DEMO
查看hashmap的源码我们先找到一个入口,就以其调用方法的DEMO作为入口,如下:

增、改 put()
进入第一个put()方法,我们看到它首先把KEY做了一个hash计算,获取了KEY的hashcode,然后调用了putVal()这个内部方法。
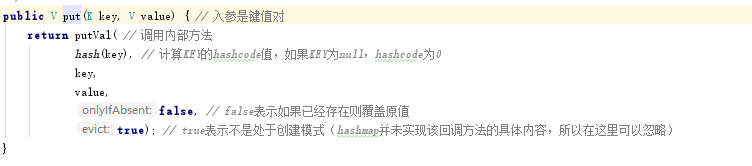
我们先点开hash(key)看看hash计算

一个简单的三元表达式,如果是KEY是null的话直接返回0,否则调用native方法获取hashcode并做了一些偏移计算。总之这里计算出了一个值,这个值也就是后面用到的索引。
接下来进入putVal()方法,方法比较长,主要有以下几步:
1、判断hash表容量,如果不存在或者容量为0,则进行一次扩容;
2、根据hash计算的索引,找到hash表中对应的首个节点,如果首个节点都没有那么直接创建一个节点即可。
3、既然首个节点不为空,那么判断首个节点是否跟待插入的KEY相等,如果相等直接修改该节点即可
4、如果首个不相等,那么看看首个是不是红黑树,如果是交给红黑树去处理
5、如果也不是红黑树,也就是普通的链表,找到KEY相等的节点修改值,或者最后一个节点还不是那么新增一个节点作为最后一个节点

红黑树相关代码较长,这里不展开红黑树附加的内容
查 get()、containsKey()
接下来进入get()方法
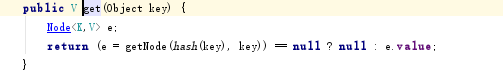
我们看到,实际上get方法就是根据hash拿到对应的node节点,如果节点不存在则为null
进入getNode方法,getNode的步骤大体如下:
1、判断hash表是否存在,容量是否大于0,并拿到第一个节点
2、如果首个节点就是查找的节点直接返回
3、既然不是,那么先判断是否是红黑树,如果是交给红黑树处理
4、如果是普通链表,只好遍历链表了,都查不着的话就返回null
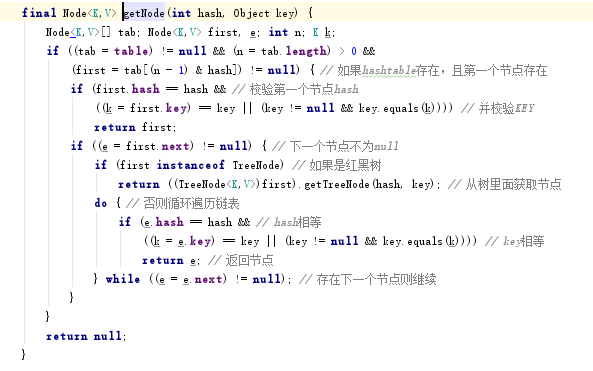
下面再点击进入containsKey方法看看,很显然它跟GET的区别在于是否取node当中的值罢了

移除remove()
再点击进入最后一个remove方法瞅瞅,这里跟前面大同小异了,计算hash,调用removeNode方法

所以我们进入removeNode方法,大体代码如下:
1、判断hash表,并获取hash索引对应的首个节点
2、判断首个节点是否目标节点
3、如果不是,再判断首个节点是否红黑树,如果是交给红黑树处理,否则只好遍历链表了
4、如果存在目标节点,那么就删除该节点(删除这里,如果目标节点是红黑树的节点交给红黑树处理,否则修改链表的指针即可)

总结
由hashmap的增删改查方法的实现我们可以了解到它实际上跟表示的含义一样是使用hash表来实现的,如果落在相同hash槽那么就采用链表或者红黑树来解决hash冲突问题(红黑树是JDK在1.8新增的)。
另外hashmap没有采用任何线程安全相关机制来处理,因此它不是线程安全的,这也是跟以往的hashtable最大的区别(hashtable采用synchronized来控制并发)。