中断服务程序接收报文后都交由__netif_receive_skb处理:根据协议将报文向上传输;
packet_type 结构为网络层输入接口;其支持多种协议,每个协议族都会实现一个接收报文的的实例;此结构在链路层和网络层之间起到了桥梁的作用。


struct packet_type { __be16 type; /* This is really htons(ether_type). */ struct net_device *dev; /* NULL is wildcarded here */ int (*func) (struct sk_buff *, struct net_device *, struct packet_type *, struct net_device *); bool (*id_match)(struct packet_type *ptype, struct sock *sk); void *af_packet_priv; struct list_head list; };
其中type为以太网或者其他链路层承载的网络层协议号,dev接收指定的网络设备输入报文,为NULL 表接收所有设备的报文;
int (*func) (struct sk_buff *, struct net_device *, struct packet_type *,struct net_device *);为协议入口的接收函数;第二个参数当前处理该报文的网络设备,第四个参数为报文的原始输入网络设备
note:一般处理报文的设备和报文的原始接收设备是一个,但是在聚合口情况下:输入设备为物理设备,实际处理报文的为虚拟网络设备。
static struct packet_type ip_packet_type __read_mostly = { .type = cpu_to_be16(ETH_P_IP), .func = ip_rcv, };
static int __init inet_init(void) { ......................... dev_add_pack(&ip_packet_type); .............. } /******************************************************************************* Protocol management and registration routines *******************************************************************************/ /* * Add a protocol ID to the list. Now that the input handler is * smarter we can dispense with all the messy stuff that used to be * here. * * BEWARE!!! Protocol handlers, mangling input packets, * MUST BE last in hash buckets and checking protocol handlers * MUST start from promiscuous ptype_all chain in net_bh. * It is true now, do not change it. * Explanation follows: if protocol handler, mangling packet, will * be the first on list, it is not able to sense, that packet * is cloned and should be copied-on-write, so that it will * change it and subsequent readers will get broken packet. * --ANK (980803) */ static inline struct list_head *ptype_head(const struct packet_type *pt) { if (pt->type == htons(ETH_P_ALL)) return pt->dev ? &pt->dev->ptype_all : &ptype_all; else return pt->dev ? &pt->dev->ptype_specific : &ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK]; } /** * dev_add_pack - add packet handler * @pt: packet type declaration * * Add a protocol handler to the networking stack. The passed &packet_type * is linked into kernel lists and may not be freed until it has been * removed from the kernel lists. * * This call does not sleep therefore it can not * guarantee all CPU's that are in middle of receiving packets * will see the new packet type (until the next received packet). */ void dev_add_pack(struct packet_type *pt) { struct list_head *head = ptype_head(pt); spin_lock(&ptype_lock); list_add_rcu(&pt->list, head); spin_unlock(&ptype_lock); }
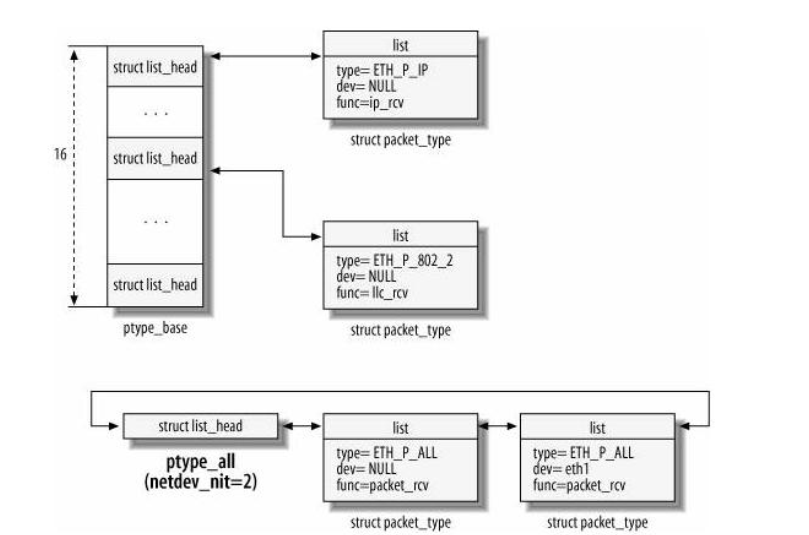
/* * The list of packet types we will receive (as opposed to discard) * and the routines to invoke. * * Why 16. Because with 16 the only overlap we get on a hash of the * low nibble of the protocol value is RARP/SNAP/X.25. * * NOTE: That is no longer true with the addition of VLAN tags. Not * sure which should go first, but I bet it won't make much * difference if we are running VLANs. The good news is that * this protocol won't be in the list unless compiled in, so * the average user (w/out VLANs) will not be adversely affected. * --BLG * * 0800 IP * 8100 802.1Q VLAN * 0001 802.3 * 0002 AX.25 * 0004 802.2 * 8035 RARP * 0005 SNAP * 0805 X.25 * 0806 ARP * 8137 IPX * 0009 Localtalk * 86DD IPv6 */ #define PTYPE_HASH_SIZE (16) #define PTYPE_HASH_MASK (PTYPE_HASH_SIZE - 1)
