
三、SMO算法总结
输入是m个样本(x1,y1),(x2,y2),…,(xm,ym),其中x为n维特征向量,y为二元输出,值为1或者-1,精度为e。
输出是近似解α
1)取初始值α0 = 0,k=0
2)按照2.1节的方法选择α1k ,按照2.2节的方法选择α2k ,求出新的α2new,unc。
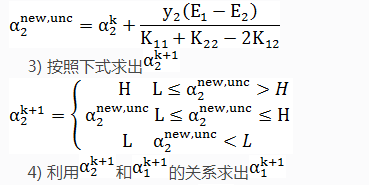
5)按照1.2节的方法计算bk+1 和Ei。