dev_add_pack()是将一个 协议类型结构链入某一个链表, 当协议类型为ETH_P_ALL 时,它将被链入 ptype_all 链表,这个链表是用于 sniffer 这样一些程序的,它接收所有 NIC 收到的包。还有一个是 HASH 链表 ptype_base,用于各种协议,它是一个 PTYPE_HASH_SIZE 个元素的数组, dev_add_pack()会根据协议类型将这个 packet_type 链入相应的 HASH 链表中
2、__netif_receive_skb_core 分析
static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc) { struct packet_type *ptype, *pt_prev; rx_handler_func_t *rx_handler; struct net_device *orig_dev; bool deliver_exact = false; int ret = NET_RX_DROP; __be16 type; net_timestamp_check(!netdev_tstamp_prequeue, skb); trace_netif_receive_skb(skb); orig_dev = skb->dev; skb_reset_network_header(skb); if (!skb_transport_header_was_set(skb)) skb_reset_transport_header(skb); skb_reset_mac_len(skb); pt_prev = NULL; another_round: skb->skb_iif = skb->dev->ifindex; __this_cpu_inc(softnet_data.processed);/* 增加本cpu处理过的数据包个数 */ /*解析8021 q 协议*/ if (skb->protocol == cpu_to_be16(ETH_P_8021Q) || skb->protocol == cpu_to_be16(ETH_P_8021AD)) { skb = skb_vlan_untag(skb); if (unlikely(!skb)) goto out; } /* 入口流量控制 */ #ifdef CONFIG_NET_CLS_ACT if (skb->tc_verd & TC_NCLS) { skb->tc_verd = CLR_TC_NCLS(skb->tc_verd); goto ncls; } #endif if (pfmemalloc) goto skip_taps; /* po->prot_hook.func = packet_rcv; if (sock->type == SOCK_PACKET) po->prot_hook.func = packet_rcv_spkt; */ //在net_dev_init中初始化 /*注意这里并没有要求ptype->type == type,所以接收到的包只要有注册ETH_P_ALL协议 ,所有的包都会走到deliver_skb 遍历嗅探器(ETH_P_ALL)链表ptype_all。对于每个注册的sniffer, * 调用它的处理函数packet_type->func(),例如tcpdump。 */ list_for_each_entry_rcu(ptype, &ptype_all, list) { if (pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } /* //设备上注册ptype_all,做相应的处理,更加精细的控制 **/ list_for_each_entry_rcu(ptype, &skb->dev->ptype_all, list) { if (pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } skip_taps: #ifdef CONFIG_NET_INGRESS if (static_key_false(&ingress_needed)) { skb = sch_handle_ingress(skb, &pt_prev, &ret, orig_dev); if (!skb) goto out; if (nf_ingress(skb, &pt_prev, &ret, orig_dev) < 0) goto out; } #endif #ifdef CONFIG_NET_CLS_ACT skb->tc_verd = 0; ncls: #endif if (pfmemalloc && !skb_pfmemalloc_protocol(skb)) goto drop; /*处理8021q**/ if (skb_vlan_tag_present(skb)) { if (pt_prev) { ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = NULL; } if (vlan_do_receive(&skb)) goto another_round; else if (unlikely(!skb)) goto out; } /*内核提供了netdev_rx_handler_register接口函数向接口注册rx_handler 比如为网桥下的接口注册br_handle_frame函数 为bonding接口注册bond_handle_frame函数 网桥的处理包括向上层提交和转发 发往本地的报文会修改入接口为网桥虚接口如br0 调用netif_receive_skb重新进入协议栈处理 对于上层协议栈见到的只有桥虚接口 需要转发的报文根据转发表进行单播或广播发送 */ //设备rx_handler,加入OVS时会注册为OVS的入口函数?? rx_handler = rcu_dereference(skb->dev->rx_handler); if (rx_handler) {//执行rx_handler处理,例如进入OVS,OVS不支持报头中携带vlan的报文?? if (pt_prev) { ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = NULL; } switch (rx_handler(&skb)) { case RX_HANDLER_CONSUMED: ret = NET_RX_SUCCESS;//数据包已成功接收,不需要再处理 goto out; case RX_HANDLER_ANOTHER://当rx_handler改变过skb->dev时,在接收回路中再一次处理。 goto another_round; case RX_HANDLER_EXACT://不使用匹配的方式,精确传递。 deliver_exact = true; case RX_HANDLER_PASS://忽略rx_handler的影响。 break; default: BUG(); } } if (unlikely(skb_vlan_tag_present(skb))) { if (skb_vlan_tag_get_id(skb)) skb->pkt_type = PACKET_OTHERHOST; /* Note: we might in the future use prio bits * and set skb->priority like in vlan_do_receive() * For the time being, just ignore Priority Code Point */ skb->vlan_tci = 0; } /* 最后 type = skb->protocol; &ptype_base[ntohs(type)&15] //处理ptype_base[ntohs(type)&15]上的所有的 packet_type->func() //根据第二层不同协议来进入不同的钩子函数,重要的有:ip_rcv() arp_rcv() ip_recv见inet_init里面的dev_add_pack(&ip_packet_type); */ type = skb->protocol; //skb->protocol用来表示此SKB包含的数据所支持的L3层协议是什么. 如ox0800代表IP,0x0806代表ARP 在驱动程序中已经获取了该值 /* deliver only exact match when indicated */ if (likely(!deliver_exact)) {//根据全局定义的协议处理报文??//如果前面判段是精确发送方式,那么把nulll_or_dev设置成精确传送的设备 deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, &ptype_base[ntohs(type) & PTYPE_HASH_MASK]); } deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, &orig_dev->ptype_specific);?//根据设备上注册的协议进行处理?? if (unlikely(skb->dev != orig_dev)) {//如果设备发生变化,那么还需要针对新设备的注册协议进行处理?? deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, &skb->dev->ptype_specific); } /***' 1、vlan报文的处理,主要是循环把vlan头剥掉,如果qinqxxxxx场景,两个vlan都会被剥掉; 2、交给rx_handler处理,例如OVS、linux bridge等; 3、ptype_all处理,例如抓包程序、raw socket等; 4、ptype_base处理,交给协议栈处理,例如ip、arp、rarp等; */ if (pt_prev) { if (unlikely(skb_orphan_frags(skb, GFP_ATOMIC))) goto drop; else ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev);?//调用协议处理ip_rcv() arp_rcv() } else { drop: if (!deliver_exact) atomic_long_inc(&skb->dev->rx_dropped); else atomic_long_inc(&skb->dev->rx_nohandler); kfree_skb(skb); /* Jamal, now you will not able to escape explaining * me how you were going to use this. :-) */ ret = NET_RX_DROP; } /** 内核提供了netdev_rx_handler_register接口函数向接口注册rx_handler 比如为网桥下的接口注册br_handle_frame函数 为bonding接口注册bond_handle_frame函数 这相对于老式的网桥处理更灵活 有了这个机制也可以在模块中自行注册处理函数 ? 网桥的处理包括向上层提交和转发 发往本地的报文会修改入接口为网桥虚接口如br0 调用netif_receive_skb重新进入协议栈处理 对于上层协议栈见到的只有桥虚接口 需要转发的报文根据转发表进行单播或广播发送 netfilter在网桥的处理路径中从br_handle_frame到br_dev_queue_push_xmit设置了5个hook点 根据nf_call_iptables的配置还会经过NFPROTO_IPV4的hook点等 内核注册的由br_nf_ops数组中定义 可在模块中自行向NFPROTO_BRIDGE族的几个hook点注册函数 ebtables在netfilter框架NFPROTO_BRIDGE中实现了桥二层过滤机制 配合应用程序ebtables可在桥下自定义相关规则 ? 处理完接口上的rx_handler后便根据具体的3层协议类型在ptype_base中寻找处理函数 比如ETH_P_IP则调用ip_rcv,ETH_P_IPV6则调用ipv6_rcv 这些函数都由dev_add_pack注册 可在模块中自定义协议类型处理函数 如果重复定义相同协议的处理函数则要注意报文的修改对后续流程的影响 ? IP报文进入ip_rcv后进行简单的检查便进入路由选择 根据路由查找结果调用ip_local_deliver向上层提交或调用ip_forward进行转发 向上层提交前会进行IP分片的重组 在ip_local_deliver_finish中会根据报文中4层协议类型调用对应的处理函数 处理函数由接口函数inet_add_protocol注册 针对TCP或UDP进行不同处理,最后唤醒应用程序接收数据 向外发送和转发数据经由ip_output函数 包括IP的分片,ARP学习,MAC地址的修改或填充等 netfilter在从ip_rcv到ip_output间设置了5个hook点 向各个点的链表中注册处理函数或使用iptables工具自定义规则 实现报文处理的行为控制 */ out: return ret; }
net/core/dev.c static inline int deliver_skb(struct sk_buff *skb, struct packet_type *pt_prev, struct net_device *orig_dev) { //在接收端要将分片的数据包重组,这里判断是否因缺少分片包而导致一个skb成为一个孤儿skb。显然是不太可能是孤儿进 //程的,所以这里使用了unlikely知道gcc编译器优化程序,以减少指令流水被打断的概率。 if (unlikely(skb_orphan_frags(skb, GFP_ATOMIC))) return -ENOMEM; atomic_inc(&skb->users); //增加skb的使用者计数器 return pt_prev->func(skb, skb->dev, pt_prev, orig_dev); }